
[OSDI'20] From WiscKey to Bourbon: A Learned Index for Log-Structured Merge Trees
本文首次将学习索引应用到了LSM-tree之中,基于Whiskey Key-Value分离存储的开创性工作,使得对LSM-tree建立学习索引成为可能(定长SSTable entry)。文章通过详细的实验分析说明了学习索引加速LSM-tree Lookup的性能提升,并指出在未来高性能SSD/存储设备上学习索引能带来更大的收益。
下图即为Bourbon (´・Д・)」

0x00 Background
LSM-tree && LevelDB
LSM-tree是在KV存储中常用的数据结构,采用多级的查找结构,将随机写转换成顺序写入
LevelDB则是使用LSM-tree的KV数据库引擎
具有2个in-memory tables,7-levels 盘上SSTable
更新和插入操作会写入到MemTable的buffer中
当每个层级full之后会发生Compaction,将数据合并到下一个层级
因此对于SSTable而言,不会发生就地更新
对于查找操作,将从上向下遍历所有的层级,直到Key存在
由于硬盘上的SSTable不会在写入操作时更新,因此不需要频繁的更新模型(保证模型的准确度)
引入学习索引需要关注几个问题:
- SSTable的Lifetime:模型可以使用的时间
- SSTable查询操作的数量:模型的使用频率
LSM-tree的查找过程:
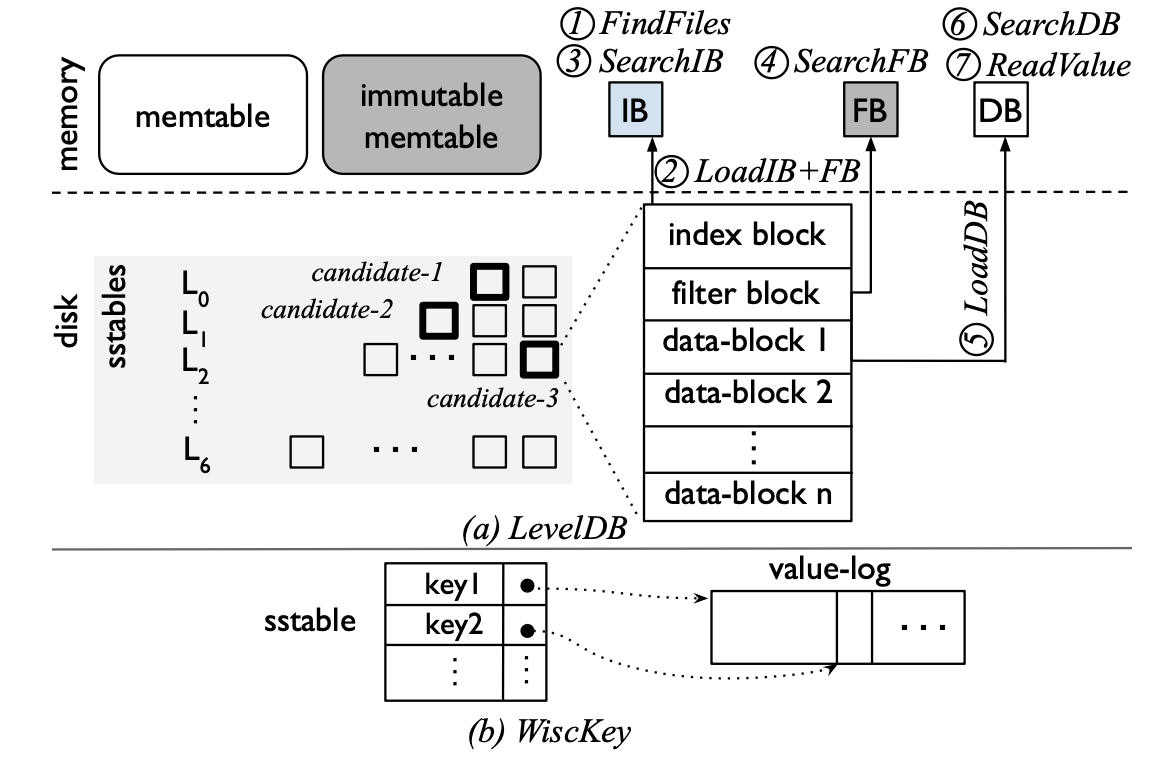
- FindFiles:MemTable中没有找到所需Key时,找到可能包含Key的SSTable文件
- LoadIB+FB:在候选的SSTable中,加载其Index-Block和bloom-filter Block
- SearchIB:在Index-Block中进行二分查找,找到可能包含Key的data block
- SearchFB:读取Filter Block通过Bloom-filter检查Key是否存在
- LoadDB:如果查找bloom-filter发现Key存在,将加载相应的data block
- SearchDB:在data block中进行二分查找
- ReadValue:读取Key所对应的Value
上述步骤中每次没有命中都会直接去查找下一个候选的SSTable文件
整个过程分为两类操作:
- 索引操作(查找Key):Find Files,Search IB,Search FB,Search DB
- 数据访问操作:LoadIB+FB,LoadDB,Read Value
作者使用学习索引优化的即索引操作
Wisckey
LevelDB中Compaction操作带来了写放大write amplification,因此Wisckey提出一些思路来进行优化:
- Key-Value分离存储,Compaction操作只处理Key,降低了内部的数据处理开销(后台IO),采用Key- Position-Data的查找方式,一次查询需要两次I/O(索引、数据)
下图展示了LevelDB如何组织数据并处理查找操作,以及展示了Wisckey的KV分离存储模式
Wisckey的查找流程和传统LSM-tree相同,分离出来的数据部分保存于value-log,由于LSM-tree不保存数据,Wisckey的整个SSTable可以保存在Memory中,加速了查找的过程,最后仅需要一次on-disk access
Learned Index
对于LSM-tree、B-tree等数据结构在索引上的开销巨大,通过建立线性映射的函数(线性回归模型)可以显著优化查询操作索引的开销为O1。
对于插入请求,将改变数据布局,需要对模型进行重训练。
Bourbon将学习索引应用到了LSM-tree中,WiscKey KV
可以优化写操作
LSM-Tree SSTable没有就地更新
需要解决如何/何时建立SSTable的索引模型
由于模型可能出错,因此索引模型会设置error bound
对于预测结果pos,如果预测出错将会在$(pos-\delta_{min},pos+\delta_{max})$范围内重新进行查找
Related Work
0x01 Motivation
Learned Index 带来的收益
学习索引只能优化前文提到的LSM-tree索引操作,并不能优化on-disk/memory数据的访问。
作者对Wisckey LSM-tree查找操作进行了breakdown分析,对于数据全缓存于Memory中的情景,数据的访问不再是瓶颈,索引所占的开销超过了50%。当数据保存于硬盘时,随着存储设备的性能越来越好(SATA、NVMe、Optane 3DXpoint),数据访问的延迟占比越来越小,索引在整个延迟中的占比逐渐升高,(indexing cost)在SATA达到了17%,Optane达到了44%。

因此,作者得出结论:不管是对于全缓存还是on-disk的场景,学习索引都能加速查找的性能,并且性能越好的存储设备提升越大。
Learned Index with Writes
对于write/update操作,会改变数据的分布,因此需要学习索引模型进行重训练,对于写多的负载重训练将产生巨大的开销。
LSM-tree设计之初就是为了优化写入操作,这和学习索引看起来并不match。
作者设计实验评估了不同层级SSTable的lifetime(从file creation到deletion),有三个发现:
- lower level的平均lifetime比higher level更高
- 在写入比例较低时,higher level SSTable L0的也能存在较长的时间(2min),L4可以存在150minutes
- 在写入比例较高时,lower level SSTable L4的lifetime也能达到60minutes,L0仅有10s
综合以上发现,作者总结出5条guidelines:
- lower level的lifetime最长,不管写入负载的比例如何,lower level的lifetime都比较长,无需频繁重训练
- 重训练前等待一段时间,一些文件的lifetime较短,甚至在lower level也存在(连续的Compaction频繁创建销毁文件;Compaction后出现重叠进行文件合并),设置阈值等待文件的lifetime避免频繁重训练
- 不能忽视higher level的文件,可以加快内部查找
- workload/data-aware,不同的负载和数据有不同的访问特征。lower level可能访问不频繁,建立学习索引的收益较低;数据有序或者无序进行加载会影响查询的效率,Key有序插入时可以很容易的找到对应的文件,lower level也会处理较多的查询请求,无序插入时不同层级之间存在重叠的Key范围,提高higher level的查询开销。因此系统需要判断哪些文件应该进行学习
- 不应在write-heavy的情况下重训练整个level,由于Compaction等原因很多数据会频繁的修改,重训练成本非常高,同时读的比例较少,重训练的收益也有限
0x02 Design
Learning the Data
学习的粒度:
- 独立的SSTable File,给出key对应于SSTable的Offset
- 整个Level,给出key对应的SSTable和Offset
使用轻量化的分段线性回归模型,按照<key,offset>的数据进行学习
Greedy-PLR
Greedy Piecewise Linear Regression,分段线性回归
训练时间负载度为$O(n)$,~40ms
预测时间负载度$O(\log #segments)$,<1us
Supporting Variable-size Values
为了便于学习索引的建立,Bourbon延续了Wisckey中的设计,只支持固定长度的Key,保存数据指针,因此可以支持任意大小的Value。
Level vs. File Learning
Bourbon默认采用file粒度的学习索引,采用Level粒度仅在读占比较大的情况效果优于baseline,略优于File Model;但是在写占比较大时Level model甚至比baseline性能略差一些。主要的原因是上文提到的频繁重训练,Level粒度的更新比file变化更频繁。
针对read-only的场景,Bourbon也可以配置Level Model
Cost vs. Benefit Analyzer
开销和收益的分析。在对file进行学习之前,Bourbon需要评估学习产生的收益,也就是评估file的lifetime和收益。
设置wait time 对于4MB左右的SSTable File,学习一次产生的开销大约在40ms,设置大约50ms的wait time,在对文件进行学习时等待一段时间,防止这段时间内文件被销毁。该值设置过小会产生更大的学习开销,设置过大会降低学习索引带来的收益(执行了baseline lookup)。
是否对文件进行学习。 即使是lifetime较长的file(lower level)可能不会处理很多查找,而lifetime较短的file会在短时间内执行很多查询操作。因此需要评估学习该文件带来的收益Benefit**(对于lifetime中的N次查找,走Model相比于baseline path减少的总时间)和开销Cost(训练一个file的时间开销,avg time * nr data points)**,当收益大于开销时再进行学习。
Putting it All Together
下图展示了Bourbon的整个查找流程
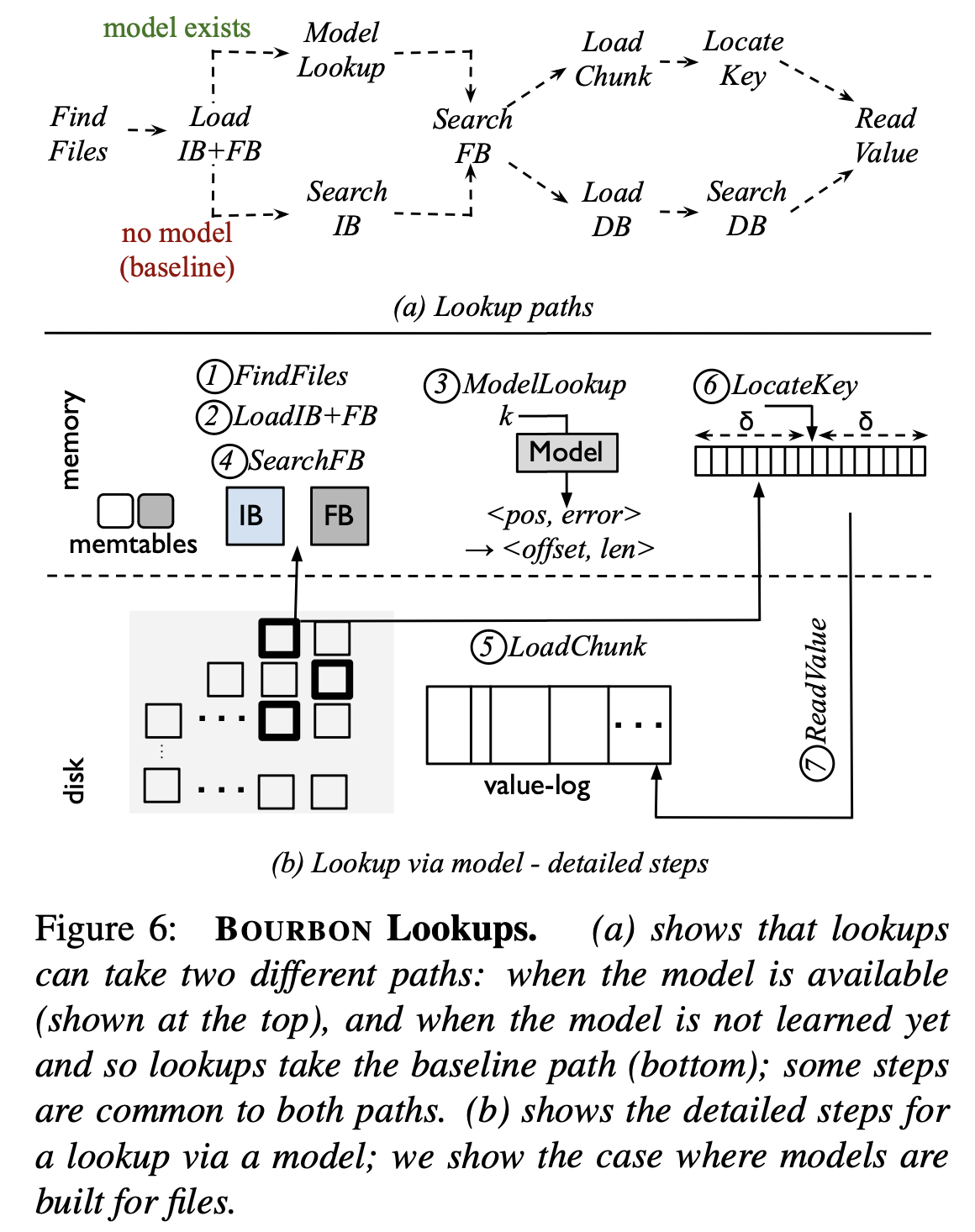
Bourbon目前存在的问题/优化方向:
- 不支持String Key和Key压缩,String Key可以转换为64位整数进行处理
- 不支持Level Model和File Model的自动切换,为静态配置
0x03 Evaluation
Bourbon采用16Byte的Key和64Byte的Value,error bound为8
作者采用以下的数据集对Bourbon的性能进行评估。
4个合成数据集:
- Linear:Key完全连续
- Segmented 1%:每1%的Key连续,之后会存在gap
- Segmented 10%:每10%的Key连续
- Normal:遵循正态分布$N(0,1)$
两个真实数据集:
- Amazon Reviews(AR)
- New York Open StreetMaps(OSM)
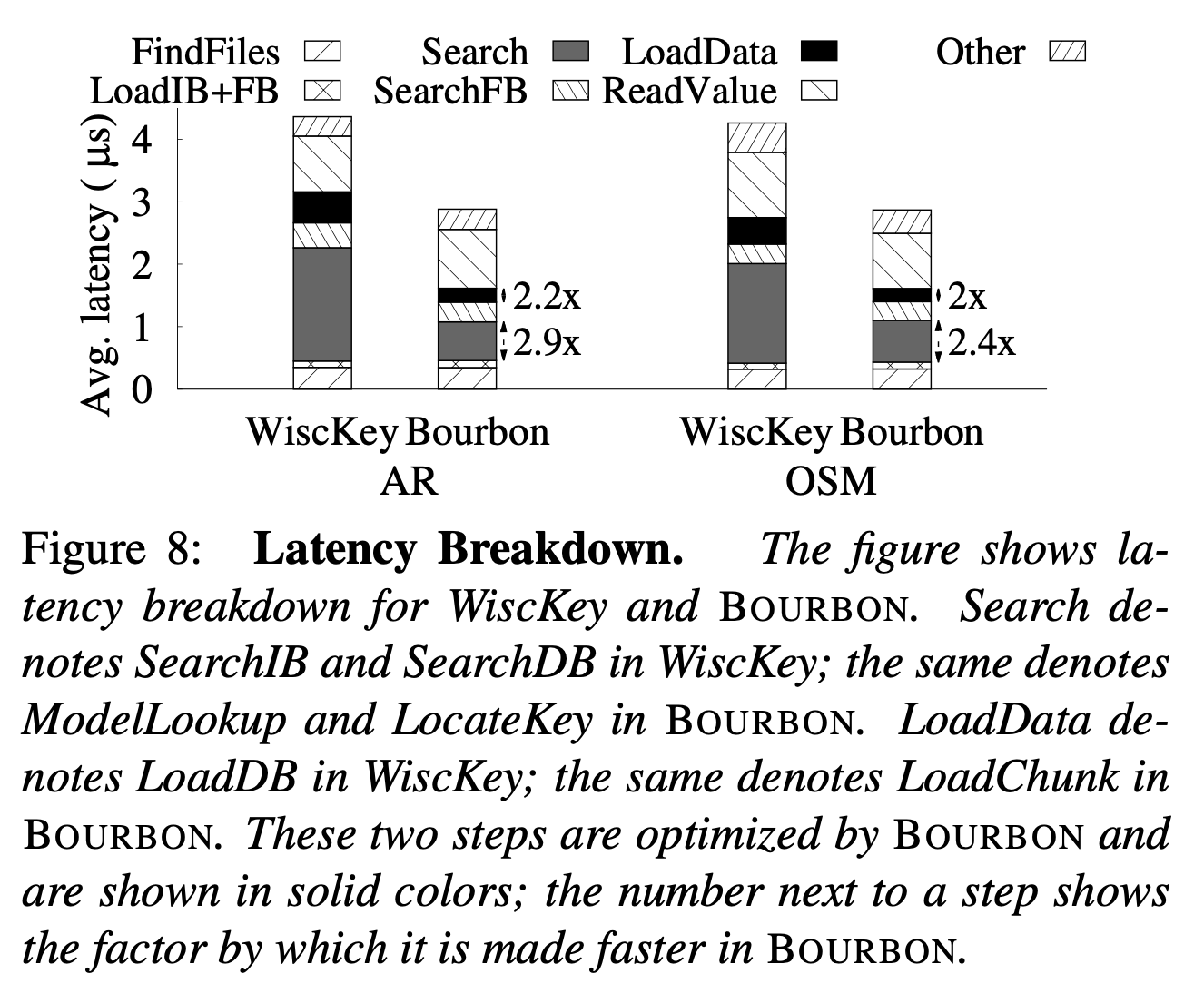
Bourbon优化了lookup流程的哪一个部分
下图的Breakdown分析可以看出,与baseline相比,Bourbon:
- 优化了Search IB+Search DB的部分
- 由于Bourbon LoadData 采用chunk粒度,也优化了数据访问开销
Bourbon的最优性能和负载特征的影响
探究Bourbon在无写入的情况下(read-only)
负载特征包括数据集、load order、请求分布
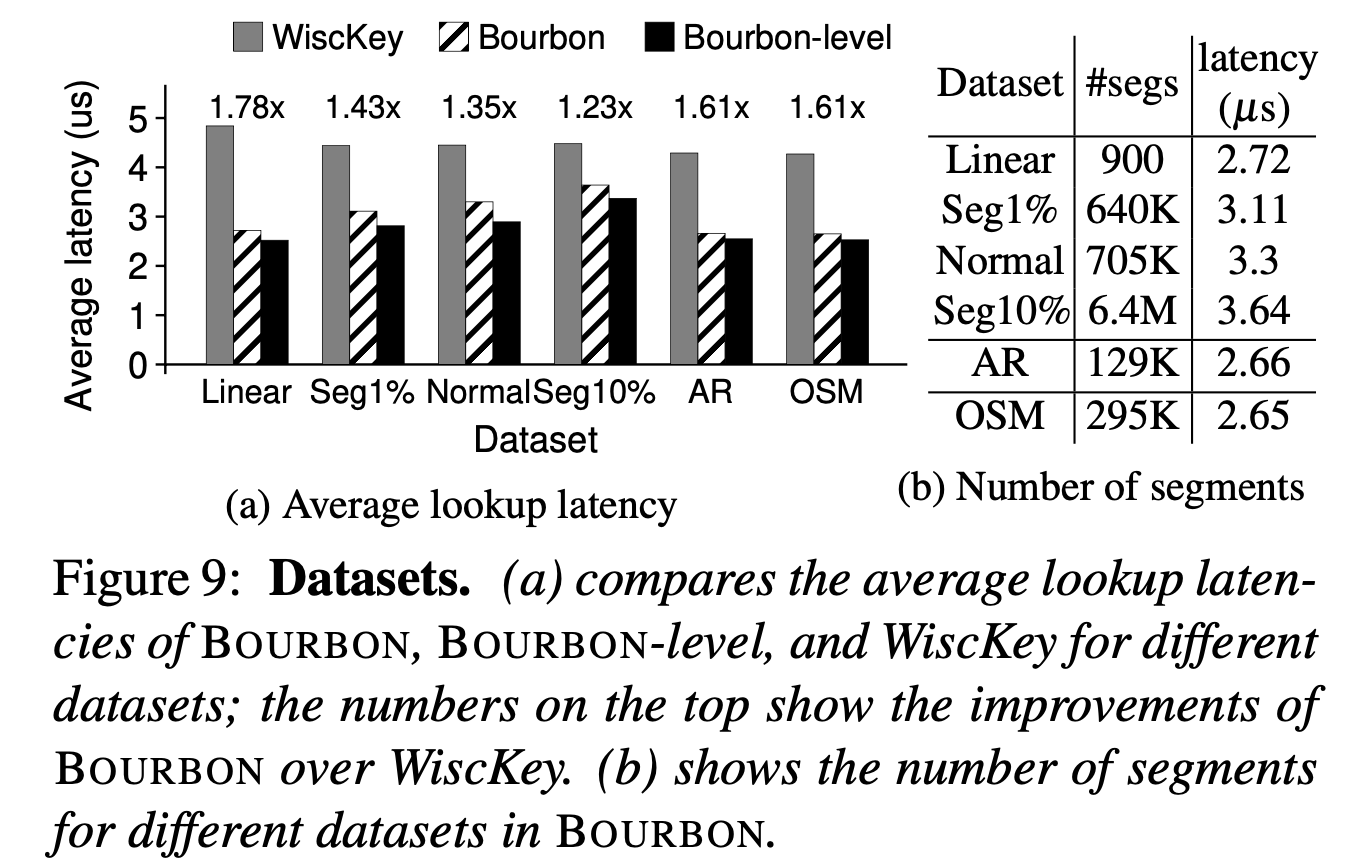
数据集。下图a为baseline、Bourbon file model和Bourbon level model的平均查找延迟,可以看出对于线性负载,学习索引的收益最大,或者说Key的连续性越强(下图table b),学习索引的收益就越大。同时在纯读read-only的场景下,level model的效果也更好。
**Load Order。**下图a可以看出,baseline和bourbon file model在不同data load order下的性能表现。
Seq为按照递增的顺序插入Key,Rand则为乱序插入Key,Key的插入会影响每个Level的命中情况(key range overlap),可能会在higher level带来更多的Negative lookup。
在Seq和Rand的场景下,Bourbon的提升都很明显,Rand下的延迟显著高于Read,主要是因为Negative lookup需要多加载一次data block(过滤器没命中),表b统计了两个数据集下Positive/Negative lookup次数,Negative lookup占比较多。

**请求分布。**下图展示了不同分布下Bourbon的查找性能,数据集均为乱序加载。Bourbon最快比baseline快1.8倍。

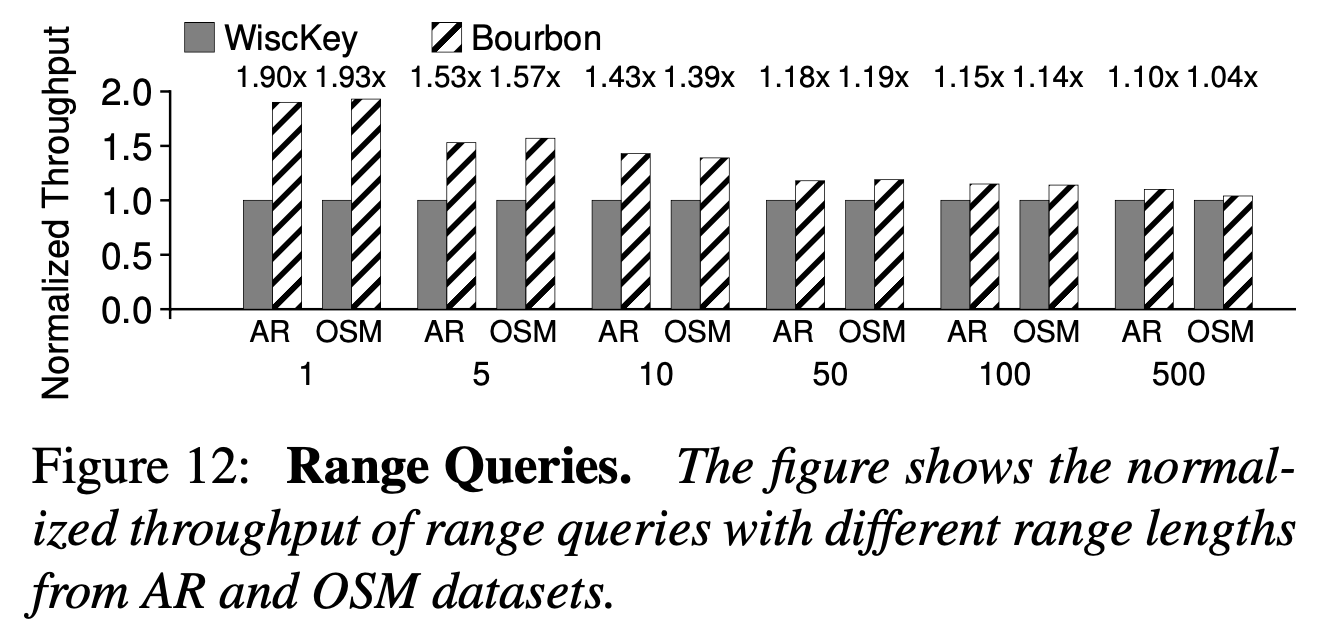
Bourbon对范围查找的处理
查找LSM-tree中一段连续的Key,下图可以看出Bourbon在处理range query时的收益不高,这是因为bourbon只加速了索引的过程,较大范围的查询索引开销的占比远低于数据的访问。
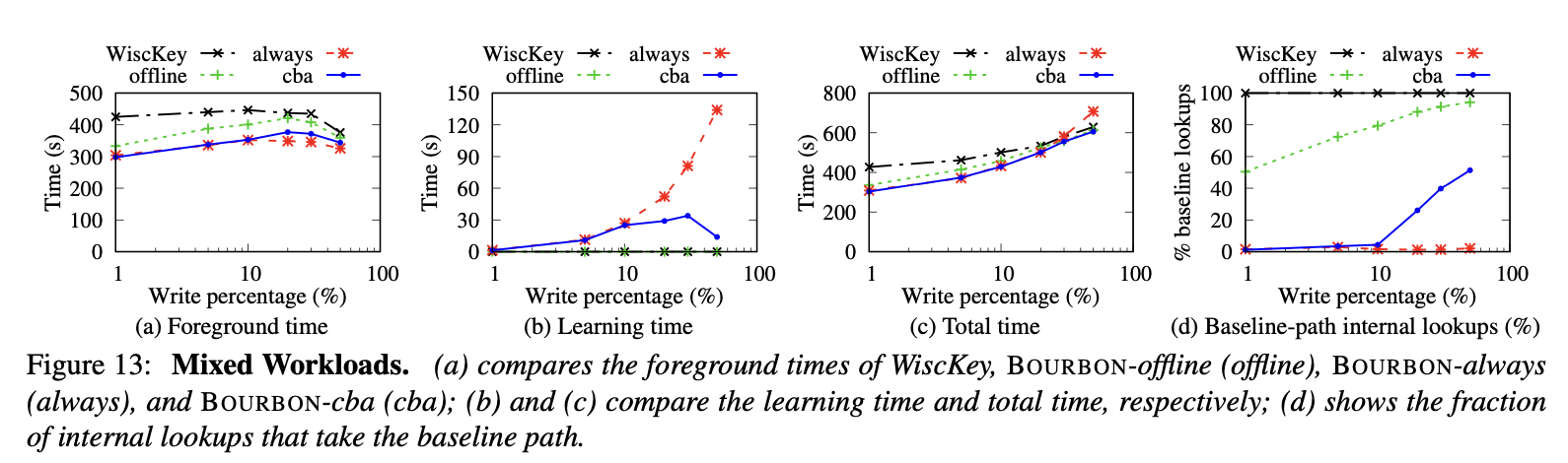
评估Cost-Benefit Analyzer和其他学习索引
下图对比了baseline和offline(只训练一次,写入后不re-learn),always(只要发生写入就re-learn),cba(采用cost-benefit analyzer)四种策略下的查找插入时间和重训练时间
结果不必多言,cba和always的foreground(查找时间)相近,但是cba的re-learn开销在write- heavy的情况下显著由于always。
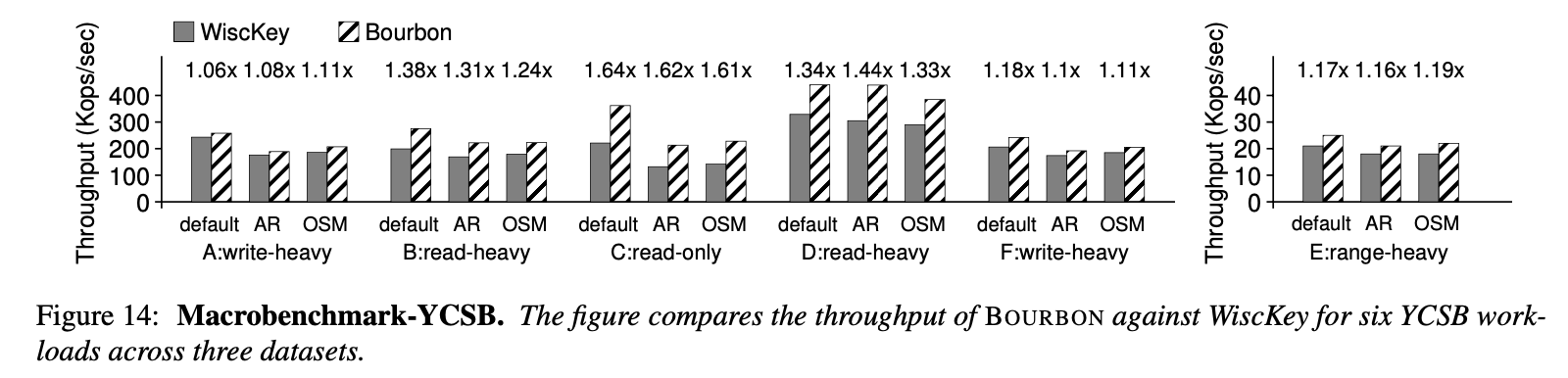
真实数据集测试
数据在存储设备上的场景
下图为在Optane傲腾SSD上的测试,在高速存储设备上bourbon能带来1.25-1.28倍的性能提升

对于YCSB,bourbon在read-heavy类型的负载下也有较好的表现1.16x-1.19x

内存资源有限的场景
在内存资源不足的情况下,对于不同的负载bourbon也可以达到一定的性能提升。
负载特征:内存存储25%数据,SATA SSD存储75%的数据,80%的请求访问25%的数据。
对于zipfian分布的负载bourbon可以达到1.25倍的性能提升

Tradeoffs评估
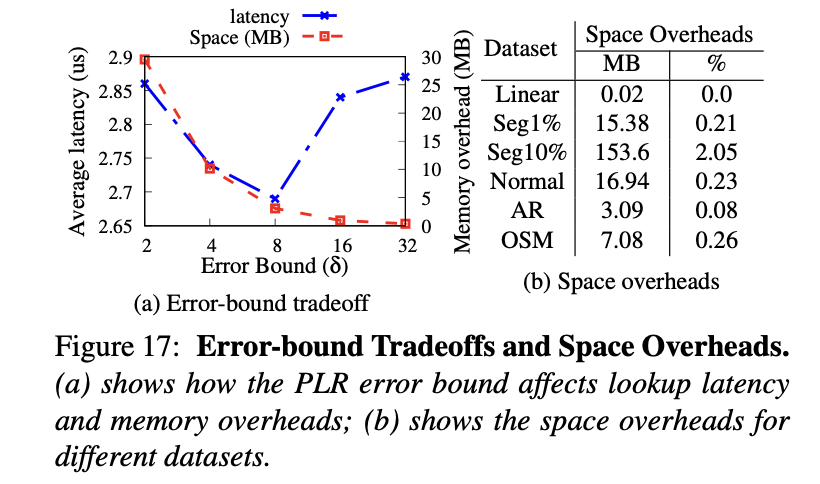
$\delta$会影响分段线性回归所建立的segments数量,越大的error bound可以建立更少的segments,减少存储空间,越小的error bound可以加速查找过程,二者tradeoff下选择8较为合适。下图中的表b也可以看出,建立学习索引所占的空间开销相比于数据集而言还是很小的。
0x04 Conclusion
本文首次将学习索引应用到了LSM-tree之中,基于Whiskey Key-Value分离存储的开创性工作,使得对LSM-tree建立学习索引成为可能(定长SSTable entry)。文章通过详细的实验分析说明了学习索引加速LSM-tree Lookup的性能提升,并指出在未来高性能SSD/存储设备上学习索引能带来更大的收益。