本文的内容主要参考了filebench在USENIX ;login:'16上的文章(正值filebench 1.5发布)和官方仓库的wiki,filebench从2005年开源到今天已经过去了18年了,github最后一次commit截止在了3年前,之后也没有维护过了,不过filebench目前已经比较完善了,也得到了学术界比较广泛的认可,到今天依然还能拿来跑一些benchmark。本篇文章主要目的是解释一些filebench中的参数,几个预定义工作负载,最后来介绍如何使用filebench来测试ZNS的性能。
Filebench简介及相关参数说明
Filebench是一个用于文件系统/存储设备性能测试的工具,该项目始于2002年,由Sun Microsystems发起,在2005年开源,经常被系统领域的论文用于性能基准测试。Filebench除了可以自行定义负载,还预定义了几种常见的负载,例如Web服务器,邮件服务器,文件服务器等。
Filebench通过Workload Model Language来描述I/O负载。主要包括:
- fileset: 描述一组文件,可以设定file name,path,文件数量entries,文件大小filesize等信息
- process:定义负载的进程实例
- thread:包含于process,filebench执行负载的基本单位
- flowop:filebench提供的操作指令,对应文件系统syscall,执行文件读写等操作
filebench在运行时可以配置为两种模式:
- 预先分配文件fileset preallocation
- 工作时执行分配
filebench默认不会直接创建文件,只预分配文件所需要的空间,可以通过设置prealloc参数来让filebench预创建文件,例如下面的prealloc=80则表示预创建80%的文件
1
2
|
define fileset name=”test1”,path=”/tmp”,
entries=1000,filesize=128k,prealloc=80
|
filebench之所以不预先创建文件,是考虑到有些工作负载过程中包含文件创建的操作,同时要保证WML描述的负载不能超过fileset所包含的文件总数量。比如fileset定义了1000个文件,但是在WML中尝试去创建第1001个文件,filebench会抛出异常停止负载。
instances=N参数可以让filebench创建多个相应的进程/线程进行测试,每个进程内部可以包含多个不同/相同的测试线程,下面的负载就描述了进程filecreate包含两个filecreatethread线程,用于测试文件系统处理文件创建操作的能力。
1
2
3
4
5
6
7
8
9
10
|
set mode quit firstdone
define fileset name=”fcrset”,path=”/tmp”, entries=10000,filesize=16k
define process name=”filecreate”,instances=1 {
thread name=”filecreatethread”,instances=2 {
flowop createfile name=”crfile”,filesetname=”fcrset”
flowop closefile name=”clfile”
}
}
run
|
每个线程执行Flowop描述的指令流,Flowop表示文件系统的操作(filesystem syscall),例如:
- createfile:创建文件,可以指定一个虚拟FD
- write:向某个文件写入数据
- openfile:打开文件,指定一个虚拟的文件描述符FD用于其他的Flowop
- closefile:关闭文件,关闭(虚拟)FD所对应的文件
- deletefile:删除文件
- read:从文件中读取数据
- readwholefile:读取整个文件的内容
- writewholefile:写入到文件
- appendfile:追加写入文件末尾
- statfile:发起
stat()系统调用,获取文件信息(ino_t,nlink_t,off_t…)
- fsync:发起fsync系统调用,强制落盘
filebench还支持一些异步/同步I/O操作
Virtual File Descriptors,虚拟FD来表示一个文件,filebench可以显视的制定VFD来操作文件,如果没有指定将默认fd=0,下面是一个使用VFD的负载示例。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
set mode quite firstdone
define fileset name=”testfset”,path=”/tmp”,
entries=10000,filesize=4k,prealloc=50
define process name=”filecopy”,instances=2 {
thread name=”filecopythread”,instances=2 {
flowop openfile name=opfile”, filesetname=”testfset”,fd=1
flowop createfile name=”crfile”, filesetname=”testfset”,fd=2
flowop readwholefile name=”rdfile”, filesetname=”testfset”,fd=1
flowop writewholefile name=”wrfile”, filesetname=”testfset”,fd=2
flowop closefile name=”clfile1”, filesetname=”testfset”,fd=2
flowop closefile name=”clfile2”, filesetname=”testfset”,fd=1
}
}
|
默认情况下,filebench对于openfile操作会迭代打开fileset中的所有文件(负载均衡),也可以指定index来显示指定要操作的文件。
filebench还能控制文件的访问模式:
- iosize:指定I/O的大小
- Sequential/Random Access:顺序或随机访问文件
- wss:指定随机访问的working set size
- direct/synchronous I/O:direct访问或同步I/O
每个负载结尾通过run/psrun命令来指定负载运行的时间,psrun命令可以在运行时持续输(每十秒)出负载性能情况。
通过以上参数描述过的WML保存为一个workload.f文件,通过改命令来指定filebench要运行的负载
1
|
filebench -f workload.f
|
quit mode:filebench在两种情况下结束负载的运行:
- time based,通过run参数指定运行的时间,默认为1minutes
- 所有线程完成了flowop
通过set mode quit xxxx指令可以决定负载结束的条件,这里介绍几种结束条件:
-
firstdone:其中一个线程处理的文件超出了fileset范围,例如创建文件操作超出了fileset
-
alldone:所有线程都超出了fileset范围/耗尽了fileset资源
-
finishoncount:用于终止一个线程,执行了指定次数的flowop操作(read/write)
1
|
flowop finishoncount name=<name>,value=<ops/s>,[target=<any-flowop]
|
-
finishonbytes:用于终止一个线程,执行了指定数据量的flowop操作(read/write)
filebench运行结束后,会输出测试的性能信息,包括operation per second,带宽/吞吐量,每个flowop的操作延迟等信息,filebench还能以process/thread/flowop的粒度来统计性能信息。
Filebench高级功能
变量设置 Variables
通过set命令来指定变量,避免使用常数来定义线程数、iosize等参数
cvar costume variables可以用来指定一些统计学分布的参数,这个功能是通过dll实现的,也可以自己定义新的参数分布。举下面的样例来说明一下,findex定义了一个正态分布,生成的index分布为[0,999],与下面的fileset entries保持一致,同时指定了均值和标准差sigma。通过这样的配置后,reader thread就能按照该分布产生的file index来读取文件(默认情况下将轮询fileset中的所有文件),因此负载对某些文件的访问会比较频繁。
1
2
3
4
5
6
7
8
9
10
11
|
set $findex=cvar(type=cvar-normal,min=0,max=999,parameters=mean:500;sigma:100) \
set $off=cvar(type=cvar-triangular,min=0,max=28k,parameters=lower:0;upper:28k;mode:16k)
define fileset name=”test”,path=”/tmp”,entries=1000, filesize=32k,prealloc=100
thread name=”reader”,memsize=10m {
flowop read name=”rdfile”,filesetname=”test”,indexed=$findex,offset=$off,iosize=$iosize
flowop closefile name=”clsfile1”
flowop block name=”blk”
}
|
同步原语 Synchronization Primitives
负载中的多个线程可能有数据间的依赖关系,因此filebench引入了一些同步原语,例如block, wakeup, semblock, sempost这些flowops。下面的负载样例可以看到,第一个reader线程被阻塞,noio线程调用wakeup可以将其唤醒。同步原语通过target和name这些标记来执行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
define process name=”testproc1” {
thread name=”reader”,memsize=10m {
flowop read name=”rdfile”,filesetname=”test”,indexed=$findex,offset=$off,iosize=$iosize
flowop closefile name=”clsfile1”
flowop block name=”blk”
}
thread name=”writer”,memsize=20m {
flowop write name=”wrfile”,
filesetname=”test”,iosize=$iosize
flowop closefile name=”clsfile2”
flowop opslimit name=”limit”
}
thread name=”noio”,memsize=40m {
flowop hog name=”eatcpu”,value=1000
flowop delay name=”idle”,value=1
flowop wakeup name=”wk”,target=”blk”
}
}
|
CPU和内存开销模拟
filebench的hog指令可以让线程占用一些CPU cycles和内存资源,模拟真实线程对CPU和内存的消耗情况,参数通过指定values来让线程执行多次的内存拷贝。
delay指令可以模拟线程的等待I/O的过程,让线程sleep一段时间
memsize参数可以限制/指定线程的内存使用情况
下面的负载则表示,线程使用40m的内存空间,每次循环时,然后休眠1秒
1
2
3
4
5
|
thread name=”noio”,memsize=40m {
flowop hog name=”eatcpu”,value=1000
flowop delay name=”idle”,value=1
flowop wakeup name=”wk”,target=”blk”
}
|
I/O速率限制
iopslimit指令可以限制iops
bwlimit指令可以限制带宽
eventgen指令用于全局限制(所有的process和threads)
访问参数
filebench支持offset来对文件进行读写
延迟分布
可以通过enable lathist来分析请求的延迟(每个flowop)分布情况
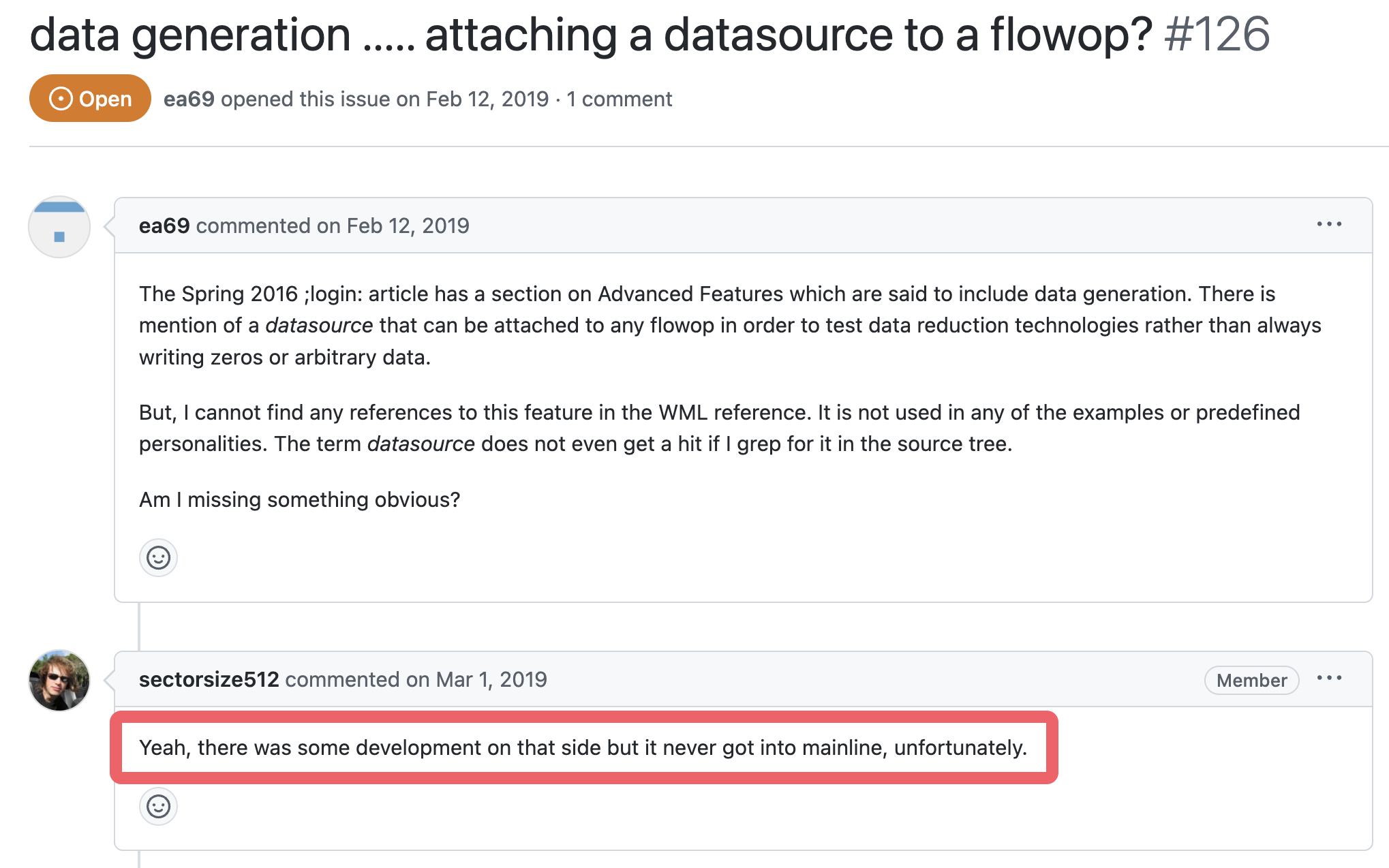
数据生成
~~filebench可以控制数据生成的策略,以往为全零写入,该特性对于数据压缩、重复数据删除等研究领域有巨大的作用。~~官方wiki并没有找到有关datasource指令的描述,但是有个2019年的issues提到了这一点,应该是开发到一半放弃了或者是什么原因,如果我找到了相关的内容会及时更新这一部分:
文章里还有几个advanced feature的描述,例如Composite Flowops,File System Importing,但是在官网wiki没有找到相关的描述,因此先TODO一下。
一些预定义的负载
filebench还有一个很大的贡献就是提供了丰富的预定义负载,比较符合真实应用的行为。
这里介绍三个负载:Web-server,File-server,Mail-Server
Web-server
Web服务器往往是处理用户通过HTTP请求的网站静态资源,服务器会将网站所有的文件都读取并返回,同时在log文件记录日子。filebench的webserver.f负载则按照该流程来描述。
下面是该负载中的一部分,每个线程将完全读取10个文件(模拟10个静态资源文件),并生成日志数据追加写入到log文件中。文件的大小遵循连续概率分布,平均大小为16KB,负载整体采用100个线程来读取1000个文件,模拟并发访问场景。bigfileset、logfiles都是完全预分配文件(prealloc如果缺省number则表示100%预分配)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
set $dir=/tmp
set $nfiles=1000
set $meandirwidth=20
set $filesize=cvar(type=cvar-gamma,parameters=mean:16384;gamma:1.5)
set $nthreads=100
set $iosize=1m
set $meanappendsize=16k
define fileset name=bigfileset,path=$dir,size=$filesize,entries=$nfiles,dirwidth=$meandirwidth,prealloc=100,readonly
define fileset name=logfiles,path=$dir,size=$filesize,entries=1,dirwidth=$meandirwidth,prealloc
define process name=filereader,instances=1
{
thread name=filereaderthread,memsize=10m,instances=$nthreads
{
flowop openfile name=openfile1,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile1,fd=1,iosize=$iosize
flowop closefile name=closefile1,fd=1
flowop openfile name=openfile2,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile2,fd=1,iosize=$iosize
flowop closefile name=closefile2,fd=1
flowop openfile name=openfile3,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile3,fd=1,iosize=$iosize
flowop closefile name=closefile3,fd=1
flowop openfile name=openfile4,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile4,fd=1,iosize=$iosize
flowop closefile name=closefile4,fd=1
flowop openfile name=openfile5,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile5,fd=1,iosize=$iosize
flowop closefile name=closefile5,fd=1
flowop openfile name=openfile6,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile6,fd=1,iosize=$iosize
flowop closefile name=closefile6,fd=1
flowop openfile name=openfile7,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile7,fd=1,iosize=$iosize
flowop closefile name=closefile7,fd=1
flowop openfile name=openfile8,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile8,fd=1,iosize=$iosize
flowop closefile name=closefile8,fd=1
flowop openfile name=openfile9,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile9,fd=1,iosize=$iosize
flowop closefile name=closefile9,fd=1
flowop openfile name=openfile10,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile10,fd=1,iosize=$iosize
flowop closefile name=closefile10,fd=1
flowop appendfilerand name=appendlog,filesetname=logfiles,iosize=$meanappendsize,fd=2
}
}
|
File-server
该负载使用50个进程(代表用户),每个进程包含创建、写入文件、打开文件、追加写入、完全读取、文件删除、文件元数据检查的操作。
该负载预分配了80%的平均大小为128KB的文件10000个,因为对于文件服务器可能存在新写入/创建的文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
set $dir=/tmp
set $nfiles=10000
set $meandirwidth=20
set $filesize=cvar(type=cvar-gamma,parameters=mean:131072;gamma:1.5)
set $nthreads=50
set $iosize=1m
set $meanappendsize=16k
set $runtime=60
define fileset name=bigfileset,path=$dir,size=$filesize,entries=$nfiles,dirwidth=$meandirwidth,prealloc=80
define process name=filereader,instances=1
{
thread name=filereaderthread,memsize=10m,instances=$nthreads
{
flowop createfile name=createfile1,filesetname=bigfileset,fd=1
flowop writewholefile name=wrtfile1,srcfd=1,fd=1,iosize=$iosize
flowop closefile name=closefile1,fd=1
flowop openfile name=openfile1,filesetname=bigfileset,fd=1
flowop appendfilerand name=appendfilerand1,iosize=$meanappendsize,fd=1
flowop closefile name=closefile2,fd=1
flowop openfile name=openfile2,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile1,fd=1,iosize=$iosize
flowop closefile name=closefile3,fd=1
flowop deletefile name=deletefile1,filesetname=bigfileset
flowop statfile name=statfile1,filesetname=bigfileset
}
}
|
Mail-Server
varmail.f描述的负载是传统UNIX系统中对/var/mail目录中的文件操作。用户收到邮件后,将执行文件创建、写入和fsync落盘操作。当用户读取邮件时,发生文件打开、读取、标记为已读、fsync操作,或者是读取已读的文件。平均的文件大小为16KB,采用16个线程。
负载的workflow为:
- 删除文件(模拟删除邮件/预留一个创建文件的空位)
- 创建邮件文件,写入邮件数据,落盘后关闭文件
- 打开一个未读邮件,读取内容后追加写入已读mark,落盘后关闭
- 读取一个已读文件,读取内容后关闭
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
set $dir=/tmp
set $nfiles=1000
set $meandirwidth=1000000
set $filesize=cvar(type=cvar-gamma,parameters=mean:16384;gamma:1.5)
set $nthreads=16
set $iosize=1m
set $meanappendsize=16k
define fileset name=bigfileset,path=$dir,size=$filesize,entries=$nfiles,dirwidth=$meandirwidth,prealloc=80
define process name=filereader,instances=1
{
thread name=filereaderthread,memsize=10m,instances=$nthreads
{
flowop deletefile name=deletefile1,filesetname=bigfileset
flowop createfile name=createfile2,filesetname=bigfileset,fd=1
flowop appendfilerand name=appendfilerand2,iosize=$meanappendsize,fd=1
flowop fsync name=fsyncfile2,fd=1
flowop closefile name=closefile2,fd=1
flowop openfile name=openfile3,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile3,fd=1,iosize=$iosize
flowop appendfilerand name=appendfilerand3,iosize=$meanappendsize,fd=1
flowop fsync name=fsyncfile3,fd=1
flowop closefile name=closefile3,fd=1
flowop openfile name=openfile4,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile4,fd=1,iosize=$iosize
flowop closefile name=closefile4,fd=1
}
}
echo "Varmail Version 3.0 personality successfully loaded"
run 60
|
Webproxy
webproxy.f描述的负载是一个web代理服务器,用户通过代理服务器访问网站,代理服务器会将网站的内容缓存到本地,当用户再次访问时,代理服务器会直接返回缓存的内容。该负载预先分配80%的缓存文件,使用100个线程操作10000个文件。该负载的workflow为:
- 删除文件(预留一个创建文件的空位)
- 读取一个已经缓存的文件(重复5次)
该负载还通过opslimit来限制短时间内的操作次数,避免负载过早结束,同时还可以控制系统的资源。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
set $dir=/tmp
set $nfiles=10000
set $meandirwidth=1000000
set $meanfilesize=16k
set $nthreads=100
set $meaniosize=16k
set $iosize=1m
define fileset name=bigfileset,path=$dir,size=$meanfilesize,entries=$nfiles,dirwidth=$meandirwidth,prealloc=80
define process name=proxycache,instances=1
{
thread name=proxycache,memsize=10m,instances=$nthreads
{
flowop deletefile name=deletefile1,filesetname=bigfileset
flowop createfile name=createfile1,filesetname=bigfileset,fd=1
flowop appendfilerand name=appendfilerand1,iosize=$meaniosize,fd=1
flowop closefile name=closefile1,fd=1
flowop openfile name=openfile2,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile2,fd=1,iosize=$iosize
flowop closefile name=closefile2,fd=1
flowop openfile name=openfile3,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile3,fd=1,iosize=$iosize
flowop closefile name=closefile3,fd=1
flowop openfile name=openfile4,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile4,fd=1,iosize=$iosize
flowop closefile name=closefile4,fd=1
flowop openfile name=openfile5,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile5,fd=1,iosize=$iosize
flowop closefile name=closefile5,fd=1
flowop openfile name=openfile6,filesetname=bigfileset,fd=1
flowop readwholefile name=readfile6,fd=1,iosize=$iosize
flowop closefile name=closefile6,fd=1
flowop opslimit name=limit
}
}
echo "Web proxy-server Version 3.0 personality successfully loaded"
|
Video-server
videoserver.f描述的负载是一个视频服务器,包含两个fileset,一个是正在播放的视频(active),一个是可用但还没有被播放的视频(inactive/passive),这里paralloc是通过多线程(32个)预分配文件,因为预分配的文件较大,需要提高效率。一个writer线程负责写入新的视频文件来替换掉passive的视频文件,48个reader线程负责读取视频文件,模拟视频的播放。
eventrate参数限制读取线程的读取速率,计算公式为nthreads*Rate,这里的Rate就是每个线程读取的带宽大小,为2mb/s。
repintval参数为视频文件的替换速率,每隔10s会写入一个视频文件进行替换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
set $dir=/tmp
set $eventrate=96
set $filesize=10g
set $nthreads=48
set $numactivevids=32
set $numpassivevids=194
set $reuseit=false
set $readiosize=256k
set $writeiosize=1m
set $passvidsname=passivevids
set $actvidsname=activevids
set $repintval=10
eventgen rate=$eventrate
define fileset name=$actvidsname,path=$dir,size=$filesize,entries=$numactivevids,dirwidth=4,prealloc,paralloc,reuse=$reuseit
define fileset name=$passvidsname,path=$dir,size=$filesize,entries=$numpassivevids,dirwidth=20,prealloc=50,paralloc,reuse=$reuseit
define process name=vidwriter,instances=1
{
thread name=vidwriter,memsize=10m,instances=1
{
flowop deletefile name=vidremover,filesetname=$passvidsname
flowop createfile name=wrtopen,filesetname=$passvidsname,fd=1
flowop writewholefile name=newvid,iosize=$writeiosize,fd=1,srcfd=1
flowop closefile name=wrtclose, fd=1
flowop delay name=replaceinterval, value=$repintval
}
}
define process name=vidreaders,instances=1
{
thread name=vidreaders,memsize=10m,instances=$nthreads
{
flowop read name=vidreader,filesetname=$actvidsname,iosize=$readiosize
flowop bwlimit name=serverlimit, target=vidreader
}
}
echo "Video Server Version 3.0 personality successfully loaded"
|
对负载的修改
为了评估系统不同部分的性能,可以对负载作出适当的修改
例如,对于Webserver负载而言,总体的文件大小仅16MB,可以完全缓存在Page Cache中,因此性能取决于操作系统的Cache,如果想进一步测试硬盘性能的影响,可以提高文件的数量让整个负载的文件占用更多的硬盘空间。
负载的运行时间也很重要,一般而言运行60s可以测的系统的真实情况(例如Cache warmup、bdflush脏页下刷落盘),通过psrun指令来收集运行时的性能情况,有助于观察系统是否处于稳定状态。
因为Filebench需要预先创建文件,这些文件创建后很可能已经在Page Cache中,因此可以通过如下的指令来清空Page Cache,避免影响后续的测试。在执行run/psrun之前,WML可以提前执行一些shell命令。
1
2
3
|
create fileset
system "sync"
system "echo 3 > /proc/sys/vm/drop_caches"
|
Filebench的安装和使用
这里主要参考官方仓库的安装流程。
首先clone或者下载filebench的release版本
Github仓库:
1
2
|
git clone https://github.com/filebench/filebench
cd filebench
|
1
2
3
|
wget https://github.com/filebench/filebench/archive/refs/tags/1.5-alpha3.zip
unzip 1.5-alpha3.zip
cd filebench-1.5-alpha3
|
仓库代码不包含Makefile和configure文件,需要通过autoreconf来生成,需要先安装libtool、automake、autoconf等工具
1
2
3
4
5
6
|
sudo apt-get install libtool automake autoconf
libtoolize
aclocal
autoheader
automake --add-missing
autoconf
|
然后执行configure和make
1
2
3
|
./configure
make
sudo make install
|
在某些情况下,直接运行可能会遇到段错误,因此运行负载之前,需要通过下面的命令关闭进程地址空间随机化ASLR,参考Filebench Issue#110。ASLR是一种安全机制,可以防止攻击者通过缓冲区溢出等方式来执行恶意代码,这个原因可能与Filebench内部实现中间接调用初始化函数时发生的地址偏移问题有关。
1
|
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
安装完成后,可以通过filebench -f workload.f来运行负载。
前面介绍的预定义负载都在/usr/local/share/filebench/workloads目录下,可以直接运行。最好在运行先先将预定义负载复制出来,根据系统环境修改参数(文件数量、线程数等)后再运行。这里TODO一下,后面补充一下如何根据当前系统的配置来合理的Scale负载。
使用Filebench测试ZNS
既然Filebench是对文件系统进行测试的工具,那么我们必须在ZNS上创建一个文件系统,然后将其挂载到某个目录下,这样Filebench才能对其进行测试。目前Linux已经有诸多文件系统支持了ZNS,例如F2FS(4.10支持Zone设备)、ZoneFS(5.6.0)、SSDFS(6.3)、Btrfs(5.16)、XFS(借助dm-zoned),这里以F2FS为例来介绍如何使用Filebench来测试ZNS的性能。要注意,Linux内核在5.9之后开始支持ZNS,因此需要使用5.9及以上的内核,一般而言使用LTS版本的5.10或者5.15。
准备工作:
- 支持ZNS的Linux内核(笔者使用的为5.15内核)
- 一块普通的固态盘
/dev/nvme0n1(用于存放F2FS的元数据)
- 一块ZNS固态盘
/dev/nvme1n1(笔者使用的固态盘都是FEMU闪存仿真平台所模拟的ZNS/SSD)
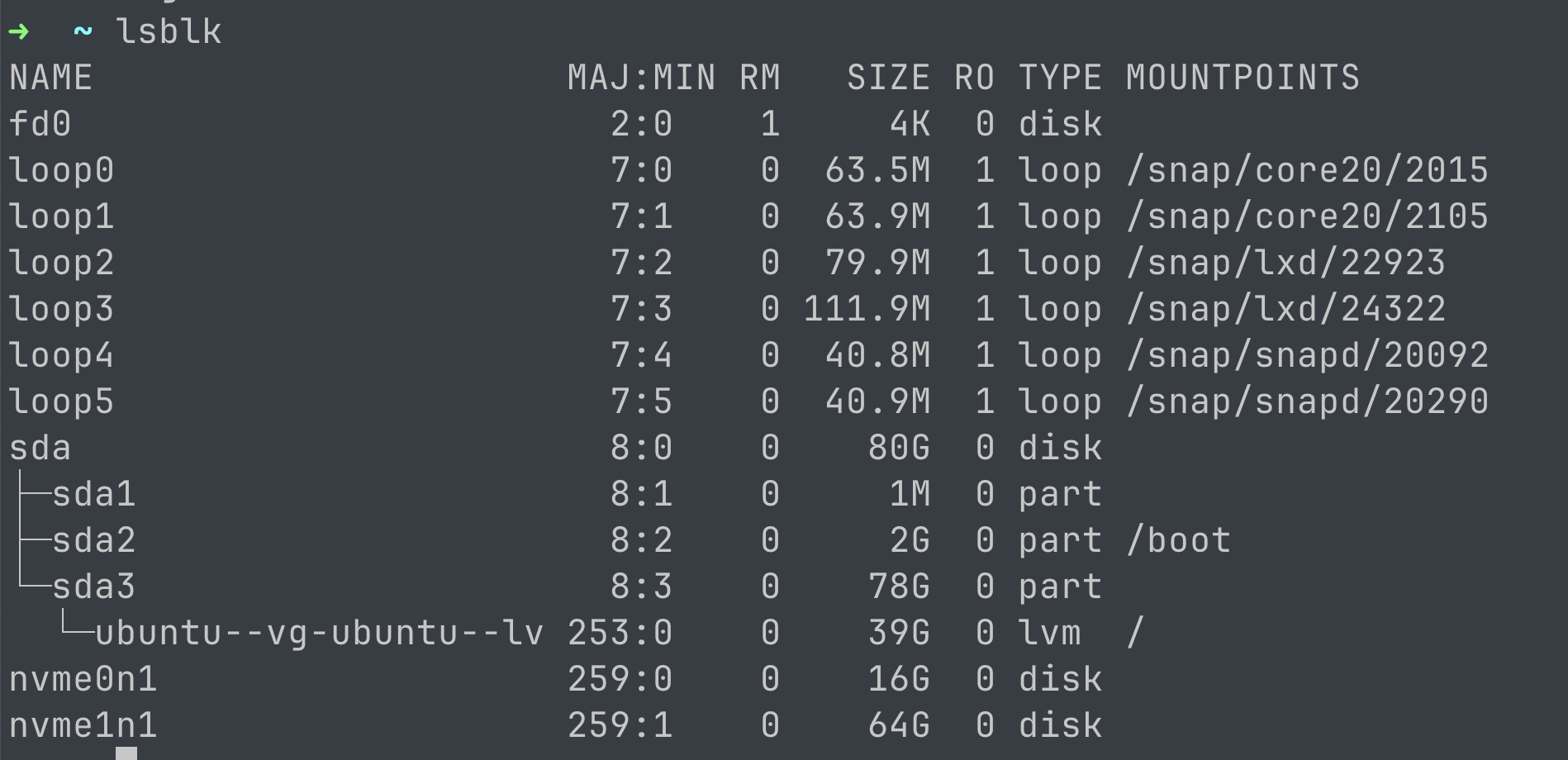
创建并挂载F2FS文件系统
这里参考了Zoned Storage中的配置过程。
由于ZNS不支持乱序写入,只允许顺序写,因此需要设置ZNS固态盘的调度器为mq-deadline,要指定ZNS对应的namespace。
1
|
echo mq-deadline > /sys/block/nvme1n1/queue/scheduler
|
笔者也曾经尝试配置过真实SSD+ZNS+F2FS,需要SSD和ZNS的Sector Size必须统一。由于缺少相应设备因此没有成功配置。
指定好调度器之后,通过mkfs.f2fs工具来指定普通SSD和ZNS建立F2FS文件系统,这里要注意mkfs参数的顺序,前面是ZNS,后面是普通SSD。
1
|
sudo mkfs.f2fs -f -m -c /dev/nvme1n1 /dev/nvme0n1
|
配置成功的话会显示类似下面的信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
F2FS-tools: mkfs.f2fs Ver: 1.15.0 (2022-05-13)
Info: Disable heap-based policy
Info: Debug level = 0
Info: Trim is enabled
Info: Host-managed zoned block device:
32 zones, 2147483648 zone size(bytes), 0 randomly writeable zones
524288 blocks per zone
Info: Segments per section = 1024
Info: Sections per zone = 1
Info: sector size = 512
Info: total sectors = 167772160 (81920 MB)
Info: zone aligned segment0 blkaddr: 524288
Info: format version with
"Linux version 5.15.81 xxxxxx"
Info: [/dev/nvme0n1] Discarding device
Info: This device doesn't support BLKSECDISCARD
Info: Discarded 16384 MB
Info: [/dev/nvme1n1] Discarding device
Info: Discarded 65536 MB
Info: Overprovision ratio = 10.000%
Info: Overprovision segments = 9420 (GC reserved = 6144)
Info: format successful
|
文件系统创建成功后,将组合后的设备挂载到某个目录下,这里要指定元数据盘(普通SSD)
1
|
sudo mount -t f2fs /dev/nvme0n1 /mnt/f2fs/
|
挂载成功后就可以使用filebench对ZNS进行性能测试了,还需要注意要更改filebench负载中的目录配置,比如/mnt/f2fs,一般要修改dir变量或者fileset path字段;同时要注意负载中描述的文件大小是否超出了SSD的容量,要通过计算将其修改为合适的大小。这里还需要注意,如果要测试的文件数量超过了1048576(1024*1024),需要改一下ipc.h#L77中的代码,否则会遇到Out of shared memory (1)的报错,完整的报错信息如下:
1
2
3
4
5
6
7
8
|
~> sudo filebench -f workload.f
Filebench Version 1.5-alpha3
0.000: Allocated 177MB of shared memory
0.006: Varmail Version 3.0 personality successfully loaded
0.006: Populating and pre-allocating filesets
0.552: Out of shared memory (1)! around line 34
0.552: fileset_populate_file: Can't malloc filesetentry around line 34
0.552: Failed to create filesets around line 34
|
这个问题的原因是filebench把支持的最大文件数量硬编码了,可以按需调大一些,修改后需要重新编译并install(参考Issues #90,StackOverflow #22688406)。例如修改为:
1
2
3
4
|
#define FILEBENCH_NFILESETS (16)
#define FILEBENCH_NFILESETENTRIES (1024 * 1024 * 10) // 这个参数限制了每个fileset文件数量,按需扩大即可
#define FILEBENCH_NPROCFLOWS (1024)
#define FILEBENCH_NTHREADFLOWS (1024)
|
Reference
-
[USENIX] Login'16
-
[Github] Filebench Repo
-
[Github] Filebench Issue#110
-
[WD] Zoned Storage
-
[Kernel.org] F2FS Docs
