
[OSDI'19] Flashshare: Punching Through Server Storage Stack from Kernel to Firmware for Ultra-Low Latency SSDs
超低延迟固态硬盘从内核到固件的服务器存储堆栈
个别名词解释
the 99^th percentile 超过统计数据99%的数是多少
blk-mq Linux Multiqueue block layer 内核对ssd随机I/O的优化
message signaled interrupt (MSI)
1.摘要
flash share
在内核中,扩展了系统堆栈的数据结构,传递应用程序的属性(?),包括内核层到SSD固件。
对于给定的属性,FlashShare的块层管理IO调度并处理NVMe中断。
评估结果表明,FLASHSHARE可以将共同运行应用程序的平均周转响应时间分别缩短22%和31%。
1.0 Intro
1.1 现状
网络服务提供商,满足服务级别协议SLA,延迟敏感
某个段时间短可能有大量请求涌入,供应商会超额配置机器以满足SLA
现状:该场景并不常见,因此大部分情况下服务器的资源占用率非常低,能耗比低。
为了解决利用率低,服务器会运行离线的数据分析应用,延迟不敏感,以吞吐量为导向。
因此,在运行了多个进程的服务器上,I/O延迟增高,满足SLA非常困难。
现有的ULL SSD相较于NVMe SSD可以减少10倍的延迟
但是这些ULL SSD在同时运行多个进程下高强度压榨服务器的时候,不能充分利用ULL SSD的优势/表现一般。
the 99th percentile 是0.8ms(apache)
但是当服务器同时运行pagerank的时候,延迟会增加228.5%。
原因:略
从固件到内核优化堆栈的存储。
-
内核级别的增强:
两个挑战
- Linux的blk-mq导致I/O请求队列化,引入延迟
- NVMe的队列机制没有对I/O优先级的策略,因此,来自离线应用的IO请求容易阻塞在线应用的紧急请求,造成延迟。
对于latency critical的请求,绕过NVMe的请求队列。同时令NVMe的驱动通过知晓每个应用的延迟临界匹配NVMe的提交和请求队列。
-
固件层设计:
即使内核级的优化保证了延迟敏感的请求可以获得高优先级,但如果基础固件不了解延迟临界值,ULL特性(类似内存的性能)无法完全暴露给用户。本文中重新设计了I/O调度和缓存的固件,以直接向用户暴露ULL特性。将ULL SSD的集成缓存进行分区,并根据工作负载的属性对每个I/O服务独立的分配缓存。固件动态的更新分区大小并以精细粒度调整预取I/O粒度。
- ULL SSD的新中断处理服务:
当前的NVMe中断机制没有对ULL I/O服务优化。轮询方法(Linux 4.9.30)消耗了大量的CPU资源去检查I/O服务的完成情况。当轮询在线交互服务的IO请求完成状态时,flashShare使用一个仅对离线应用程序使用消息信号中断的选择性中断服务程序Select-ISR。
通过将NVMe队列和ISR卸载到硬件加速器中来进一步优化NVMe completion routine。
各种仿真实验后效果不错,效率提高了22%和31%。
2.0 Background
2.1 存储内核栈
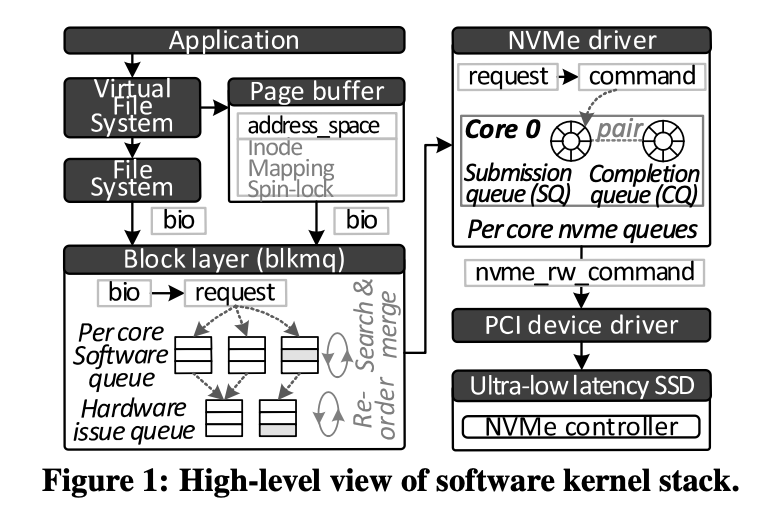
Linux文件系统IO
- bio
- request
- nvme_rw_command
存储堆栈中,NVMe驱动发起的请求通过nvme_rw_command的形式传递到PCI/PCIe设备驱动中。
当I/O请求完成后,发送信号中断,中断直接被写入到中断处理器的中断向量中。被中断的核心选择ISR处理该中断请求,随后NVMe驱动再SQ/CQ中清空相应的记录并将结果返回至上一层(比如blk-mq和文件系统)。
2.2 设备固件栈
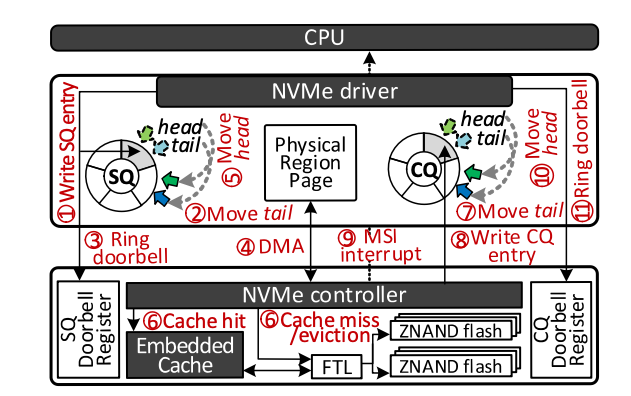
- 收到request
- SQ tail++入队
- 写入SQ门铃寄存器
- 通过DMA读取数据的物理位置
- SQ head++出队
- 将请求转发至嵌入式缓存层或者FTL
- 当出现缺页或者页面替换时,FTL将目标LBA转换成Z-NAND中相应的物理地址,必要时自行GC
- 在完成I/O请求之后,NVMe控制器增加这个CQ的tail,入队
- 通过DMA传输数据,并修改phase tag
- 主机ISR通过搜索队列中检查phase tag,对于有效的phase tag,ISR清除tag位,并且处理剩余的I/O完成请求程序。
- CQ head++出队,在SQ中移除相应的记录,并且写入CQ的head doorbell
3.0 跨层设计
3.1 快速存储的挑战
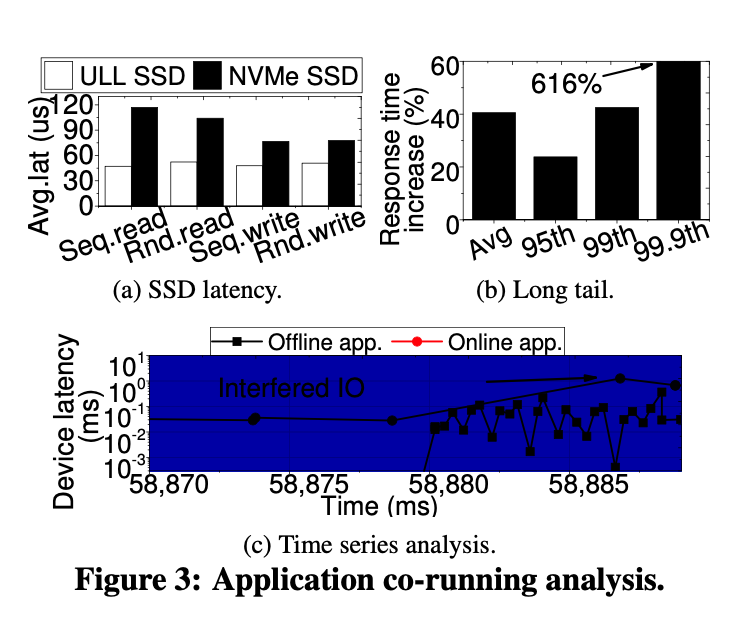
原因是存储栈无法区分来自Apache的I/O请求,及时两个应用需要不同级别I/O的响应。
3.2 预知灵敏响应
为了让内核可以区分I/O 请求的优先级和紧迫程度,修改Linux的进程控制快task_struct.
为了保证有效性,在address_space,bio,request,nvme_rw_command
中都保存工作负载属性,在存储堆栈上打孔。
FlashShare同时提供了一个可以在服务器上配置这些属性的工具。叫做chworkload_attr。
可以方便的修改每个应用的属性并绑定到task_struct中
修改了syscall表arch/x86/entry/syscalls/syscall 64.tbl添加了两个系统调用,可以从task_struct中set/get工作属性。
在/linux/syscall.h中进行注册,并带有asmlinkage标签。
用户通过shell给定特定进程,实现于/sched/cores.c
3.3 内核优化
优化文件系统中的blk-mq和NVMe驱动
blk-mq合并重排请求提高了带宽使用,但是引入了延迟
跳过所有在线应用的I/O 请求
如果离线应用程序的 I/O 请求被 blk-mq 调度到后续在线应用程序发出的同一 LBA,则可能发生危险。
如果两个请求的操作类型不同,blk-mq会将两个请求串联。否则blk-mq会将两个请求合并为一个request并交给NVMe驱动。
为了防止延迟敏感的I/O 被NVMe控制器杀死:
- 为每个核心创建两个SQ队列和一个CQ队列
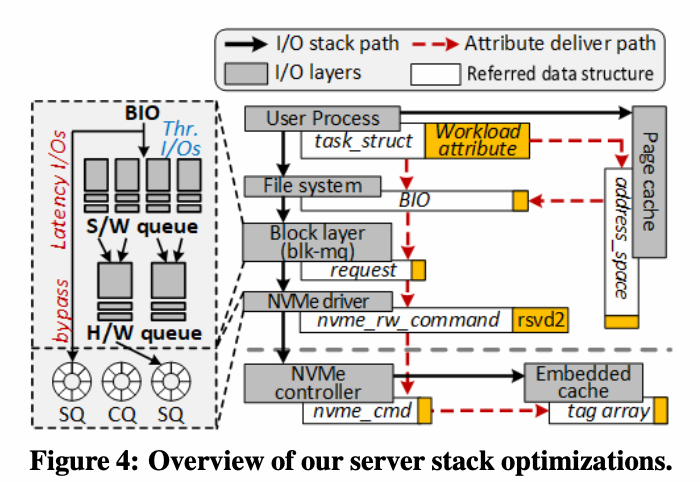
其中一个SQ保存来自在线应用的I/O请求。NVMe驱动程序通过管理员队列发送消息,通知NVMe控制器选择一种新的队列调度方法,该方法始终优先安排该SQ中的请求。
未来避免因优先级带来的饥饿,当该队列中的请求数量大于阈值时,或者没有在规定时间内被满足,NVMe驱动会满足所有离线应用I/O 。
实验表明,队列大小为8或者200us的阈值最好。
4.0 I/O Completion和缓存
采用轮询机制时查询I/O Completion时,内核态占用97%。
带来两个问题:
- 没有为处理I/O 响应单独分配核心,对于多进程下低效
- 我们要减轻处理I/O轮询的核心开销,进一步降低延迟
4.1 中断处理程序
flash share仅对来自在线应用的I/O 请求使用轮询
使用信号处理离线应用
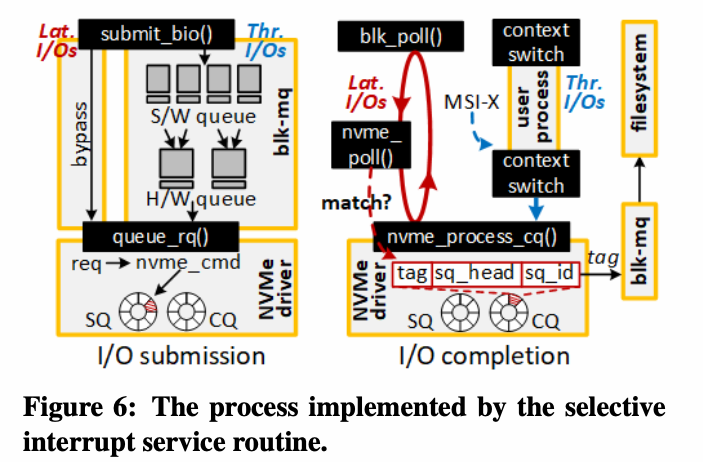
- 修改blk-mq中的
submit_bio(),将由文件系统或缓存的bio插入到mq - 如果bio是来自离线应用的,则插入队列,as normal
- 如果bio是来自在线应用的,blk-mq则调用
queue_rq()将请求发送至NVMe驱动。 - NVMe驱动转换I/O 请求为NVMe指令并非插入到响应SQ队列中
使用Select-ISR,当请求为离线应用时,CPU核心可以通过上下文切换从NVMe驱动中释放。否则,blk-mq调用轮询机制blk-poll()。blk-poll()持续调用nvme_poll(),检查有效的完成记录是否存在于目标NVMe CQ中。如果存在,blk-mq禁用此CQ的IRQ,以至于MSI信号无法再次捕获blk-mq程序。nvme_poll()通过检查CQ中的phase tags查找CQ中的新记录。
具体来说,nvme poll()搜索一个CQ记录,其请求信息与blk poll()等待完成的标签匹配。一旦检测到这样的新记录,blk-mq就会退出在blk poll()中实现的无限迭代,并将上下文切换到其用户进程。
提出I/O-stack accelerator
主要目的是将blk-mq的任务迁移到附属于PCIe的加速器中
可以使得通过上层文件系统生成的bio直接转换成nvm_rw_command。
通过特殊的tag索引搜索队列中的元素,并且代表CPU合并bio
该方法可以减少36%的I/O completion时间。
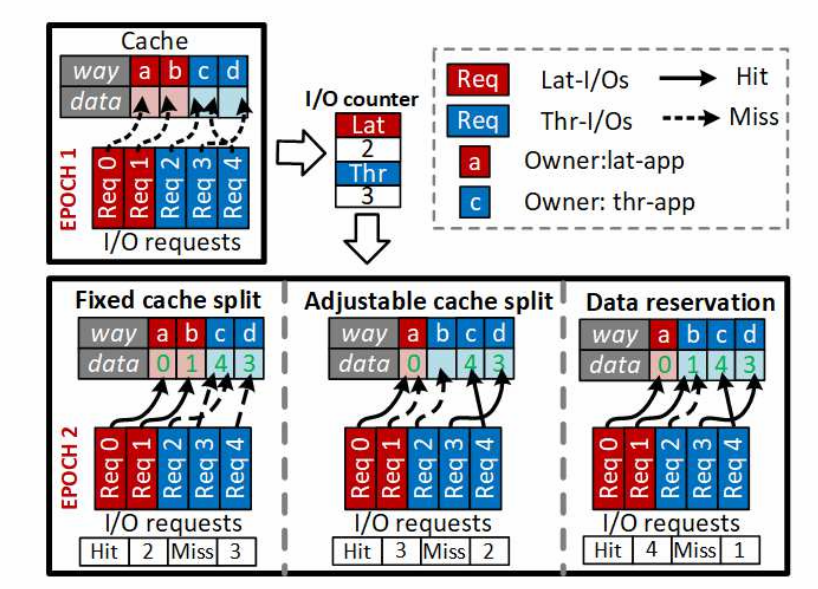
4.2 固件层
创建两个内存分区,一个服务于在线应用,一个服务于离线应用。
三种模式
- 固定拆分缓存
- 根据I/O动态划分
- 数据可保留
4.3 I/O-Stack Acceleration
添加了一个barrier logic,简单的MUX,作为硬件仲裁
引入status bitmap来过滤SQ队列中的记录
- 合并逻辑插入一个行的nvme 指令,status bitmap设置为1
- 如果监测到ULL SSD从I/O SQ中读取NVMe指令,status bitmap设置为0
如果状态位图表明CAM中的请求条目(与目标SQ相关联)无效,CAM将跳过对这些条目的搜索。
5.0 实验
5.1 实验步骤
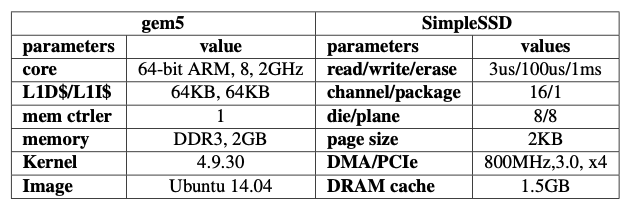
使用gem5系统结构模拟
64位arm指令集
Linux 4.9.30
8核心2GHz
L1 Cache 64KB
2GB Memory
Related Work
将SSD固件转移到主机上,消除冗余的地址转换
根据应用程序特征对缓存进行分区处理,然而不能发挥ULL SSD的作用
从文件系统和block IO设备方面优化移动端操作系统,使其提高SQLite的性能,有局限性,应用程序、ULL SSD
在内核的多个层对写请求进行调度,容易阻塞读请求和ULL操作
根据前台任务和后台任务中的依赖关系,分配优先级,允许后台任务高优先级,IO通常情况下没有依赖关系,效果差,服务器大部分都是多进程
考虑对在线应用设置高优先级,但是没有考虑对IO stack中其他部分的影响