
[FAST'18] FEMU闪存模拟系统介绍
0x00 Everyday English
LOC == line of code
Guest OS == VM
intricacies 错综复杂
drop-in replacement 通常表示直接替换,并且替换后不会产生影响,甚至会有一些新的功能
leverage 对…产生影响;一般也可以理解为 充分利用,比utilize语气强一些
0x01 Intro
FEMU是用于软硬件全栈的SSD研究模拟平台,基于QEMU开发,相比于OpenChannel SSD实现了较高的准确率
此前的SSD研究模拟工具大多不开源,可扩展性差,研究成本高,并且已经过时。
FEMU首先开源免费,并且有较高的准确度,同时可伸缩性强,最大支持32 I/O 线程并模拟32个并行的SSD channels/chips,可扩展性高,得益于基于QEMU的优点,FEMU可以支持针对于SSD的研究,针对os 内核的研究,或者基于os内核和SSD的研究。
FEMU GitHub 仓库地址: https://github.com/vtess/FEMU
0x02 FEMU
FEMU本身仅有3929行代码,基于QEMU v2.9,FEMU近些年的更新也主要为修复一些bug、合并QEMU的版本,将传统的App+宿主机+SSD的研究架构转变为了App+虚拟机+FEMU。
FEMU中的FTL模块、GC、I/O调度主要基于VSSIMVSSIM: Virtual machine based SSD simulator | IEEE Conference Publication | IEEE Xplore
可伸缩性
对于当前的高并行化的SSD,可伸缩性对模拟闪存至关重要。通过virtio和dataplane接口进行模拟,不能达到足够的可伸缩性,同时存在较高的延迟。
在QEMU中存在的两个主要问题是
- QEMU使用传统的trap-and-emulate方法进行I/O模拟,虚拟机的NVMe驱动通过doorbell寄存器告知QEMU模拟的I/O设备。该doorbell将引起开销较大的VM-exit,同时在I/O完成阶段,也会产生该调用。
- QEMU使用异步I/O来实现read/write,AIO的执行需要避免QEMU的I/O被阻塞,当在存储后端是基于RAM的镜像时,AIO产生的负载尤为明显
解决方案为:
- 使用基于轮询的方案,并且禁用了虚拟机的doorbell写操作,通过一个线程来轮询存储设备队列的状态,避免了VM-exit
- 不使用虚拟的镜像文件,使用自定义的以RAM为后端的存储模拟,定义在QEMU的堆空间中,将QEMU中DMA修改为从QEMU heap中读写数据,这个改变对VM来说是透明的
准确度
延迟模拟
当I/O请求到达后,FEMU发起DMA R/W,并用模拟的完成时间$(T_{endio})$对I/O请求进行标记,添加到endio queue中,队列按照I/O的完成时间进行排序。一旦I/O请求的预估完成时间大于当前时间,会由专门的end I/O 处理线程负责将其通过中断发送给虚拟机。
FEMU对每个I/O请求都设置了+50us的延迟。
延迟模型
对于$T_{endio}$的计算:
标记每个plane和channel的下一次空闲时间$T_{free}$,
例如,一个page写入需要channel #1 和plane #2来执行,那么channel的下一次空闲时间将为$T_{freeOfChannel1}=T_{now}+T_{transfer}$,其中的$T_{transfer}$为一个可配置的page在channel中的传输时间,plane的下一次空闲时间则为$T_{freeOfPlane2}+=T_{write}$,其中$T_{write}$是可配置的NAND page写入时间。
因此该写入操作的$T_{endio}=T_{freeOfPlane2}$。
在一个写入过程正在执行时,对于新到达的page read,将令$T_{freeOfPlane2} += T_{read}$,其中$T_{read}$为可配置的参数NAND page读取时间,并且$T_{freeOf Channel1} += T_{transfer}$,
因此该page write的$T_{endio}=T_{freeOf Channel1}$。
由于普通的SSD plane只有一个寄存器,单个plane不能实现I/O并行,所以该模型可以满足实际要求
该模型可以通过添加一个$T_{erase}$来模拟GC的延迟
OpenChannel延迟模型
OpenChannel SSD,OC使用双寄存器的plane,data register和cache register,因此在一个plane中对一个NAND page的read/write可以并行,因此效率高,下图直观的展示了二者的区别。
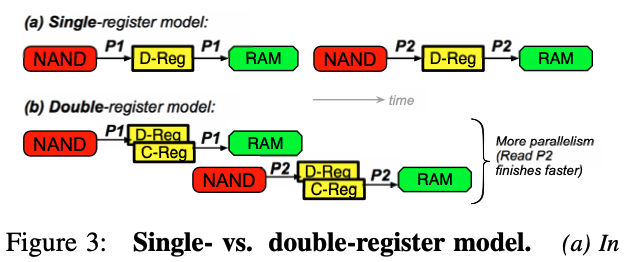
OC有着不统一的延迟模型,映射到MLC颗粒cell高位bits的page有着更高的延迟,实际上一个NAND中的512个page以一种特别的方式进行组织,LLLLLLuLLuLLuuLLuu...(repeate of LLuu)
FEMU对OC的实现方式进行了整合,实现了较好的效果
其他功能
- FTL和GC:默认使用动态映射FTL,channel阻塞的GC。同时还支持channel、controller、plane层面进行阻塞的GC策略
- 白盒模式/黑盒模式
- 多设备支持:支持虚拟机连接多个SSD,每个SSD包含独立的NVMe实例和FTL
- 扩展NVMe指令
- Page-Level延迟可自定义:模拟闪存芯片的良品率带来的延迟不统一性
- 分布式SSD:评估类似Hadoop的应用
- Page-Level故障注入:进行闪存可靠性研究
- 一些限制:FEMU基于DRAM,不能模拟容量太大的SSD,必须手动模拟SSD崩溃的情景,因为DRAM重启将会清空所有数据