
[FAST'23] HadaFS: A File System Bridging the Local and Shared Burst Buffer for Exascale Supercomputers
HadaFS,一个为超算提供本地和共享Burst Buffer的文件系统
0x00 Intro
现代的超算通过SSD来实现Burst Buffer(BB)layer。
根据部署位置,BB可以分为两种:
- Local BB,作为本地硬盘部署在每个计算节点上,有高伸缩性和性能
- Shared BB,部署在专用节点上,可以被多个计算节点访问,可以共享数据,部署成本低
HadaFS已经部署在了神威新一代超算(Sunway New- generation Supercomputer,SNS)中。支持最大600000用户,最大I/O带宽3.1TB/s。
Burst Buffer作为数据加速层,一般使用SSD。自2016年起,越来越多的超算开始使用Burst Buffer。
对于local BB,有一些局限性:
- 由于难以进行数据共享,Local BB不适用于所有场景,例如N-1 I/O mode,所有进程共享一个文件、workflow
- 由于超算程序之间的I/O负载差异较大,而数据密集型应用的比例较低,造成了大量的资源浪费
- 随着超算规模的扩大,local BB的部署成本未来会急剧升高
相比于Local BB,Share BB便于数据共享,部署成本低,但是在超算上部署也面临许多问题。LPCC将SSD集成到Lustre FS Client,提高read/write性能的一种缓存技术,LPCC存储在Lustre client SSD中的数据必须先刷新到Lustre server才能进行共享。BeeOND类似于LPCC,继承了BeeGFS的可伸缩性和缓存共享限制。
超算的发展使得并行I/O需求增加,BB架构相较于传统GFS有着同样的高性能,但是容量较小,因此BB要与GFS进行整合。目前的BB架构数据迁移的效率很低,浪费了很多计算资源,因此高伸缩性的BB数据管理和迁移也是目前要解决的问题。
为了解决这个问题,作者提出了BB File System–HadaFS。
基于share BB,结合了local BB的伸缩性、性能优势和share BB的数据共享、部署成本低的优点。
- HadaFS提供Localized Triage Architecture(LTA)局部分类架构,解决了shared BB伸缩性不足的问题,实现了超大规模的扩展和数据共享,LTA将所有HadaFS server构建为一个共享存储池,可以在client和server之间灵活的控制并发问题,来保证数据共享。
- HadaFS提出了一个运行时的user-level接口,来保证来自client的I/O请求可以被最近的server处理,类似local BB。
- 为了解决由POSIX接口强一致性导致的性能问题,HadaFS提出了一种包含三种元数据同步机制的全路径索引方法,来解决传统文件系统在复杂元数据的管理上的问题,以及文件系统和应用I/O行为不匹配的问题。使用KV的方法来代替传统的目录树结构。
- HadaFS集成了数据管理工具,帮助用户管理BB中的数据,完成BB和GFS之间的高效数据迁移。
- 提出Hadash,在BB中提供高效的数据查询,加速BB和传统超算存储的数据迁移。
0x01 Motivation && Bg
Motivation
BB可伸缩性和应用行为的矛盾
随着超算百亿亿次计算记录的打破,尖端超算中的I/O并行可以达到数十万,加大了BB在伸缩性上的压力。
目前的一些顶尖超算:
- Frontier使用独立的硬件来分别构造local BB和shared BB,需要使用大量的SSD和高昂的建设维护成本。
- Fugaku使用shared BB,使用软件来提供存储服务,local BB和shared BB使用不同的name space。这种方式是静态的,很难控制在高并发情况下的I/O竞态问题。
- Summit部署local BB,支持数据在应用之间的共享,基于GFS,效率较低。
由于shared BB既可以用于计算节点,也可以用于数据转发节点,作者相信shared BB更适合超级计算机。
复杂元数据管理与应用行为的不匹配
传统的文件系统需要考虑兼容性,因此严格遵循POSIX协议。超算中,计算节点普遍使用read/write,执行目录树访问的次数较少。
因此减轻对POSIX的实现成为很多文件系统的优化方向。由于应用程序的种类很多,如何减少POSIX接口面临巨大挑战。
Wang等人分析了一些HPC应用的行为,整理了几种一致性语义,如下表Table 1

- Strong consistency
- Commit consistency
- Session consistency
- Eventual consistency
系统支持的一致性等级越高,系统的适应性越强。也就是说,当一个系统能够保证数据在不同节点之间保持一致,那么它就能更好地适应不同的应用场景和需求。
需要灵活地选择合适的一致性语义来平衡需求和BB系统的性能。
低效的数据管理
虽然使用BB加速了I/O,但是BB的利用率很低。
BB仅用于I/O的加速,并不永久的存储数据,同时BB的容量相较于GFS很小,因此要考虑BB和GFS之间高效的数据传输。
BB和GFS之间的数据迁移/传输有两种:
- 透明迁移,软件自动以blocks或者file的形式将BB中的数据迁移到GFS,造成了大量不必要的数据传输
- 非透明迁移,计算节点来实现数据迁移,导致计算资源在数据迁移时产生空闲。
这两种数据传输方式都会异步地提前将数据从GFS加载到BB,以达到预取的目的。
然而他们都不能支持用户在程序运行时动态的管理BB数据迁移,不利于提高BB的利用率。
Bg-神威超算架构
SNS神威超算的架构图如下
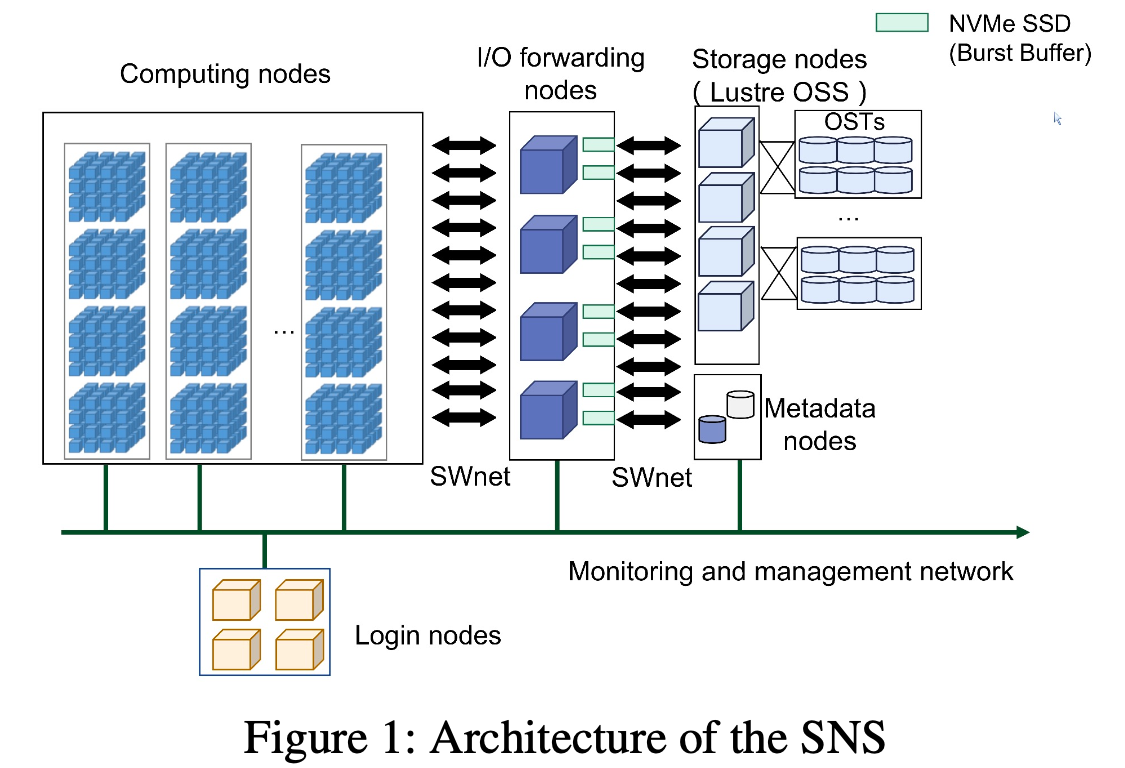
每个计算节点包含一个神威多核处理器SW26010P(自研),采用多种架构,有6个Core Groups,390个计算核心。通过环网相连接。
整个系统有超过100000个SW26010P处理器,通过一种Fat-tree 网络 SWnet连接。
计算节点与I/O转发节点连接,I/O转发节点提供I/O请求的转发或存储介质。
SNS使用类似太湖之光的软件架构(LWFS+Lustre),通过独立的存储网络来链接存储节点,以提供I/O请求转发。
当提供存储服务时,SNS使用HadaFS,I/O转发节点作为HadaFS的server,使用NVMe SSD来处理用户的I/O。
我个人感觉,Burst Buffer就类似于I/O栈中的Page Cache,HadaFS处理的就是Buffer I/O。
0x02 Design
Overview
下图为HadaFS的架构,包括HadaFS client,HadaFS server和数据管理工具。
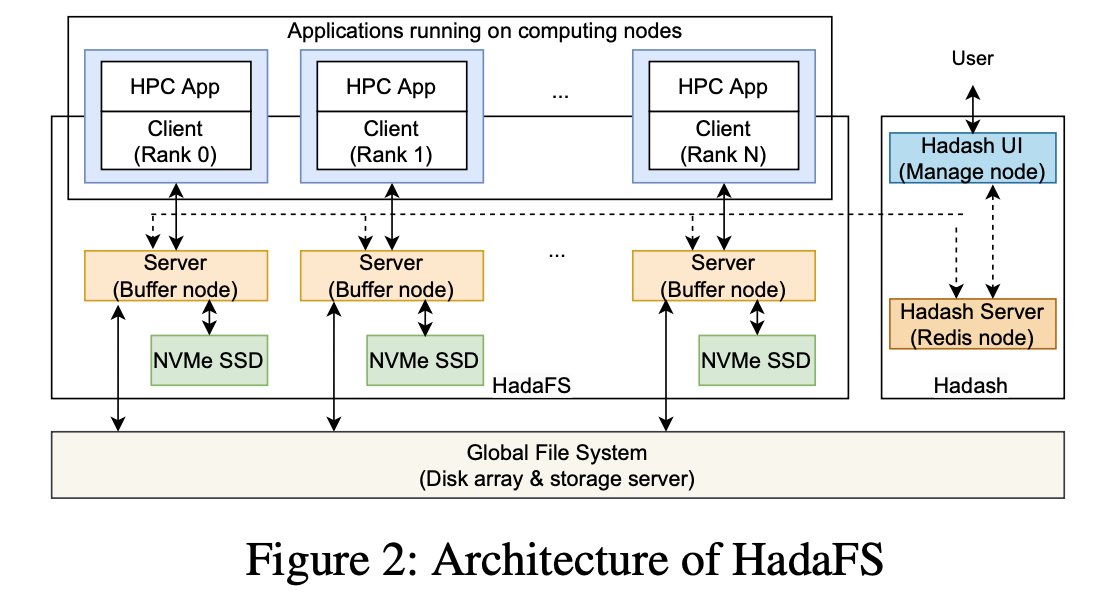
HadaFS作为shared BB文件系统,提供所有client的global view。
HadaFS Client运行于计算节点,并提供静态/动态链接库,用于拦截并转发应用程序的POSIX I/O请求到HadaFS Server,HadaFS client的生命周期取决于应用程序。
HadaFS不支持move,rename,link操作,这些操作很少在并行系统中使用。
HadaFS Server运行于Burst Buffer节点,包含NVMe SSD,提供全局的数据和元数据存储服务。
在HadaFS中,每个文件与两种服务器有关。
- 数据存储服务器:通过NVMe SSD上的基本文件系统存储HadaFS文件数据。
- 元数据存储服务器:通过高性能的数据库存储HadaFS文件的元数据(使用RocksDB)。
Hadash是数据管理工具,运行于用户登录节点,用于管理HadaFS和GFS之间的数据迁移。
LTA (Localized Triage Architecture)
kernel在实现完整POSIX接口和处理I/O时有较大的开销,kernel bypass是一种常用手段。
在高并发的情况下,kernel bypass可能会导致服务不稳定。
例如,计算节点有24CPU核心,所有的进程只需要进行一次挂载就可以访问运行于kernel mode的文件系统client。相反,每个进程需要在用户层挂载一个文件系统client。两种方法各有优点和局限性,HadaFS通过LTA将两种优点进行整合。
HadaFS直接挂载Client到应用,实现kernel bypass。
为了防止单个server处理的FS client过多,HadaFS采用每个client只连接一个server的方法。
对于一个HadaFS client,与之相连的HadaFS server被称为bridge server,bridge server负责处理client的所有I/O请求,并根据client I/O request的offset和size写入数据到文件。每个文件对应在bridge server ext4 文件系统中的一个独立文件。当client需要访问其他服务器的数据时,文件必须通过bridge server转发。
如果一个bridge server的空间已满,所有的client将自动切换到其他server。
为了保证大部分I/O请求在bridge server中处理并减少转发的次数,HadaFS提出了mount(mount_point, Seq)接口来允许应用在必要时(自己选择bridge server有优势时)控制bridge server的选择。
- mount_point表示挂载点,在HadaFS中这是一个文件路径的前缀
- Seq可以根据应用数据共享模式、网络拓扑、适应应用程序数据和系统架构并行性的其他因素来灵活设置。Seq有三种类型:
- 应用程序
MPI_RANK,client将会按照轮询的方式连接server。适用于应用被多次提交到不同的计算节点的情况,来保证每个应用可以准确连接到原先的bridge server,减少数据转发。 - 计算节点ID,用于匹配计算节点和BB节点的拓扑结构,保证计算节点可以将数据存储到网络中最近的BB节点。
- 根据应用数据分发和共享需要设置,每个client可以显示指定要连接的server,应用可以通过灵活的控制client到server的映射改善数据访问的效率
- 应用程序
LTA通过bridge server作为local BB,还实现了shared BB的功能(数据共享)。
mount_point,Seq可以通过环境变量设置,因此,HadaFS可以通过在应用程序开始之前加载HadaFS lib以提前读取环境变量来支持用户的透明挂载。
为了充分利用HadaFS的高性能,尤其是read性能,建议用户执行实现client-to-server的映射关系,减少数据转发。在挂载HadaFS之后,应用可以直接调用POSIX文件接口来实现I/O。
Namespace && metadata handing
为了改善伸缩性和性能,HadaFS不使用目录树的索引机制,使用类似CHFS和Vesta的full-path索引。
对一个HadaFS文件,其数据保存在client中的bridge server,元数据存储位置由路径的hash决定。
文件的元数据以KV的方式存储,每个文件路径都有全局唯一的ID作为key。
HadaFS client直接通过文件绝对路径的前缀来检查文件是否符合要求。
当多个文件需要访问,负载可以分发到多个服务器,改善元数据访问的性能。
HadaFS的元数据兼容Linux的权限结构,包括name,ino,owner,mode,timestamp等。HadaFS将这些信息分成四类:
- 维护文件的创建信息,name,owner,mode等
- 维护文件的访问信息,file size,modification time,access time等
- ❌因为使用全局唯一ID,HadaFS不需要维护,ino,stdev等信息
- 文件分段的位置信息,是一个有序链表,链表通过offset排序,每个元素包括server name,fragment offset,size,writing time等信息
HadaFS server维护两种元数据数据库,数据结构如下图:
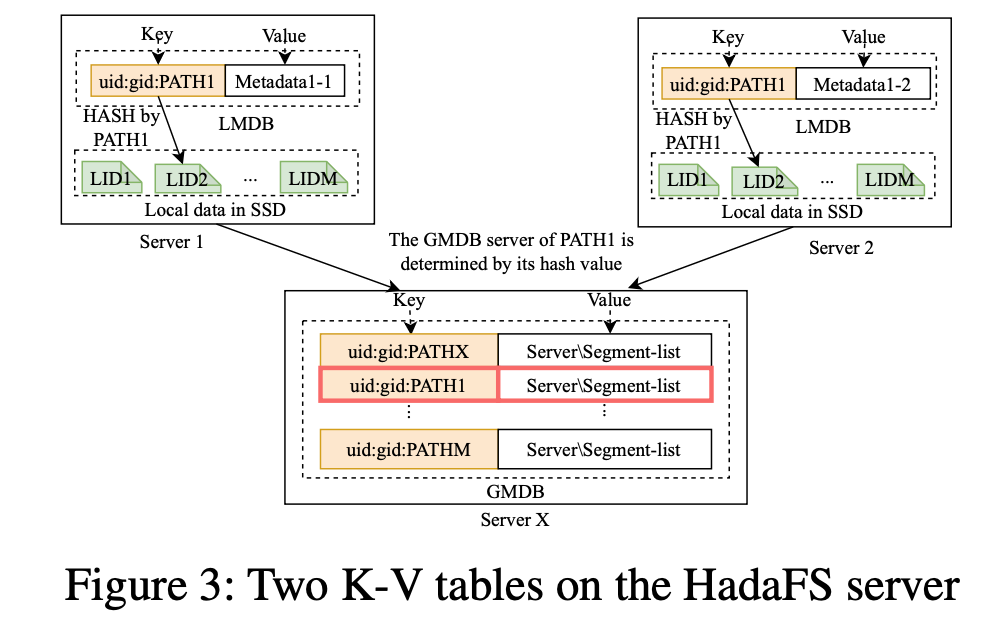
一个数据库为Local Metadata Database LMDB,保存第一和第四种元数据类别,文件的local id(LIB)是文件的本地路径。
另一种为Global Metadata Database,保存第一、二、四种元数据(第三种不需要维护),HadaFS文件的元数据存储在唯一的GMDB,通过文件的全路径hash索引。
两种数据库基于RocksDB,该数据库不支持多线程写,但这并不是性能瓶颈。
两种元数据库的Key构造包含:用户的UID、GID、PATH,GID和UID用于前缀字符串检索。
对于多对多N-N I/O模式,每个client写入到独立的file,并且存储在LMDB的元数据和存储在GMDB的第一、四类元数据匹配。
对于多对一N-1I/O模式,多个client需要共享一个文件,可能使用不同的HadaFS bridge server,这时,GMDB负责从多个LMDB合并文件的元数据。
在文件read/write时,LMDB记录文件元数据的改变,维护一个包含本地数据段位置信息的有序链表,并将数据发送到相应的GMDB。GMDB负责维护全局的文件数据段链表,来保证全局的数据共享。
HadaFS I/O Control && Data Flow
介绍HadaFS种的控制流和数据流。下图展示了3个HadaFS Client和3个server的关系。
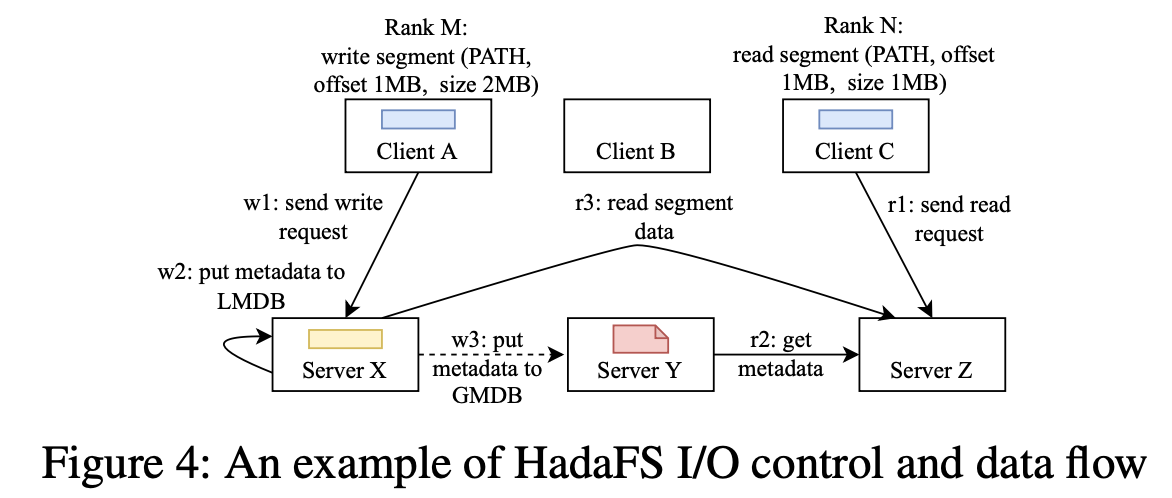
- Client A发起I/O请求,创建文件F1并写入100MB数据。数据将会直接写入Client A的Bridge server:X
- Server X写入F1文件的元数据信息和位置信息到LMDB
- 基于F1的文件路径,处理好F1的元数据信息。Server X写入F1文件的元数据信息和位置信息到Server Y上的GMDB。
- Client C发起读取文件F1的I/O请求
- Client C的Bridge Server Z接受I/O请求,从Server Y根据F1的路径获取F1的元数据和位置信息
- Server Z从Server X读取数据,并转发到Client C
对于局部写和全局读是有利的,尤其是对于需要频繁输出检查点的应用。
对于读敏感的应用可以自行维护client到bridge server的映射表,减少数据转发,通过mount接口实现高性能。
HadaFS除了限制了每个server连接的client数量,减少了性能抖动,还为存储系统充分支持应用程序的并行性奠定了基础。
Data Management Tool
现有的BB方案,例如LPCC,可能会导致迁移大量的临时数据。Datawarp要求应用程序在其源代码或脚本中指定BB和GFS之间的迁移,这通常是一种静态迁移方法,并要求计算节点参与迁移。
HadaFS中,用户使用Hadash以目录树的视图来获取和管理文件,视图根据功能分为两类,元数据信息查询和数据迁移。
元数据信息查询提供如下指令:ls,du,find,grep等。ls和find可以在目录树视图查询文件信息。Hadash从metadata-数据库获取信息,并以Linux shell中常用的命令的形式展示这些信息。
其他触发数据迁移的指令,例如rm、get、put等,Hadash通过Redis pipeline发送指令到HadaFS server中的数据管理模块,然后每个HadaFS server的数据管理模块使用LMDB处理本地数据请求,并行地执行这些指令。
Redis Pipeline就是一组Redis命令的组装,避免频繁的执行命令的Request/Response,类似事务的概念,还可以使用Lua脚本实现类似的功能。
下图是从HadaFS到GFS进行数据迁移的控制流。
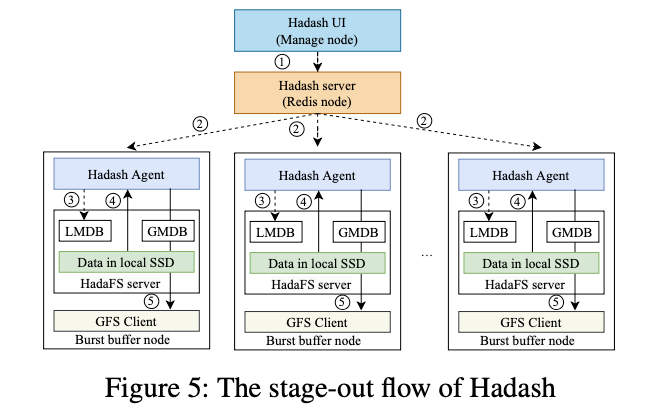
- 用户通过UI发起数据管理指令到Hadash server
- Hadash Server接收并转发指令到BB节点的所有Hadash代理
- Hadash代理解析指令,通过LMDB获取文件相应的链表信息,在本地SSD读取文件
- 最终,Hadash代理写入这些文件到GFS
当所有的文件写入完成时,Hadash代理通过另一个Redis Pipeline返回success,Hadash将通知用户迁移已经完成。
如果将要被迁移文件正持续追加写入,Hadash将持续拷贝新写入的数据,类似于Linux默认的数据拷贝机制cp。
Hadash使用前缀匹配方法来展示目录树,可以直接通过LMDB本地执行,减少了对GMDB的影响。
Hadash使用分布式管理方法来实现数据的本地化管理。该方式主要的瓶颈在GFS,性能根据BB节点的数量增长。
HadaFS优化
持久化语义和元数据优化
HadaFS采用宽松的持久化语义,不支持在client和server中缓存数据,而是基于ext4文件系统缓存机制,持久化语义取决于元数据的同步。
HadaFS为不同的应用场景提出了三种元数据的同步机制,避免出现传统文件系统复杂的设计。
- mode 1:异步地更新所有元数据(eventual consistency),在文件的打开、删除、读写期间,所有的操作都先在bridge server本地执行,然后元数据将被异步从LMDB更新到GMDB。该模式的性能最高,相当于为计算节点提供本地存储,适用于没有数据依赖性的场景
- mode 2:同步地更新部分元数据,异步地更新另一部分元数据(session/commit consistency semantics)。第一类元数据(name,owner)将在文件被创建时同步地更新。第二类元数据(file size,modify time)将在文件读写时被异步地进行更新,或通过flush操作同步地更新。该模式为默认方式,可以平衡读写文件读写的性能
- mode 3:在所有的open、read、write操作时同步元数据(strong consistency semantics,HadaFS不支持覆盖写)。所有的server要先获取文件位置来保证第一类元数据的同步,诸如open、write、read、flush的操作需要同步第二类元数据
HadaFS使用全路径索引和bridge server,不需要分布式锁,对于使用N-N I/O的应用,不会产生数据冲突,然而对于N-1写模式,HadaFS需要先将数据写入到每个Bridge Server,因此不支持覆盖写,原子写只在mode 3中支持。
优化共享文件
LTA架构适合N-N I/O模型,对于N-1 I/O模型,HadaFS使用类似ADIOS BP的文件布局。先将数据写入到独立的bridge server,再由GMDB维护文件的元数据(BP group index)。一个共享的文件可以存储在多个服务器中,read/write可以被转换成并发的read/write。
HadaFS以文件的形式存储数据,因此可能会产生碎片。例如,100000个进程并发地写同一个文件,每个进程写入6次,在完全随机的情况下可能产生600000个文件碎片。HadaFS使用一个根据offset排序的链表,合并相同bridge server相邻的段位置信息。读写时的段插入和获取操作时间复杂度为LogN,N为文件段的数量。
所有的元数据同步机制支持N-1模式,元数据只存储在GMDB中。
避免干扰
超算中不同的任务之间存在资源竞争,造成I/O干扰。HadaFS中主要是由于不同的client共享一个server,可以通过用户自行决定连接的server,改善该问题。
HadaFS还提供了自动调节工具,通过监控系统来优化I/O,自动指定连接的BB资源,设置环境变量,选择合适的元数据同步机制,达到隔离BB资源的目的。
超算中的HadaFS
HadaFS已经在SNS中部署了一年多,下图为HadaFS的部署架构图。
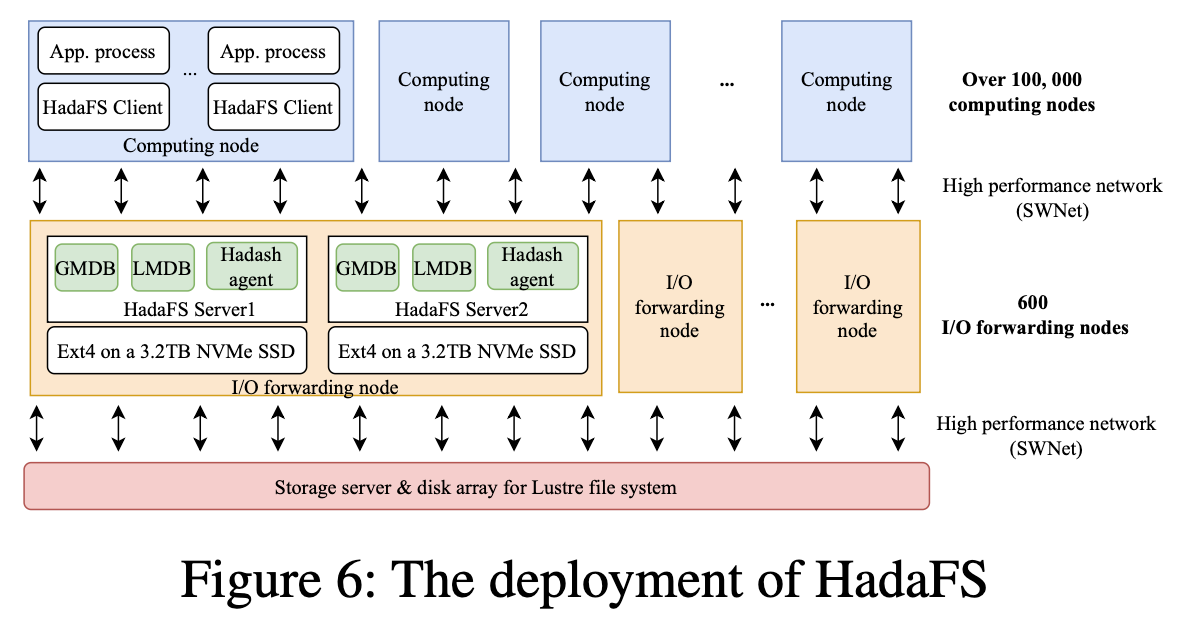
每个I/O转发节点有两个HadaFS server,每个HadaFS server使用一个NVMe SSD来支持文件数据的存储和元数据(LMDB、GMDB)。
容错的代价是很高的,应用会周期性写入检查点来减少数据恢复的开销,如果一个BB节点失效,只要SSD没有损坏,HadaFS就可以恢复,为了减少数据恢复的成本,HadaFS周期性地备份关键数据到GFS,在HadaFS部署的一年多时间里,总共产生了15次BB节点的失效,其中没有SSD的故障。
0x03 Evaluation
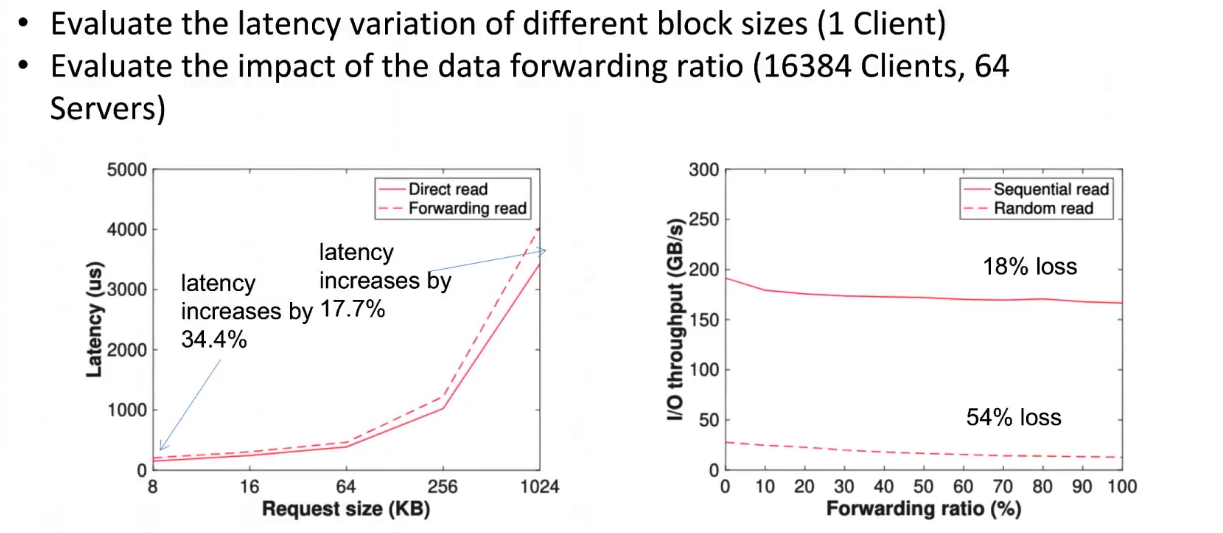
数据转发性能
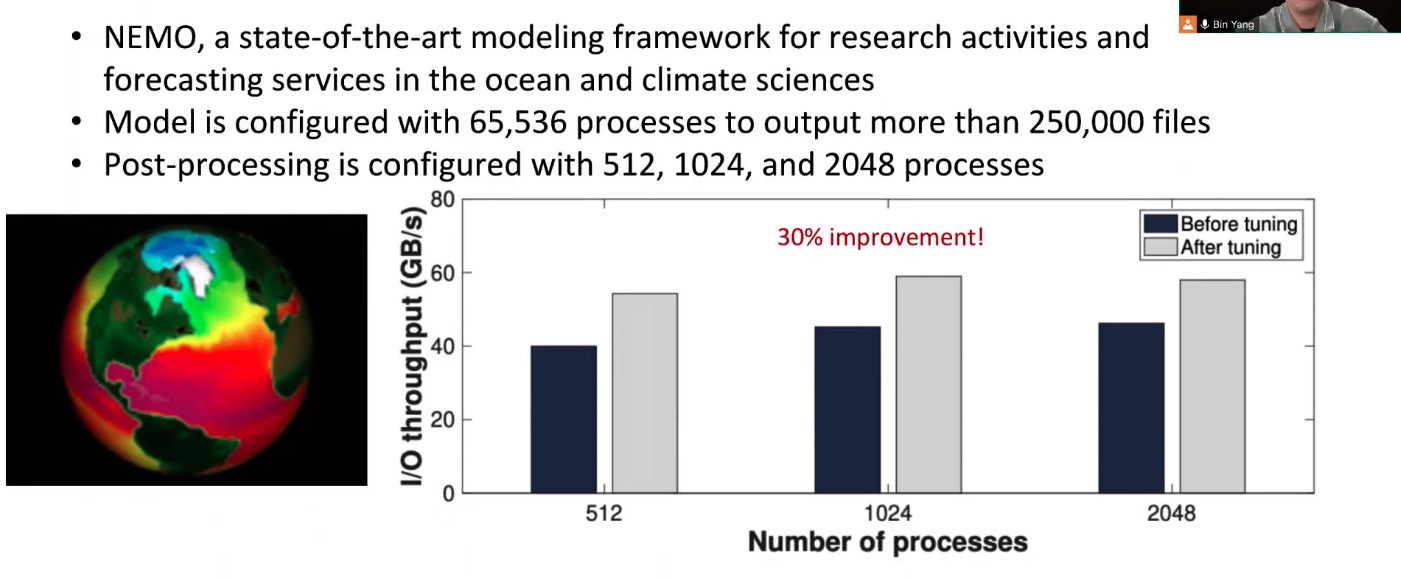
对于大气科学研究模型NEMO,HadaFS性能如下,说明了对于需要共享文件的程序,HadaFS可以提升其吞吐量。
元数据访问性能
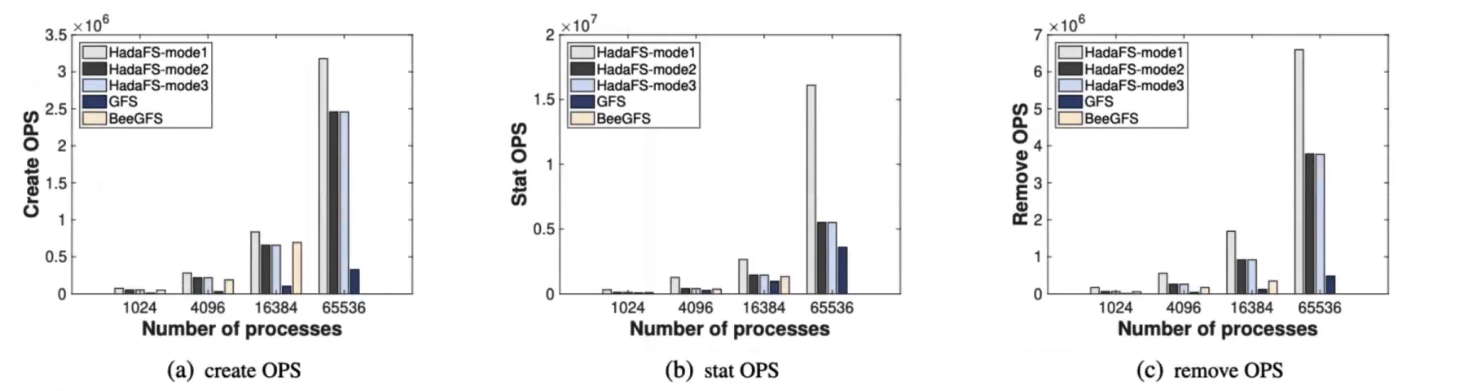
MDTest
Client-Server比例为256:1
竞品为BeeGFS,配置与Hada相同,GFS使用132 OSS和4 MDS
测试了Create/Stat/Remove操作的OPS
BeeGFS由于集群管理服务的限制不能达到65536进程
数据访问性能
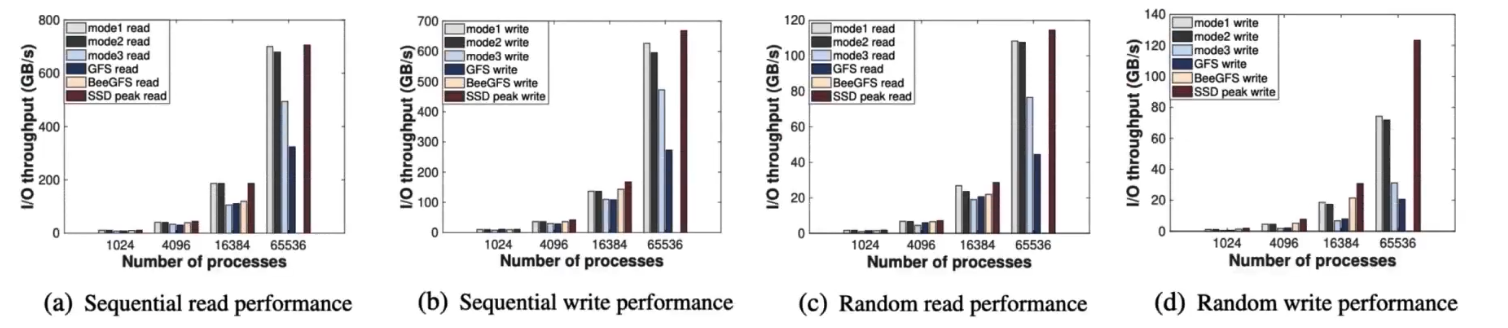
IOR测试I/O带宽
竞品为BeeGFS和GFS,配置同metadata测试
BeeGFS和mode1、mode2性能相当,但是不能达到65536进程数
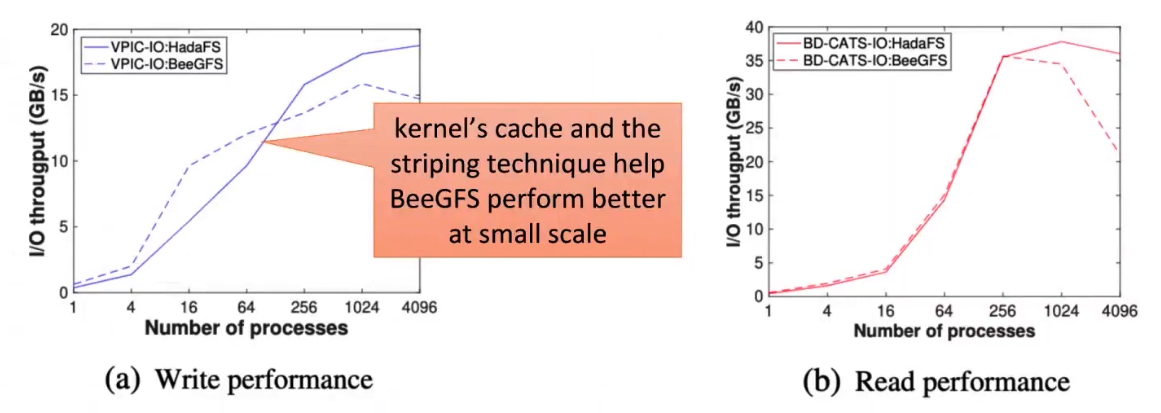
使用VPIC-I/O和BD-CATS-I/O测试共享文件的读写访问性能
HadaFS和BeeGFS使用16个服务器,可以看出低进程情况下二者性能相当,但是BeeGFS的伸缩性较差,HadaFS通过LTA来避免I/O冲突。
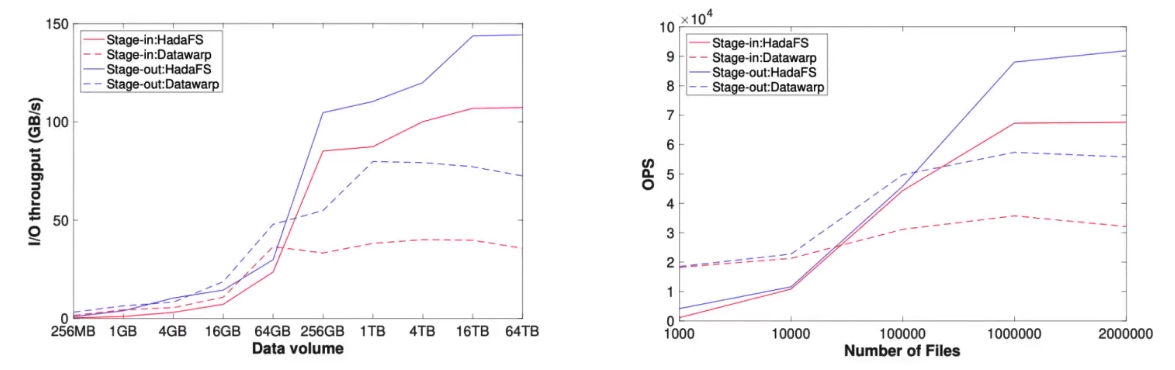
数据迁移性能
HadaFS使用256台服务器
Datawarp使用4096进程
随着文件大小和数量的增加,HadaFS的性能逐渐优于Datawarp
I/O干扰
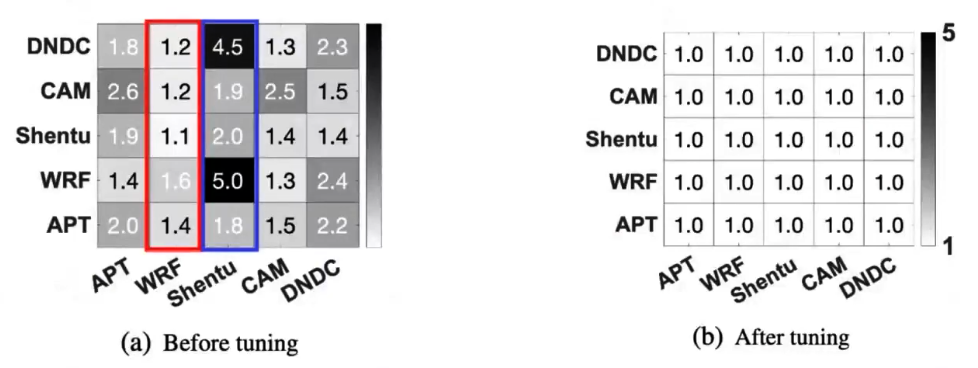
使用五种程序进行测试:
- DNDC:农业生态系统的生物地球化学程序
- CAM:气候模拟、全球大气模型
- Shentu:高伸缩性图引擎
- WRF:天气预测系统
- APT:动态粒子仿真程序
下图深色色块代表程序速度降低的指数,每一行代表左侧的应用受到下放程序的影响
由于可以灵活的选择与client连接的server,可以避免一定的I/O干扰
0x04 Conclusion
HadaFS已经用于新一代的神威超算中,基于Shared Burst Buffer,使应用既可以单点访问BB,也可以通过HadaFS实现对文件同时进行读写,并实现了高性能。