
[OSDI'23] eZNS: An Elastic Zoned Namespace for Commodity ZNS SSDs
这篇文章写作很多地方没有说清楚,motivation部分描述实验负载时不够清楚,第三个实验/observation看了很久才看出来是想表达什么问题。文章的三个主要设计都围绕motivation中的三个问题,整体的设计思想有点类似于将应用和固态盘namespace绑定,按照调度应用I/O的思想来管理ZNS中Zone的资源。
0x00 Background
本文主要设计三个重要概念,逻辑Zone、物理Zone以及ZNS中的条带化Stripping
Physical Zone,物理Zone,是ZNS的最小分配单元,一般为一个block或多个(cross-die)Block组成,需要按顺序写入并通过RESET命令一起擦除
Logical Zone,逻辑Zone,则由多个物理Zone组合,是SSD向上层暴露的接口,利用cross-die的物理Zone来提高并行性
在逻辑Zone中,还存在Stripping机制来将数据分散到多个物理zone中,包括两个参数:
- 条带大小 Stripping Size,条带中最小的数据操作单元,一般和闪存页大小对齐,减少不必要的I/O
- 条带宽度 Stripping Width,一个逻辑Zone中包含物理Zone的数量,用于提高并行度
0x01 Motivation
- Zone Type:
- Physical Zone 由多个die上的block组成
- Logical Zone 由多个Physical Zone组合,可以通过设备固件/软件实现
- Zone Size:
- Large Zone 因为包含多个可并行的die,可以提供更高的性能,但是不够灵活,主机管理开销大,作者认为适合租户少的场景,不需要同时打开多个zone进行I/O;带宽利用率低
- Small Zone 支持更多的I/O Streams,主机端的GC开销小
- 目前ZNS接口存在的问题:
- 存储区域的划分需要考虑物理区域和stripping的配置,需要应用的优化。用户/应用来管理Zone的划分可能导致多租户间的干扰;同时使应用更复杂。
- 为了应对应用复杂的I/O行为(I/O size,Read/Write,LBA Distribution),现有zone接口不能做出适配,需要过度供应Zone数量OP,资源利用率低。eg: 在为每个应用划分namespace的场景下,Rocksdb/Zenfs,Btrfs,F2FS在处理写入时只会开启少量的Zone,造成了较低的利用率。
- 性能隔离问题。虽然对I/O在物理空间上进行了隔离,但是为了提高利用率在多租户场景下会存在SSD内部带宽的干扰。ZNS的GC、磨损均衡行为对主机透明,无法预测ZNS的性能。传统SSD处理I/O、GC会尽可能的利用并行度,ZNS会受到Zone的约束。
ZNS的目前存在的三个问题
-
Zone Striping机制
- 对于较大的Zone Size,会超出一个闪存块的大小,通过striping策略来对cross-die的flash block组成一个Zone,类似RAID 0
- Stripe Size:一个Stripe中数据组织的最小单元
- Stripe Width:一个Stripe可以开启的最大物理Zone数量
- 问题1:Zone Striping面临的问题,目前Striping的划分与应用无关,根据应用的I/O特征来设置Stripping Size可以提高SSD利用率
- 对于较大的Zone Size,会超出一个闪存块的大小,通过striping策略来对cross-die的flash block组成一个Zone,类似RAID 0
-
Zone Allocation和Placement
-
zone的分配应该充分利用SSD内部Die的并行性,提高单个逻辑Zone中的物理Zone数量可以显著提高性能
-
问题2:目前的机制为在下一个空闲的die上扩展逻辑Zone,没有考虑该逻辑Zone中其他物理Zone的分布情况
- 物理Zone分配于同一个Channel下的其他Die中
- 物理Zone分配于同一个Die中的其他Block中
-
-
ZNS的I/O执行
- 混合读写的场景下,会导致ZNS处理读延迟时的尾延迟升高,传统SSD由于写放大会导致尾延迟的升高,ZNS主要是因为Zone并行性问题。
- die的带宽有限,并且可能会有冲突。同时SSD内部的cache回写会导致带宽的竞争问题,传统SSD可以直接控制映射关系来缓解die之间的带宽干扰,而ZNS必须写入到特定的物理Zone/Die。
- Figure 9的实验为了说明不同Zone之间的性能分配不公平问题。对于读I/O,采用workload A qd 8 cross 2 zones和workload B qd 2 cross 8 zones,在没有干扰的情况下(Zone A和Zone B没有冲突的Die),由于Zone B有更好的die级别并行性,能达到更高的性能,但是当workload A/B同时运行时,A的队列深度更高导致B的资源占比更低。对于写I/O,WW-の-Cong中写入没有触发Write Cache的换出,当发生写入拥塞时,Zone A/B的性能都有下降,且B下降的更明显,这是因为Write Cache冲突的问题。写入测试中Zone A是指15个条带宽度为8的Zone,Zone B为条带宽度为2的Zone。
- 问题3:多住户场景下应该考虑应用对底层die的使用情况,并以此来实现拥塞避免方案来实现公平调度,同时关注写入缓存的问题。
0x02 Design
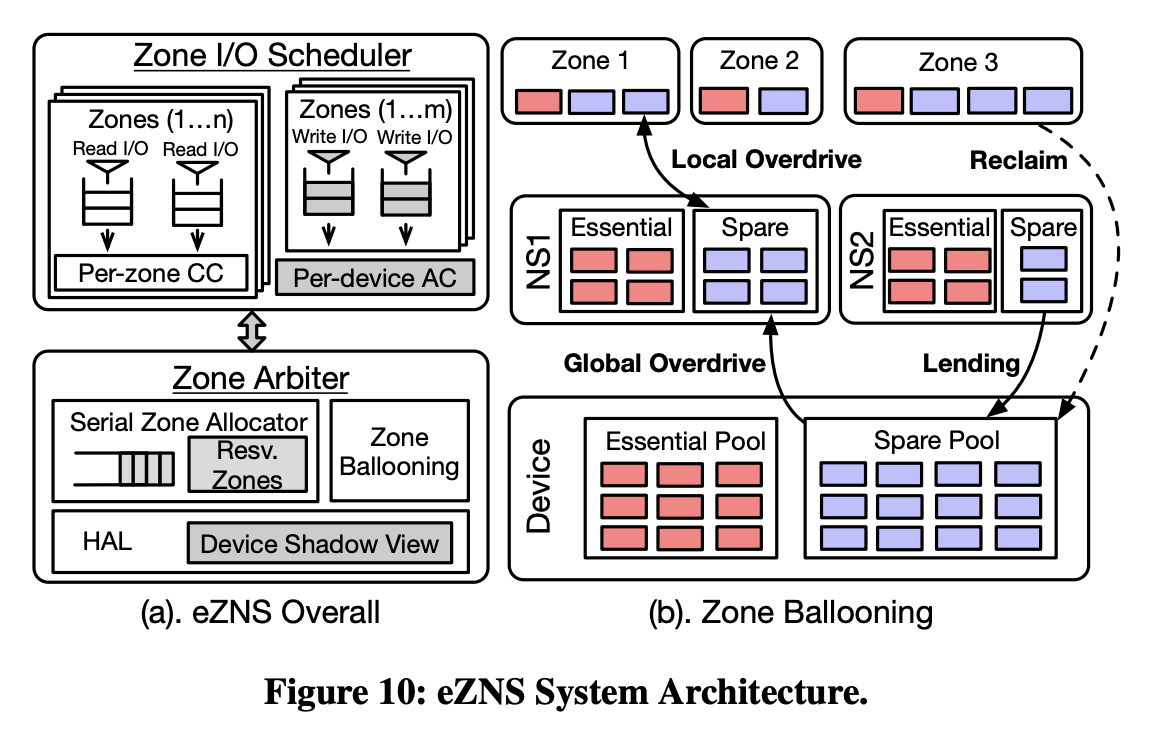
eZNS的整体架构如下图,实现与NVMe驱动层之上,提供v-zone接口来实现三种功能:
- 运行时的硬件动态调整
- 应用灵活性
- 多租户感知
eZNS主要包含两个部分:
- Zone Arbiter:
- 在硬件抽象层HAL维护设备的shadow view
- 执行序列化的Zone分配来避免Zone物理空间的重叠
- 通过harvesting mechanism动态伸缩Zone的物理资源和I/O配置
- Zone I/O Scheduler:
- 通过delay-based冲突控制机制来重排读请求,使用基于token的控制算法来调节写请求
eZNS解决了Motivation中的三个问题
- 问题一:Stripping Width与应用行为不匹配,导致SSD利用率较低
- 问题二:Zone的分配不考虑SSD内部物理分布
- 问题三:多租户场景下的公平调度问题
HAL
为了实现动态的Zone空间调整,eZNS采用HAL机制。
HAL基于三个参数:
- maximum number of active zones(MAR),是die数量的倍数
- NAND page size,确定stripping的大小
- physical zone size,用于决定逻辑zone和stripping的组织方式
基于这三个参数,HAL为每个Namespace提供相同的MAR和Zone Size,可以根据需要动态的进行调整
问题一:提高ZNS利用率
透明的Zone分配机制,实现了Zone Ballooning。
将active zone分为两个池子:
Essentials Pool每个namespace的基本资源:
- 每个Zone中的专有资源
- 保证有足够的active zone供设备使用
- 保证设备的高利用率
Spares Pool可以被其他namespace借用的额外区域:
- 动态资源
- 用于临时提高Stripping width
- 可以cross-namespace 进行租借,进一步提高利用率
当一个Namespace需要更多Zone分配时,优先使用本地的Spares Pool中的Zone,还可以向其他Namespace的Spare Pool借用。当Namespace不再需要额外的Zone时,需要归还Spare Pool中的Zone。
通过该机制可以保证ZNS SSD较高的资源利用率。
问题二:避免Zone间冲突
设备透明的Zone空间分配机制
Serial Zone Allocator,保证了每个stripe group包含一组连续的物理Zone;单个stripe group中不存在die冲突;在不同的stripe group之间,写入冲突仅发生于所有die都被占用的情况下
具体分配为缓冲所有逻辑zone open命令,将物理zone和该逻辑zone绑定实现原子操作。由于存在write cache,需要加速flush的过程并提前保留分配信息来完成zone的分配。
问题三:多租户场景下的I/O干扰
用户透明的调度器
调度器主要分为两部分:
- 拥塞避免的读调度器
- ZNS的读延迟较为稳定(无GC且顺序/同步写入),通过延迟感知是否发生冲突
- 利用拥塞窗口cwnd为每个stripe group分配带宽,没有发生拥塞是cwnd递增增加,若发生拥塞则快速减小。
- 感知write cache的写控制器
- 对每个v-zone使用令牌来控制写I/O的下发。
- 利用平均写延迟来监控write cache的下刷情况,并用来调整令牌的生成速率。同时控制令牌在不同zone之间的公平分布(根据上次回收时间来重新计算令牌数量)。
0x03 Evaluation
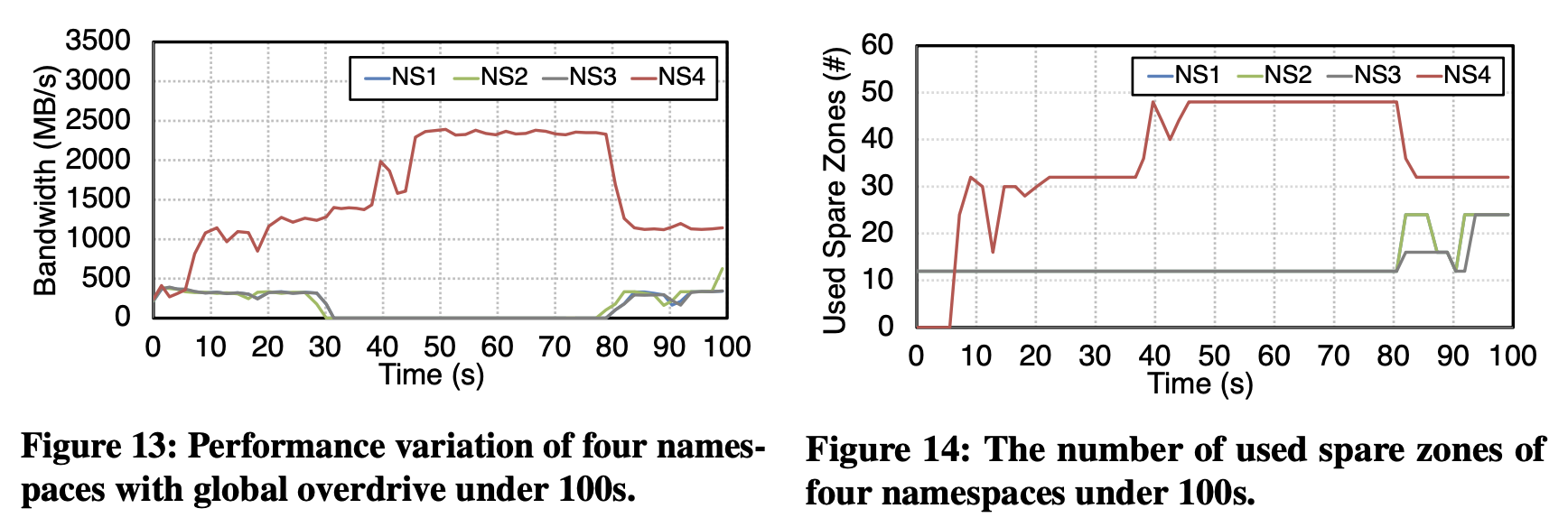
Zone Ballooning
使用4个namespace,每个namespace包含16个active logical zone
是个NS全部执行写入,NS1-NS3线程数为2,NS4线程数为8
Figure 13可以看出,30-40s NS1-NS3停止写入,NS4需要更多的写入资源申请了更多Zone,得到了写入带宽的提升,同时借用了其他NS的Spares Pool。在80s时重新归还了借用的Zone。
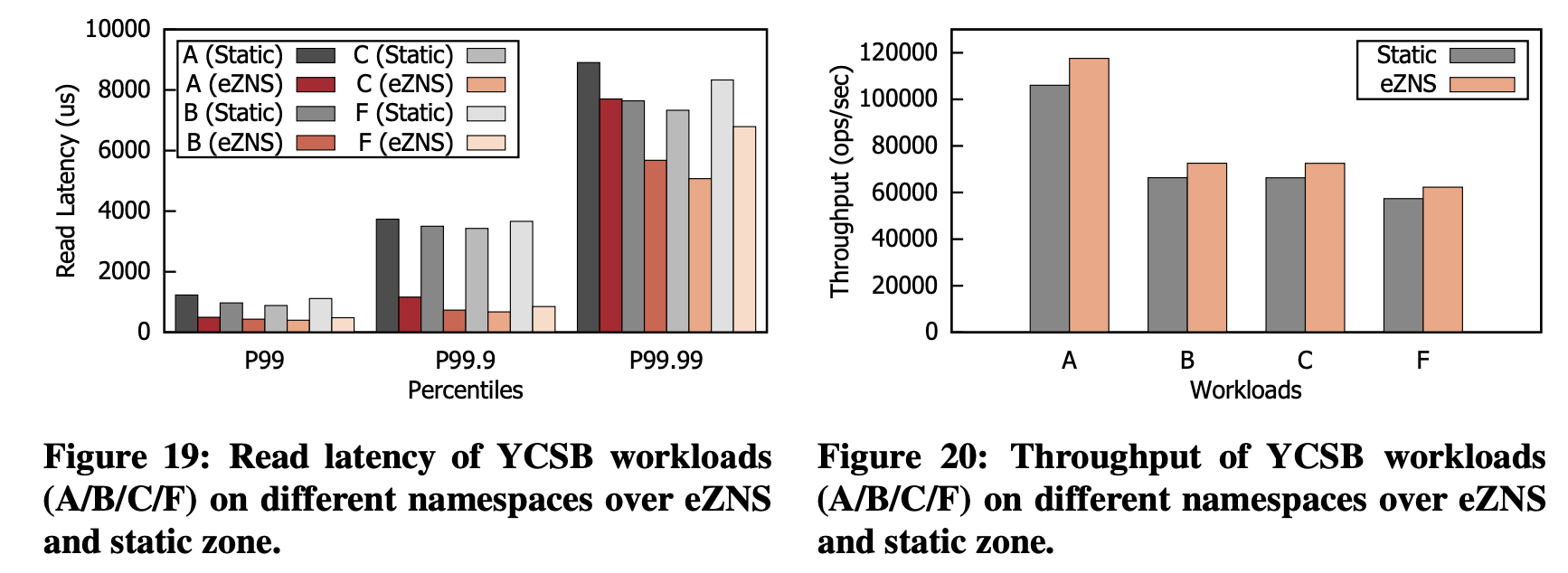
多租户场景 RocksDB + ZenFS
四种负载为:
- A:Update-heavy
- B:Read mostly
- C:Read only
- F:Read Modify Write
四个负载运行于不同的Namespace上,对于Read Only的负载,eZNS将其空闲资源分配给了写入较多的负载A、F
四个负载在尾延迟、OPS上均有提升
0x04 Conclusion
这篇文章写作很多地方没有说清楚,motivation部分描述实验负载时不够清楚,第三个实验/observation看了很久才看出来是想表达什么问题。文章的三个主要设计都围绕motivation中的三个问题,整体的设计思想有点类似于将应用和固态盘namespace绑定,按照调度应用I/O的思想来管理ZNS中Zone的资源。