
Linux Block I/O Stack简介
本文将从操作系统内核层面去介绍Linux I/O 栈
==涉及Linux内核的部分主要为Linux 2.6==
Linux I/O 栈概述
Linux I/O 栈的简图如下
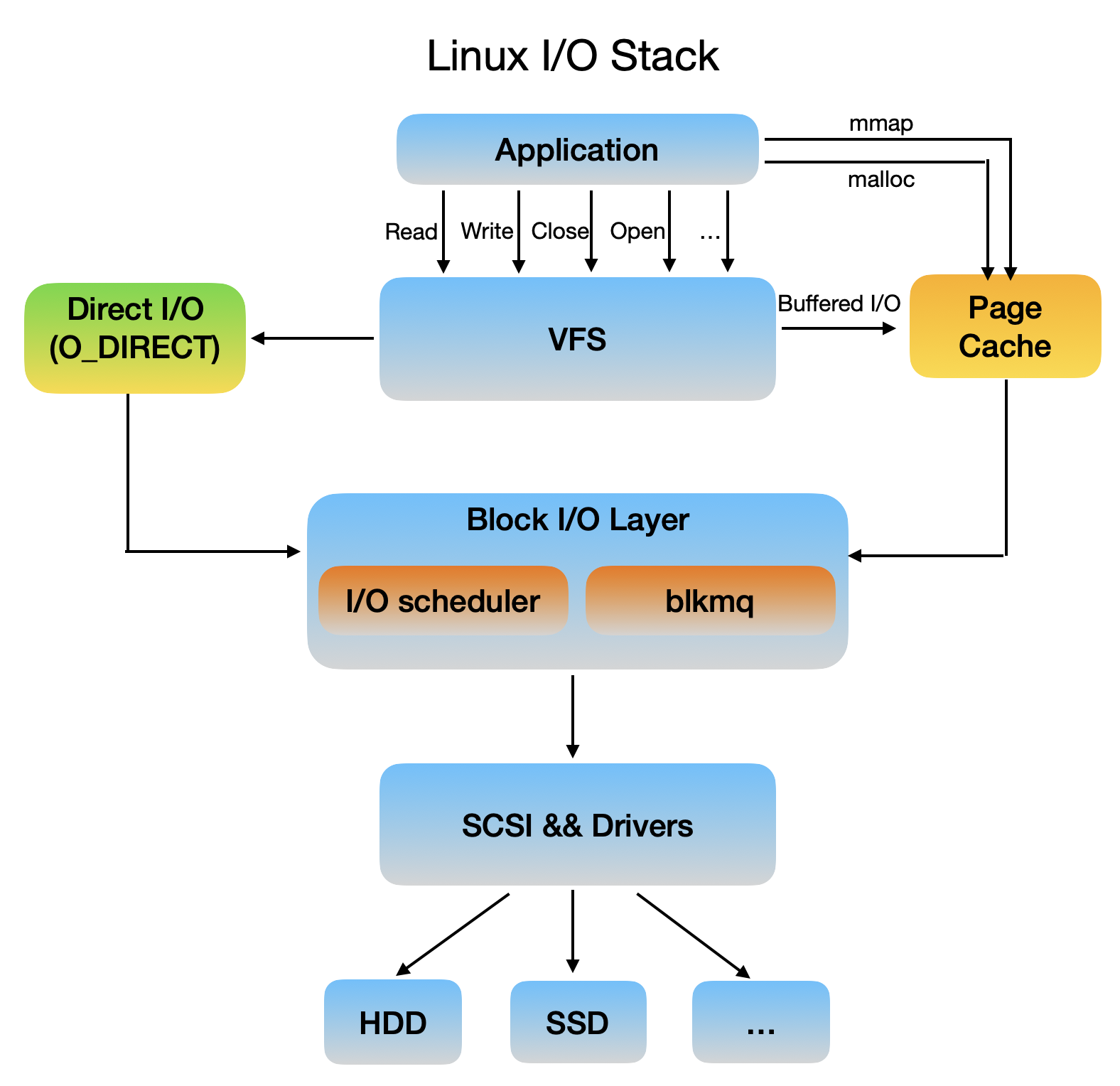
下面分别简述各个层次的功能
应用程序层
应用程序层通过系统调用向VFS发起I/O请求
VFS层
VFS主要向用户空间提供文件系统层面的接口,同时向不同的文件系统实现提供抽象,使他们可以共存。VFS将文件系统在用户层面进行抽象,便于用户对文件进行操作。
来自应用程序的请求到达VFS后,VFS会创建包含I/O请求信息的结构体提交给块I/O层。
Linux在文件系统层提供三种IO访问的形式:Buffered IO、MMap 、Direct I/O。
-
Buffered I/O:这种访问情况下文件数据需要经过设备、Page Cache、用户态缓存,需要进行两次的拷贝动作。
-
MMap:内存映射技术,将内存中的一部分空间与设备进行映射,使得应用程序能够向访问普通内存一样对文件进行访问。使文件数据仅经过设备、Page Cache即可直接传递到应用程序。
-
Direct I/O:采用Direct IO的方式可以让用户态直接与块设备进行对接,跳过了Page Cache,从硬盘和用户态中拷贝数据,提高文件第一次读写的效率,若之后需要重复访问同一数据,需要消耗比利用Page Cache更多的时间,一般用于数据库系统。
块I/O层
系统能够随机访问固定大小的数据片的设备被称为块设备,最常见的块设备为硬盘(机械硬盘,固态盘),对块设备的访问通常是在其内部安装文件系统。操作系统为了对其访问和保证性能,需要一个子系统来对块设备和对块设备的请求进行管理。
SCSI底层 && 设备驱动层
块I/O层将请求发往SCSI层,SCSI就开始真实处理这些IO请求,但是SCSI层又对其内部按照功能划分了不同层次:
-
SCSI高层:高层驱动负责管理disk,接收块I/O层发出的IO请求,打包成SCSI层可识别的命令格式,继续往下发
-
SCSI中层:中层负责通用功能,如错误处理,超时重试等
-
SCSI低层:底层负责识别物理设备,将其抽象提供给高层,同时接收高层派发的SCSI命令,交给物理设备处理
更正:对于传统的块设备而言,服务器通过SCSI协议、SAS接口连接,个人电脑通过AHCI协议/SATA接口连接,目前主流的发展方向为NVMe协议/M.2接口。
物理外设层
在I/O中一般为磁盘、固态硬盘等存储设备
VFS简介
Intro
VFS主要向用户空间提供文件系统层面的接口,同时向不同的文件系统实现提供抽象,使他们可以共存。
VFS将文件系统在用户层面进行抽象,便于用户对文件进行操作。
VFS中有四个最重要的数据结构,分别是dentry、file、inode、superblock,下文对他们分别进行介绍。
Directory Entry Cache (dcache)
VFS提供了open,stat,chmod等系统调用,需要向他们提供文件的路径名,VFS会在dcache中去查询。
dcache提供了非常快的查找机制将路径名转换到一个具体的dentry目录项,缓存的目录项存储在RAM中并且不会持久化到硬盘。
在没有命中缓存时,VFS会通过查找和加载inode来创建dentry缓存,最终实现可以通过path name查找到对应的dentry目录项。
The Inode Object
每个独立的dentry都有一个指向一个inode的指针,inode一般保存在disc(块设备文件系统)中或者内存中(虚拟文件系统)。disc中的inode在被请求或修改时会复制到内存中,并在修改后回写到disc。多个dentry可以指向同一个inode(硬链接)
对于查找inode的请求,VFS在父目录的inode调用lookup函数。
The File Object
在打开一个文件时,需要分配一个文件结构体(内核层面对file descriptor的实现),结构体内容的创建通过dentry指针来获取,文件结构体存储在进程的文件描述符表中。
对文件的读写、关闭通过用户空间的fd来操作正确的文件结构。
只要文件打开,它就会保持对dentry的使用状态,这同时意味着inode仍在使用。
The Dentry Object
目录项纪录子文件和子目录的名称
每个目录项的结构
| 类型 | 大小 | 字段 | 描述 |
|---|---|---|---|
| __le32 | 4bytes | Inode | inode编号 |
| __le16 | 2bytes | Rec_len | 目录项的长度 |
| __u8 | 2bytes | Name_len | 文件名长度 |
| __u8 | 2bytes | File_type | 文件类型 |
| char[EXT2_NAME_LEN] | 最大255个字符 | Name | 文件名 |
所有目录都包含的目录项包括当前目录和上级目录:.,..
要对文件名进行4字节对齐,后面补\0
所有目录项顺序拼接组成目录信息,在进行查询时可以使用rec_len来计算偏移量,便于查找目录中的文件(顺序遍历)
The SuperBlock Object
superblock对象表示一个挂载的文件系统,存储有关文件系统的相关信息
注册和挂载一个文件系统
使用如下的API
|
|
文件系统的挂载可以通过->mount()方法将新的文件系统挂载到挂载点,当pathname解析解析到挂载点时,会跳转到被挂在文件系统的root。
内核所注册的文件系统在/proc/filesystems文件中
file_system_type结构的定义如下
|
|
mount()方法有以下几个参数
|
|
Page Cache
页高速缓存(Page Cache)是Linux内核所使用的主要硬盘高速缓存。在绝大多数情况下,内核在读写硬盘时都引用页高速缓存。新页被追加到页高速缓存以满足用户态进程的读请求。如果页不在高速缓存中,新页就被加到高速缓存中,然后用从硬盘读出的数据填充它 。 如 果内存有足够的空闲空间 ,就让该页在高速缓存中长期保留 ,使其他进程再使用该页时不再访问硬盘。
同时, 在把一页数据写到块设备之前,内核首先检查对应的页是否已经在高速缓存中, 如果不在,就要先在其中增加 一个新项,并用要写到硬盘中的数据填充该项。I/O数据的传送并不是马 上开始,而是要延迟几秒之后才对硬盘进行更新,从而使进程有机会对要写人硬盘的数据做进 一步的修改 (内核执行延迟的写操作)。
几乎所有的读写都依赖Page Cache,除非指定了O_DIRECT标志位,此时I/O将使用进程用户态地址空间的缓冲区,一般数据库应用会使用此方式。
对Page Cache中页的识别通过索引节点和在相应文件中的偏移量来实现。
主要数据结构
Page Cache中的核心数据结构是address_space,该对象在页面所属的inode中,由于多个页面可能属于同一个所有者,因此多个页面可能被连接到同一个address space,该对象同时还将所有者的页面和对页面的操作建立连接。
有关页面的操作主要有以下几个:
- ==writepage== 写操作,将页写入到硬盘映像
- ==readpage== 读操作,将数据从硬盘映像加载到页
- sync_page 在所有者的页面已经准备就绪后,启动I/O数据的传输
- wirtepages 把指定数量的所有者脏页写回硬盘
- ==prepare_write== 为写操作做准备(硬盘文件系统使用)
- ==commit_write== 完成写操作(硬盘文件系统使用)
- …
基数树 Radix Tree
基数树类似于字典树,通过要查找的ID的二进制序列,来一级一级的进行查找,为了减少树的高度和叶子非结点个树,可以使用2 bit或者4 bit作为树的结点。
在内核中,Radix Tree的叶子结点保存了指向所有者页描述符的指针。
Page Cache 中的每个文件都是一棵基数树(radix tree,本质上是多叉搜索树),树的每个节点都是一个页。
内核通过把页索引转换为Radix Tree中的路径,使用Radix Tree来快速搜索页描述符所在的位置。内核通过页描述符可以确定页面是否为等待刷新到硬盘的脏页或其中数据的I/O传输是否正在进行。
Radix Tree中的每一个叶子节点指向文件内相应偏移所对应的Cache项
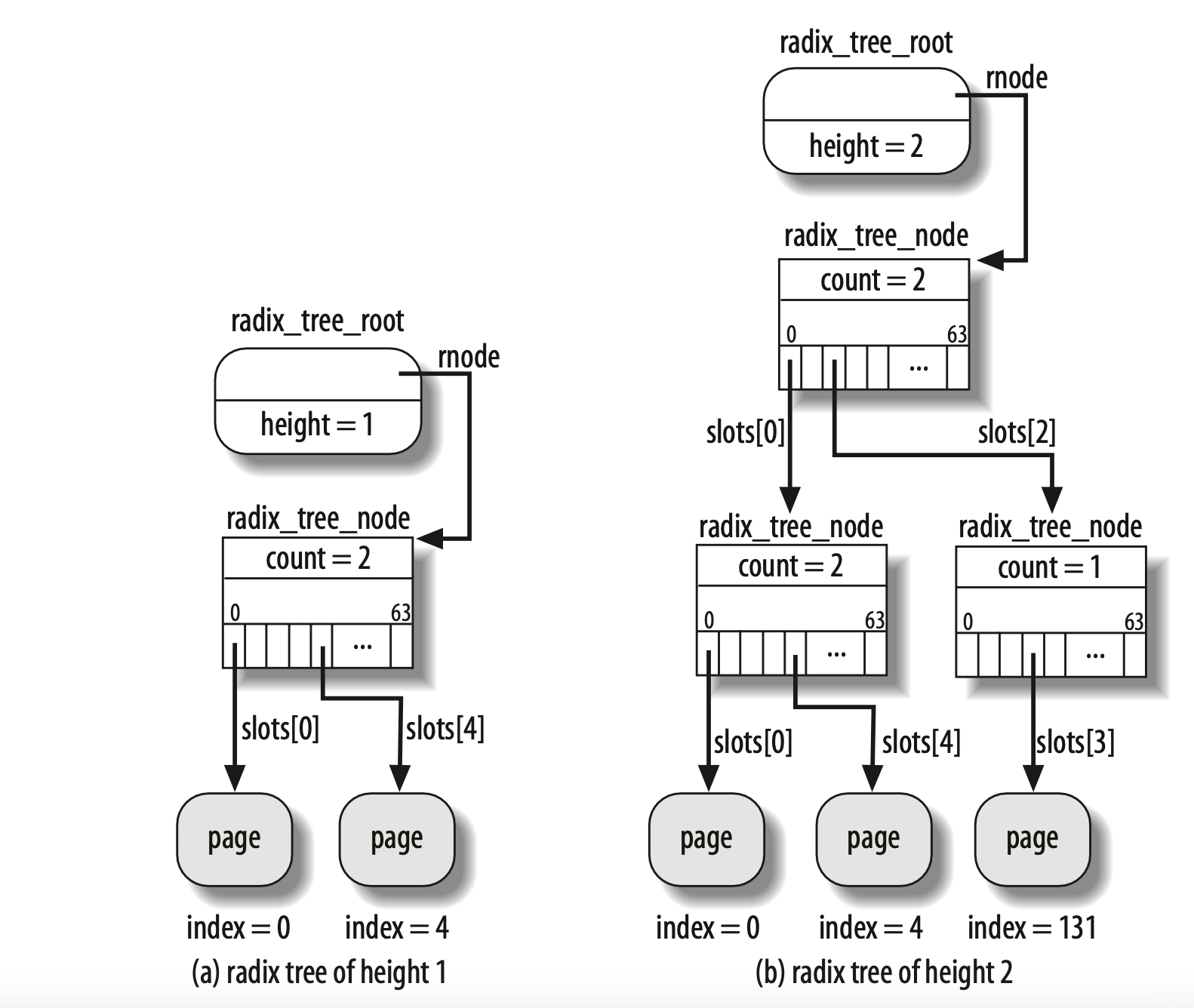
Page Cache处理函数
find_get_page()
传入 address space对象指针和便宜了,获取自旋锁,在Radix Tree中搜索具有指定偏移量的叶子结点,若成功找到,会增加页面使用计数器,释放自旋锁,并返回页描述符的指针,否则将释放自旋锁并返回NULL。
add_to_page_cache()
传入页描述符地址,address space对象的address mapping字段,页索引在地址空间的偏移量,为Radix Tree分配新节点所使用的内存分配标志gfp_mask,插入成功则返回0
remove_from_page_cache()
获取自旋锁、关闭中断后在Radix Tree中删除节点,返回删除页的描述符指针,page->mapping字段设置为NULL,将所缓存页的page->mapping->nrpages计数器值减1,最后释放自旋锁,打开中断。
read_cache_page()
确保Page Cache中包括指定页的最新版本,首先检查页面是否存在,若不存在则新申请分配空间,调用add_to_page_cache插入相应的页描述符,调用lru cache add插入到该地址空间的非活跃LRU链表中。
在保证页面存在于Page Cache后,使用mark page accessed记录页面已经被访问过,若PG_uptodate标志位0,则页面不是最新的,需要从硬盘重新读取该页
Buffer Cache
在Linux内核2.4版本之前,Buffer Cache和Page Cache是独立的,因为操作系统对硬盘等块设备的读写是基于块的,而非页,文件的数据在Page Cache中缓存,硬盘的块数据在Buffer Cache中缓存。但是这种表示方式效率非常低,自2.4版本的内核开始,二者开始统一表示。
因为VFS和文件系统都是通过块Block来组织硬盘上的数据,因此Buffer Cache必须存在,目前它作为Buffer Page存储在特定的页中。
对于文件这种通过Page Cache来表示的数据,通过Page Cache来表示Buffer Cache,而对于文件的metadata,直接使用Buffer Cache来表示。
脏页的处理
在进程修改了页面数据后,该页面就成为了脏页,并将脏页刷新到块设备上的操作延迟,这样可以显著提高系统的性能。
为了防止硬件错误、掉电等情况导致RAM内容的丢失,以及RAM容量过大的需求,在以下情况主动刷新脏页到硬盘中:
- Page Cache太满,或脏页数量太多
- 脏页已经存在了较长的时间
- 进程请求对块设备或文件的变化进行刷新(sync、fsync和fdatasync系统调用)
文件的访问
文件的访问一般有五种模式:
- ==规范模式==:由系统调用read和write来读写,read将阻塞调用进程,直到数据被拷贝到用户地址空间,write则在数据拷贝到Page Cache后立即结束
- ==同步模式==:
O_SYNC标志为1,影响写操作(读操作总是阻塞的),将阻塞写操作,直到数据被有效的写入硬盘。 - ==内存映射模式==:文件打开后,通过系统调用
mmap将文件映射到内存中,此后文件成为完全保存在RAM中的字节数组。 - ==直接I/O模式==:O_DIRECT标志为1,任何读写操作都在用户地址空间和硬盘间进行传输,直接跳过Page Cache。
- ==异步模式==:该模式下,文件可以通过一组POSIX API或者Linux系统调用来进行访问,异步模式下数据传输请求不阻塞调用的进程,而是在后台执行。
读文件
内核实现了read()系统调用为进程提供文件的读取功能,入口为sys_read()需要提供三个参数
- 文件描述符
- 保存数据的缓冲区
- 读取字符数目的长度
对于VFS而言,首先根据文件描述符编号,内核(使用fs/file_table.c中的fget_light()函数)从进程的 task_struct中找到与之相关的文件实例,file_pos_read()函数确定读取当前文件的位置,并返回一个参数file->file_pos,实际的读取操作通过vfs_read()函数来执行,该函数会判断文件是否有file->f_op->read方法,从而确定后续使用的函数,若不存在则会调用do_sync_read函数。最后通过file_pos_write函数来记录文件新的读写位置,通过修改file_ops的值来实现。
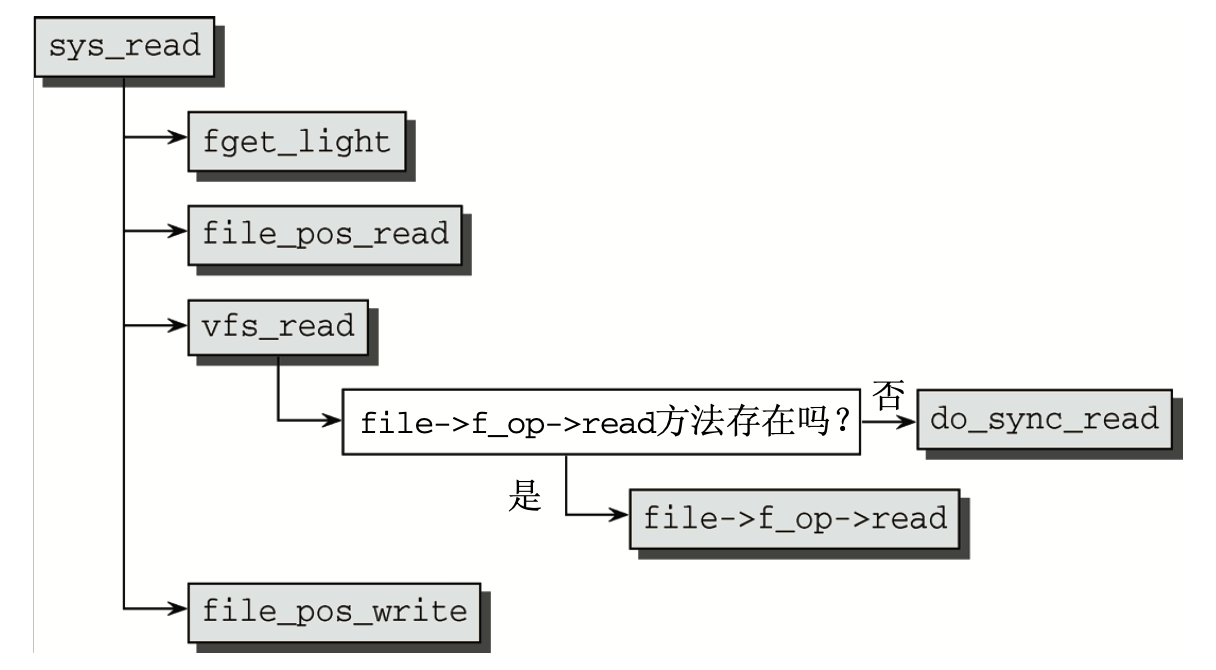
为了提高在文件读取时的性能,Linux kernel提供了缓冲区和缓冲系统。
Linux对文件的读是基于页的,内核总是一次传送几个完整的数据页。若发起read调用时数据不在RAM中,内核则分配一个新的page frame,并调取文件的相应部分填入其中,将其加入到Page Cache中,最后把请求的数据拷贝到进程的地址空间。
大多数硬盘文件系统,使用通用函数generic_file_read来实现read系统调用。
generic_file_read()
该函数有如下几个参数:
- filp 文件对象的地址
- buf 用户态内存区域的线性地址,用于存放读取出的文件数据
- count 读取字符的个数
- ppos 存放读操作开始处的文件偏移量,一般为
filp->f_pos
首先,函数初始化两个描述符:
- 局部变量iovec类型的local_iov,包含buf和count字段
- 局部变量kiocb类型的kiocb,跟踪正在进行的同步和异步I/O操作的完成状态
然后调用__generic_file_aio_read()获取上面两个描述符的地址,返回值时文件有效读入的字节数,在该函数返回后,generic_file_read()也将终止。
__generic_file_aio_read()
接收四个参数:
- kiocb描述符地址:iocb
- iovec描述符数组的地址:iov(描述等待接收数据的用户态缓冲区)
- iovec描述符数组的长度
- 存放文件当前指针的变量地址:ppos
该函数在对Page Cach触发read时的执行过程:
- 调用access_ok()来检查iovec描述的用户态缓冲区是否合法
- 建立读操作描述符,存放与用户缓冲区有关的、正在进行的文件操作的状态
- 调用
do_generic_file_read(),给定参数文件对象指针filp,文件偏移量指针ppos,读操作描述符地址、函数file_read_actor()的地址 - 返回拷贝到用户态缓冲区的字节数,对应读操作描述符的written字段
do_generic_file_read()
写流程
很多硬盘文件系统通过通用函数generic_file_write实现write方法。write系统调用负责将用户地址空间中的数据移动到内核数据结构中,然后将数据拷贝到Page Cache中,将这些页标记为脏,然后持久化到硬盘中。
write系统调用的结构与read同样简单。除了用f_op->write和do_sync_write替换了read中对应的例程之外,二者的代码流程图几乎完全相同。
从形式上看来,sys_write与sys_read的参数相同:一个文件描述符、一个指针变量、一个长度指示(表示为整数)。显然,其语义稍有不同。指针并非指向存储读取数据的缓冲区,而是指向需要 写入文件的数据。长度参数指定了数据的字节长度。
预取机制
很多硬盘的访问都是顺序的。普通文件以相邻扇区成组存放在硬盘上,因此很少移动磁头就可以快速检索到文件。当程序读或拷贝一个文件时,它通常从第一个字节到最后一个字节顺序地访问文件。因此,在处理进程对同一文件的一系列读请求时,可以从硬盘上很多相邻的扇区读取。
预读(Read-ahead)是一种技术,这种技术在于在实际请求前读普通文件或块设备文件的几个相邻的数据页。在大多数情况下,预读能极大地提高硬盘的性能,因为预读使硬盘控制器处理较少的命令,其中的每条命令都涉及一大组相邻的扇区。此外,预读还能提高系统的晌应能力。顺序读取文件的进程通常不需要等待请求的数据,因为请求的数据已经在RAM中了。
缓存回写机制
缓存回写机制也就是Page Cache对脏页进行回写,将对文件的I/O修改永久持久化到硬盘上的过程,此处不再赘述。后续计划深入了解Linux内核对回写的控制。
文件系统
文件系统作为操作系统中一个不可或缺的部分,负责在存储设备上管理、存储、获取数据、维护信息。
在Linux中,内核通过VFS虚拟文件系统向用户提供通用的接口,向下对接各种不同的文件系统,可以有效避免不同文件系统的实现差异对上层带来影响。
ext4
本部分大量内容来自kernel.org的文档
ext4 Data Structures and Algorithms — The Linux Kernel documentation
ext 文件系统发展历史
ext1
Extended file system,扩展文件系统。
Linux最早使用的文件系统为Minix的文件系统,但是该系统存在文件大小限制的问题,同时性能不佳。在1992年4月,Rémy Card开发了扩展文件系统,首个版本作为Linux中的文件系统一起发行,最大支持2GB空间,同时它还是Linux中第一个使用VFS实现出的文件系统。
ext2
在首个ext文件系统中,文件访问、存在inode修改以及文件内容修改没有使用独立时间戳的问题,同时最大仅支持255个字符的文件名以及2GB的空间,ext2系统除了修复了这个问题外,还在硬盘存储数据结构中预留了很多空间供未来开发使用,具有良好的可拓展性。
由于块驱动的限制,ext2文件系统最大支持2TB的单个文件。
ext3
ext3在当时性能不是很出众,但是支持从当时最流行的ext2文件系统升级,无需备份和数据恢复,同时有较少的资源占用(CPU开销)。
ext3相较于ext2增加了
- 日志支持
- 文件系统在线增长
- 对大目录提供HTree哈希树索引
ext3提供了三个日志级别:
- 日志(最低风险):metadata和文件内容一起写入日志中,由于还要写入文件系统,因此带来额外的性能开销。
- 有序(中等风险):只将metadata写入日志,但是保证metadata提交前,文件内容会被写入。大部份发行版默认的方式。写入过程中崩溃时,文件系统会清除还没有被提交的文件修改/创建,但是对于文件的覆盖写入,可能会导致文件处于新旧文件的中间态。
- 回写(最高风险):只记录metadata到日志,文件内容在日志提交前或者提交后写入。如果在日志提交前写入失败,会导致硬盘出现垃圾。
ext3存在的一些缺陷:
- 没有在线的碎片整理工具
- 官方缺少压缩工具
- 不支持恢复已经删除的文件
- 缺少快照支持
- 日志中不支持校验和
- 使用四个字节存储Unix时间,因此在2038年1月18日之后将无法继续处理文件
ext4
ext4在Linux 2.6.28中作为功能完整稳定的文件系统发布,ext4文件系统首先兼容了原有的ext3系统,提供安全可靠的快速迁移。同时还有如下特点:
-
支持更大的文件系统和文件大小
以4KB块,目前支持最大
1EiB(1024*1024*1024GB)的文件系统大小和16TiB的文件大小,使用48bit来编址,未来会支持64bit -
子目录可扩展性
ext4文件系统支持最多64000个子目录,是ext3文件系统的两倍
-
扩展数据块
鼓励对大文件划分多个连续数据块,在硬盘上进行连续布局,从而减少维护大量的间接映射,有助于提高性能,减少硬盘碎片
-
多块同时分配,
在ext3文件系统中,文件系统在分配空闲块时,只能一次处理一个块申请,ext4支持多块分配机制,可以一次申请多个块
-
块的延时分配
借鉴了XFS、ZFS、btrfs等现代文件系统,在执行写入过程时,在以往的文件系统中,都是对写入到cache的数据立即分配相应的block,消耗了大量的时间,延时分配后,只有当数据需要被刷新到硬盘时,才会执行块的分配,可以和上面两个feat进行配合,提高了文件系统的性能
-
快速fsck
fsck是极其耗时的过程,主要是需要检查文件系统所有的inode。ext4中,在每个group’s inode table中都保存了一个空闲inode链表(同时保存了checksum),因此fsck就不必再检查这些inode
-
日志校验和
日志在硬盘中是很容易出错的部分,添加校验和可以避免文件系统恢复错误的日志带来更大的损失。使用校验和还使得在ext3中日志的两步提交简化为一步
-
无日志模式
ext4中可以关闭日志
-
在线碎片整理
使用e4defrag工具手动进行碎片整理
-
inode相关feat
-
更大的inode
从128bytes提高到256bytes
-
inode预留
创建目录时预留一些inode提高性能
-
纳秒级时间戳
提高系统的time resolution
-
-
硬盘空间预分配
应用可以让文件系统预先分配一部分硬盘上的空间,文件系统会提前创建好相关的数据结构并分配相应的块,后续可以直接写入数据,类似P2P下载时预分配,1.可以防止类似功能的低效率应用级实现;2.减少硬盘碎片;3.对于实时应用来说(延迟敏感,航空工业等),这个特点改善了延迟。此feat通过
libc posix_fallocate()实现 -
默认启用写屏障
通过消耗一些性能来改善文件系统的完整性,它确保文件系统元数据在硬盘上被正确地写入和排序,即使在掉电时也是如此,对于一些创建大量小文件或者操作元数据的程序,会带来很大的性能影响。如果硬盘是电池供电,通过
barrier=0可以关闭写屏障(会保证安全性)。写屏障保护保证在数据写入缓存(硬盘缓存)后,先写入日志中的元数据刷新到硬盘,防止出现因为调度策略导致的数据先于日志写入硬盘 -
discard/TRIM
为SSD提供的TRIM支持。
对于SSD而言,由于文件系统在删除时只对块标记为空闲,而SSD却并不知道哪些数据块可用,再次写入时会先清除闪存中的数据,再进行写入,要擦除无效页,要先移走有效页,然后再对一整行进行擦除,最后才能执行写入过程,这个现象也被称为写入放大(Write Amplification)。
TRIM主要使得文件系统告知SSD哪些页不再包含有效的数据,有助于提高SSD的寿命和磨损均衡
随着使用的block数量接近SSD的容量上限,会导致SSD的性能下降,文件系统通过discard指令告知SSD哪些范围内的block已经不再使用,SSD可以将其回收或者用来实现磨损均衡
数据组织
ext4文件系统将部分block组织为一个group,默认block大小采用4KB,因此一个group中的block数量为8*block_size_in_bytes=32768 blocks,空间为128MB。
ext4部分在硬盘中按小端写入,jdb2日志部分在硬盘中按大端写入。
ext4在分配硬盘空间时只能分配若干个block,一个block包含硬盘上的若干个扇区,扇区的数量必须是2的幂次。
不使用扩展布局的文件(通过block映射维护)必须存放在文件系统前$2^{32}$个block中,通过扩展布局来保存的文件,必须存放在前$2^{48}$个block中。
对于32位和64位的文件系统,各个数据结构的大小限制如下图所示:
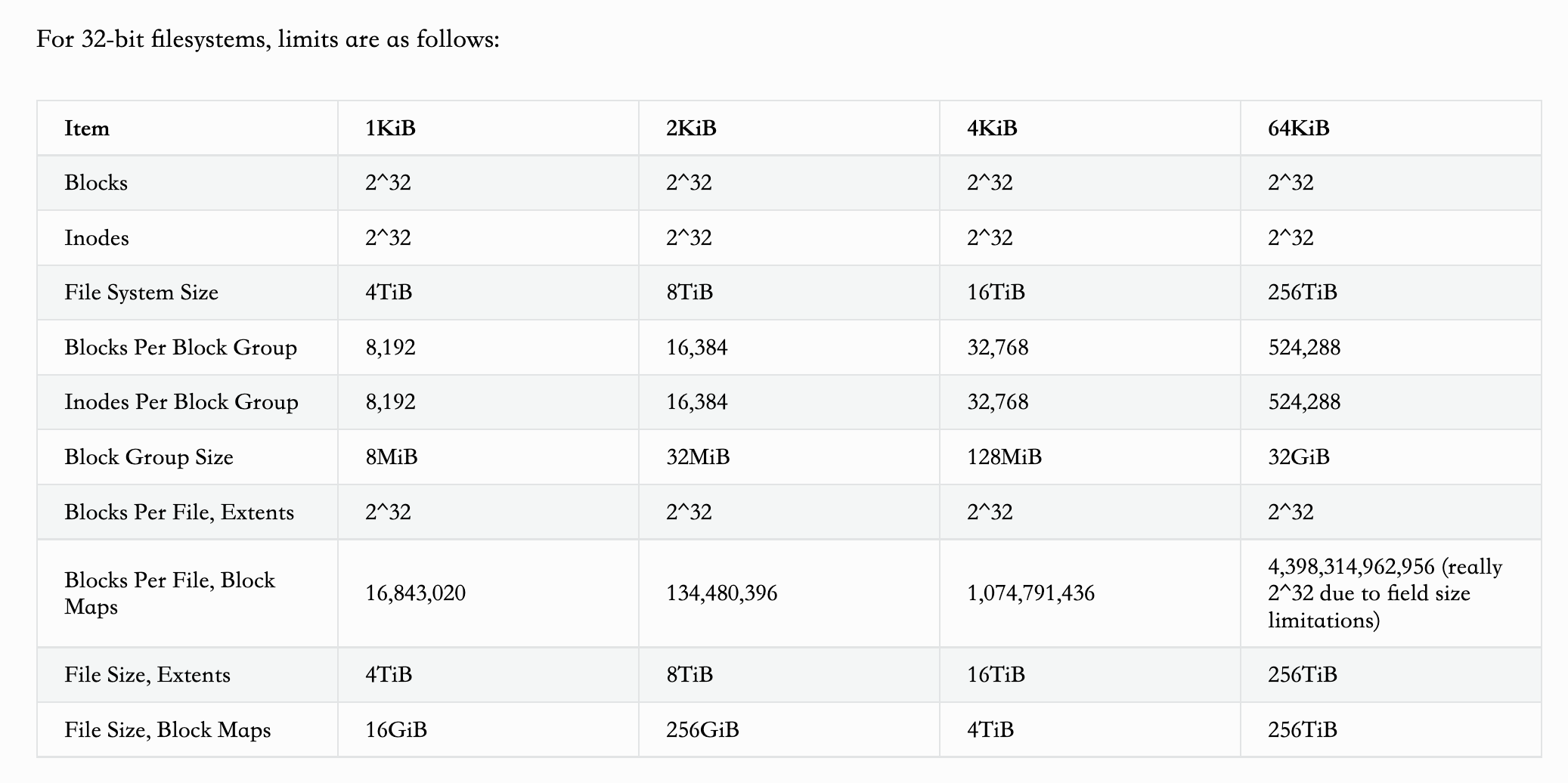
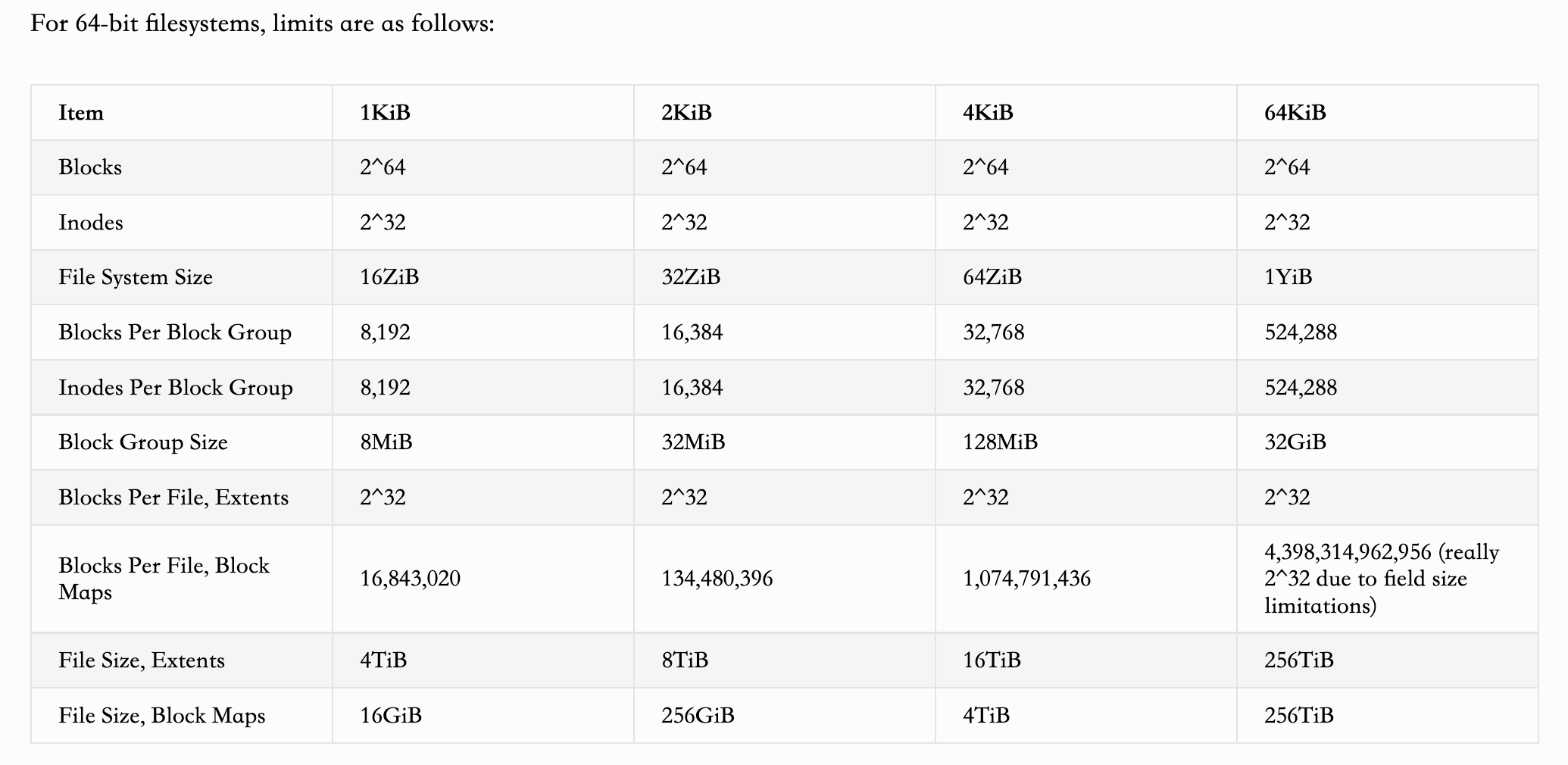
在一个Block Group中,数据的组织如表格所示:
| Group 0 Padding | ext4 Super Block | Group Descriptors | Reserved GDT Blocks | Data Block Bitmap | inode Bitmap | inode Table | Data Blocks |
|---|---|---|---|---|---|---|---|
| 1024 bytes | 1 block | many blocks | many blocks | 1 block | 1 block | many blocks | many more blocks |
硬盘中会预留1024 bytes,用于操作系统的引导模块安装,该padding分区只有group 0含有,为了避免supper block损坏导致整个文件系统不可用,在其他block group中还会有备份,如果一个block group不含有冗余备份,那么它将以data block bitmap开头。
在执行mkfs时,还会在group descriptor描述符分区和data block bitmap分区之间分配一个保留的GDT blocks分区,用于文件系统日后的扩展。
ext4文件系统中还引入了Flexible Block Groups的概念(flex_bg),主要思想是将若干个block group组合成一个大的Group,将所有block group中的元数据(inode,bitmap)都集中到第一个block group中,提高对元数据加载和查询的效率,并且使得文件数据在硬盘上连续,更紧凑。一般通过2^sb.s_log_groups_per_flex个block group来组成一个大的Group。
自ext3起,ext文件系统就开始使用Meta block groups(META_BG),是一组只用一个group descriptor来描述的block groups,首个block group不再存储每个block group的描述符,转由meta block group来存储,并且会在其中存储几个冗余副本。
对于ext4文件系统的读写流程计划在此后单独写一篇文章进行总结。
F2FS
F2FS文件系统提出于USENIX FAST'15,F2FS: A New File System for Flash Storage | USENIX
全称为Flash-Friendly File System,基于日志结构文件系统(Log-structured File System, LFS),针对LFS中wandering tree和gc开销大的问题进行了优化。
主要特点
针对闪存进行了优化:
- ==扩大随机写入区域来提高性能==(此处存在疑问),但带来了空间局部性
- 尽可能使得文件系统的处理单元与FTL中保持一致
针对wandering tree问题,该问题是因为LFS的脏数据通过追加更新,如果一个数据块变成脏数据,那么其索引块,以及间接索引块都会变成脏块:
- 使用node来代替inode和指针块
- 通过包含所有node块地址的Node Address Table(NAT)来切断更新递归的传播
垃圾回收问题:
- 支持后台清理
- 支持贪心和cost-benefit算法
- 为动态/静态冷热数据分离提供multi-head logs
- 引入自适应日志来实现高效的块分配
Btrfs
Btrfs是一个写时复制的文件系统,基于B-tree实现,专注于容错,修复和易于管理,发布于2014年,发展目标是为了取代ext3文件系统,解决ext3的限制。在2021年,Fedora 33宣布将使用Btrfs作为安装时默认的文件系统。而Fedora受到redhat的直接赞助,说明Btrfs在不断发展的过程中,得到了社区中部分用户以及企业的认可,目前还处在测试和不断完善的阶段。
主要特点
- 基于B-Tree维护元数据,插入查询操作高效
- 基于COW,提高硬盘寿命
- 支持只读/可读快照
块I/O层 与 I/O调度器
块设备
对于Unix系统来说,有着一切皆文件的设计哲学,因此外部设备在操作系统看来是一个设备文件。设备文件共分为两种:
- 块设备:数据可以被随机访问
- 字符设备:数据不可以被随机访问,或者包含受限制的随机访问(设备内部构成)
块设备的一个主要特点就是CPU和总线读写数据的时间开销与硬盘硬件速度不匹配。
内核再对块设备发出I/O请求时,内核利用通用块层发起I/O,每次I/O请求都是通过一个bio结构体来描述。通用块层下的I/O调度程序会根据策略将待处理的I/O请求进行归类,将相邻的请求聚集在一起,减少硬盘磁头的移动。
块是操作系统和硬件设备在传输数据时的基本单位。
本文主要介绍mq-deadline,kyber,bfq三个多队列设计的调度器
mq-deadline
mq-deadline调度器主要根据deadline调度器来设计,是deadline调度器的多队列版本,适配了block层的多队列
mq-deadline调度器将IO分为read和write两种类型,对于这每种类型的IO有一棵红黑树和一个FIFO的队列,红黑树用于将I/O按照其访问的LBA排列方便查找合并,FIFO队列则记录了I/O进入mq-deadline调度器的顺序,以提供超时期限的保障
read请求的I/O可以抢占write的分发机会,但不能一直占有,维护了一个计数保证read请求不会导致write请求饥饿
mq-deadline调度器会优先去批量式地分发I/O而不去管I/O的到期时间,当批量分发到一定的个数再关心到期时间,然后去分发即将到期的I/O
最后mq-deadline针对sync穿透性I/O这种需要尽快发送到设备的I/O设置另外一个dispatch队列,然后每次派发的时候都优先派发dispatch队列上的I/O
bfq
全称为Budget Fair Queueing,bfq是一种比例共享的I/O调度器,有一些低延迟能力。支持cgroup。
BFQ的主要特点有:
- BFQ保证了系统和应用程序的响应能力,以及对时间敏感程序保证低延迟(音视频播放)
- BFQ在进程或者组之间分配带宽、时间,在保持吞吐量时进行时间分配
在默认配置下,BFQ优先考虑延迟而非吞吐量,可以通过设置low_latency=0来关闭低延迟启发式算法,来提高设备吞吐量。BFQ通过锁来保护每个I/O请求,会增加一些额外开销。
BFQ是一种比例份额调度器,主要部分借鉴了CFQ,是一种公平的调度器。
- 每个在设备上执行I/O的进程都与一个权重和一个bfq 队列相关联
- BFQ授权一个队列(进程)可以在一段时间内对设备的独占访问,并通过将每个队列与预算(请求扇区数量)相关联来实现。
- 每个队列获得设备访问授权后,队列的预算会在每次请求发送时根据请求大小递减
- 当发生:队列完成其预算、队列清空、触发预算超时时,队列才会过期,预算超时机制可以防止随机I/O进程对设备长时间的占用降低吞吐量
kyber
Kyber I/O调度器是Linux上面针对高速存储设备(NVMe闪存)设计的一个新的I/O调度器,配和多队列的Block层使用。在Linux 4.12的时候和BFQ调度器一起成为内核中的一个可选项
Kyber调度器的基本思路是会为每一个的硬件的队列维护一个不同类型I/O请求的队列,这些请求主要根据I/O操作的方式来进行区分。Kyber按照读、同步写以及其它的(异步写等)将I/O请求分为了3类。在Kyber的设计中,更加倾向于让读优先,这个策略也和其它的一些调度器的设计类似
Kyber在一个Kyber上下文中维护了关于这几类请求的队列。它通过限制每一个队列的长度来对在这里产生的请求的延迟进行控制。Kyber只有在这些队列里面的请求被处理了之后才会收集新的请求。这里限制的方式采用了基于Token的方式
由于Kyber面向的是高速存储,这类设备一般是NVMe SSD、NVM。采用类似CFQ中的一些对请求排序的方法可能有损于性能,所以在Kyber中没有对请求排序的逻辑。Kyber会对一些I/O请求进行合并操作,以及会尝试批量处理这些请求来提高性能。批量处理的大小根据请求类型来决定
NVMe接口协议
简介
NVMe协议的产生是为了取代固态硬盘原有的AHCI协议+SATA接口,随着固态硬盘技术的发展,使得性能瓶颈从存储设备上的转移到了协议和接口中,于是固态硬盘的几大生产商一起制定了该协议。
NVMe实际上是非易失性存储器标准,不限于闪存SSD,使用PCIe接口。
相比于AHCI协议,NVMe的主要特点为:
- 低时延:存储介质方面,存储介质得到了巨大提升;控制器方面,PCIe主控直接与CPU相连,SATA接口需要南桥控制器中转再连接CPU;软件接口方面,简化了指令路径,提高了并发能力
- 高性能:相较于AHCI做出了大量优化
- 低功耗:自动功耗状态切换,动态能耗管理
NVMe工作原理
NVMe作为高层次的协议,原则上可以用于任何接口,一般使用PCIe
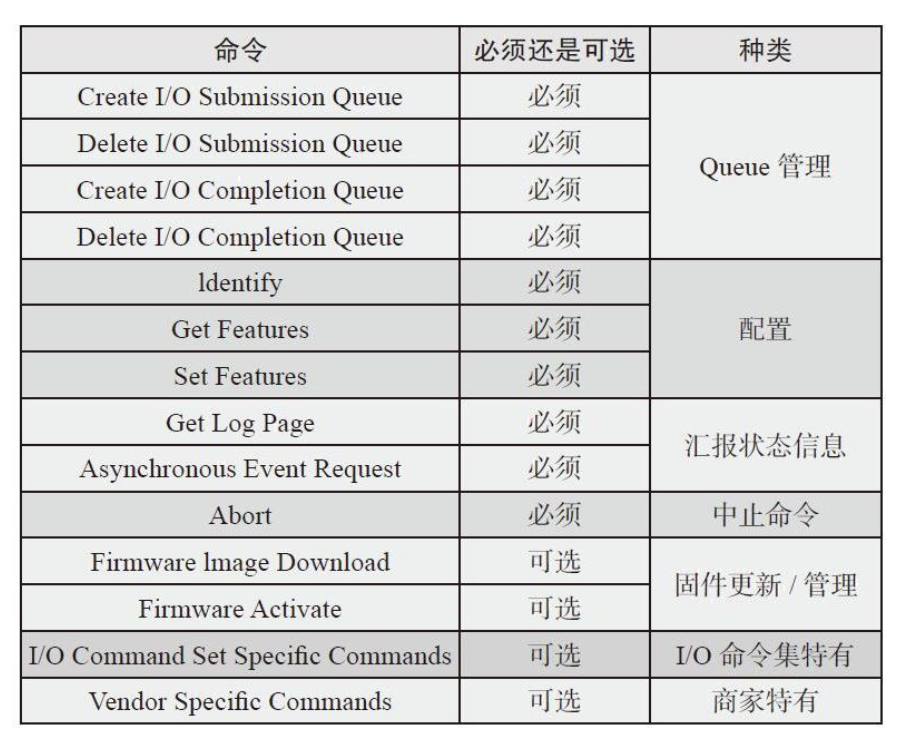
NVMe制定了主机和SSD之间的通信命令,NVMe共有两种命令:
- Admin命令:用于主机管理、SSD控制
- I/O 命令:用于主机和SSD之间的数据传输
Admin命令集有:
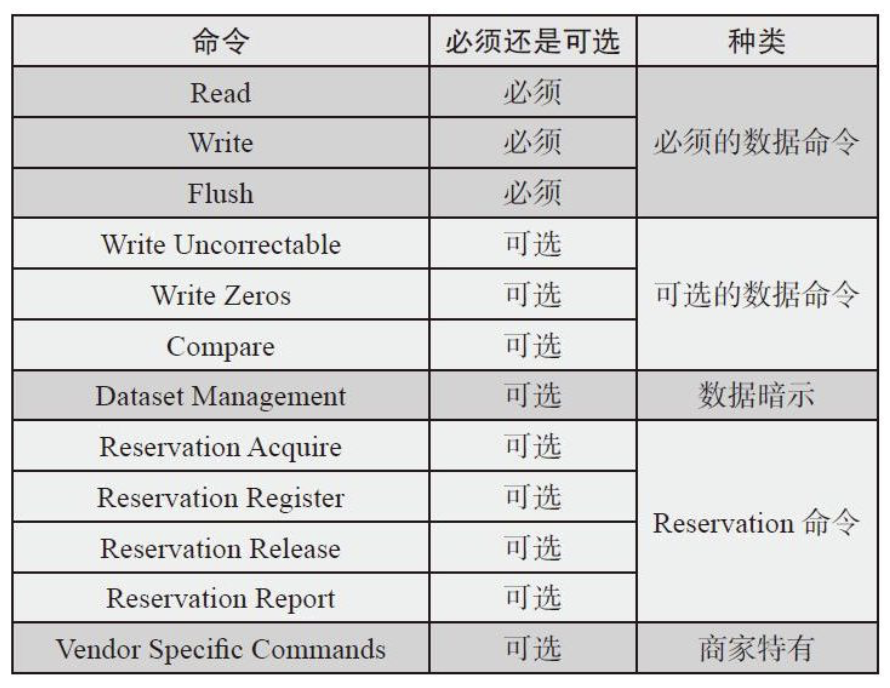
NVM I/O指令集有:
从主机I/O请求到SSD
NVMe有三个重要的机制,Submission Queue、Completion Queue、Doorbell Register。
SQ和CQ位于主机的内存中,DB位于SSD控制器内部,下图直观的展示了他们之间的位置关系。
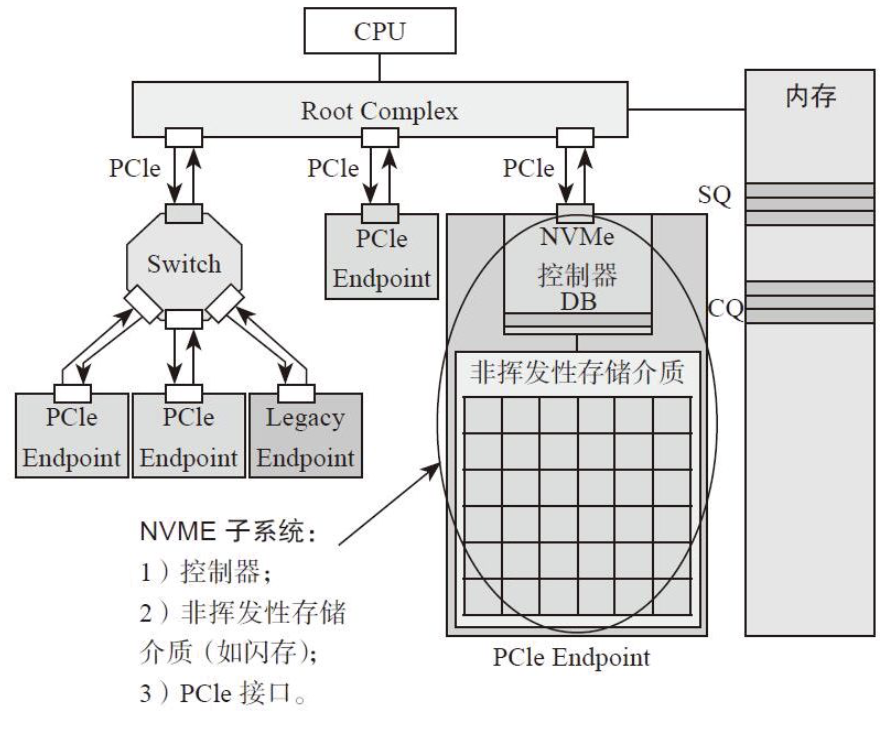
在主机发起I/O指令时,现将指令放在SQ中,主机会通过修改DB寄存器来通知SSD从SQ中取出需要执行的指令。CQ记录了指令执行的状态(成功/失败),SSD负责向CQ中写入命令的状态。
NVMe对指令的处理流程可以用下图来概括:
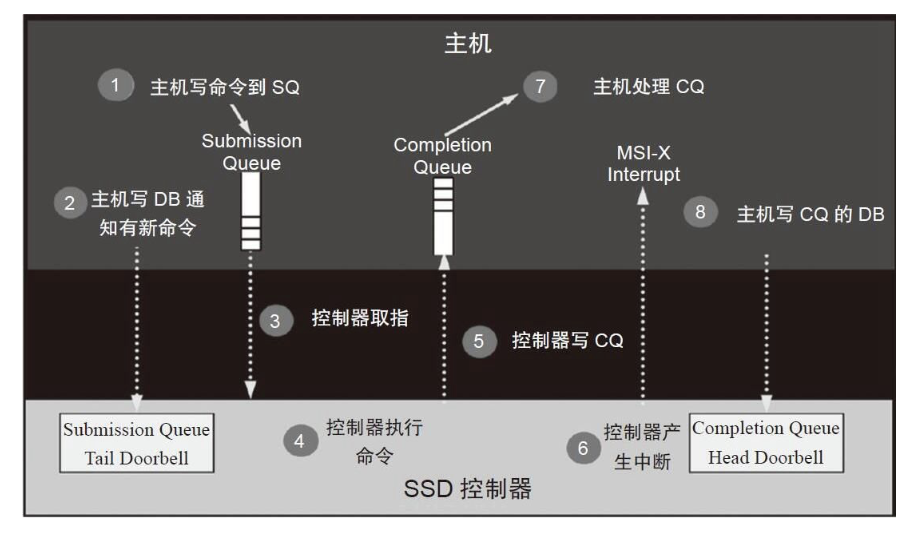
- 主机写请求到SQ
- 主机写SQ尾DB寄存器,通知SSD需要执行I/O请求
- SSD控制器取出SQ中的请求
- SSD控制器执行命令
- SSD控制器将请求的状态写入CQ
- SSD控制器发出MSI-X中断,通知主机指令完成
- 主机收到中断后,处理CQ,看查请求的完成状态
- 主机写入CQ头DB寄存器,告知SSD该指令的结果已经收到并处理
Submission Queue和Completion Queue简介
由于NVMe的SQ、CQ机制,这两个数据结构必然是成对存在的,也存在多对一的关系。
对于I/O指令和Admin指令,分别由专有的SQ和CQ进行管理,即Admin SQ/CQ和I/O SQ/CQ。
I/O SQ和SQ是通过Admin的相关指令来进行创建的。
主机方面每个CPU核心可以有一个或者多个SQ,但是只能有一个CQ。一个核心创建多个SQ主要是为了提高多线程的并发能力,同时可以对不同SQ设置优先级来提高服务质量。
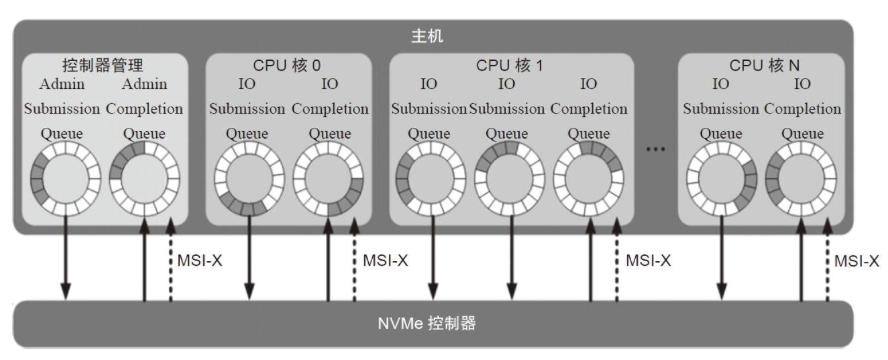
对于Admin SQ/CQ队列,深度在$2-4096(4K)$
对于I/O SQ/CQ队列,深度在$2-65536(64K)$,一个SQ命令条目大小为$64Byte$,一个CQ条目大小为$16Byte$,队列深度可以自行配置。
一个PCIe接口也支持多个lane。
整个NVMe的工作流程像是如下图所示的两个生产者消费者模型
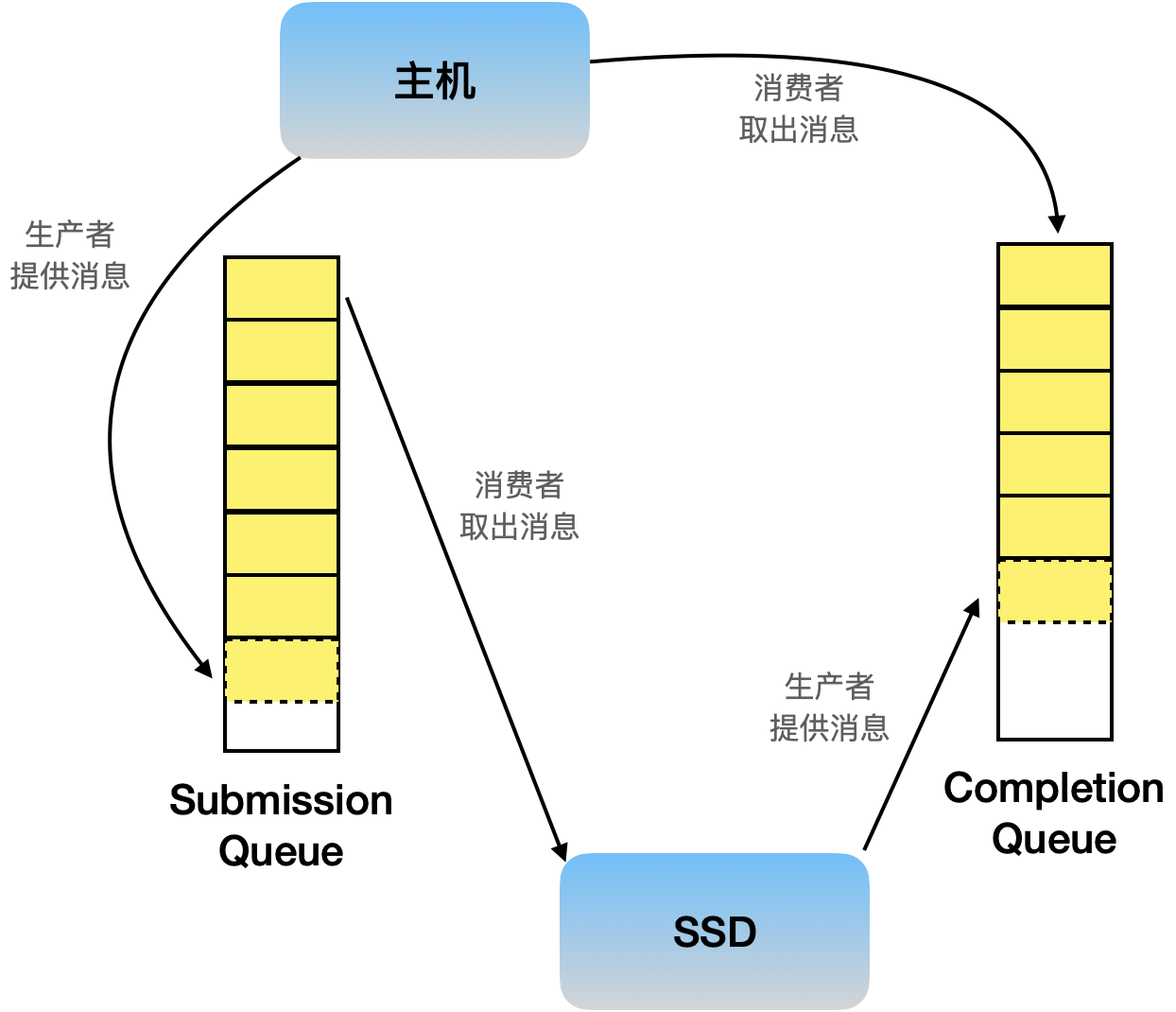
DB: Doorbell Register
在SQ和CQ队列中都有Head和Tail,并且分别有对应的Doorbell,即Head DB和Tail DB,DB在SSD一端,记录SQ和CQ队列头、尾的位置。
对于SSD而言,要频繁从SQ头取出数据,可以轻松的获取SQ队头的位置,所以SQ Head DB由SSD来维护,而对于SQ的队尾对于主机而言更容易维护,因为要频繁的向队尾插入数据,因此SQ Tail DB由主机维护,SSD根据SQ的头尾可以获取当前队列中有多少请求在等待执行。同理,CQ Head DB由主机来维护,CQ Tail DB由SSD来维护,SSD根据CQ队列的头尾来判断CQ队列是否还能接受新的请求完成信息。
从Doorbell的名字来看,还有通知的作用,当Doorbell Register的值改变时,SSD就知道有新的请求需要处理;主机就知道有新的请求已经完成了。
注意:对于主机来说,DB是可以写不可读的。
其他有关NVMe的内容
寻址问题(PRP、SGL)
Namespace
数据保护问题
后续有时间再对这些内容进行学习
基于闪存的固态盘
此前一篇博客整理了有关闪存和固态盘的内容,下文为转载过来的内容
主要由Flash Memory 和FTL组成
Non-Volatile Memory 提供低延迟持久性的内存/存储,也可以用来做内存
根据延迟数量级,一般用PCM做内存,Flash Memory做外存
Flash Memory
闪存原理
类型
NOR闪存
- 存储密度低
- 可字节改写
NAND闪存(主流)
- 存储密度高
- 不可覆盖写
用于外存需要较高的存储量级,一般用NAND
闪存单元
读:电压代表不同数值
写:电子注入
相比晶体管添加了浮栅门,保存电子
原理其实比较简单,非电子系就不做太详细的研究了
闪存页(4KB,8KB,16KB,读写单元),阵列中的每一行
闪存块(擦除单元),由多个页组成的单元
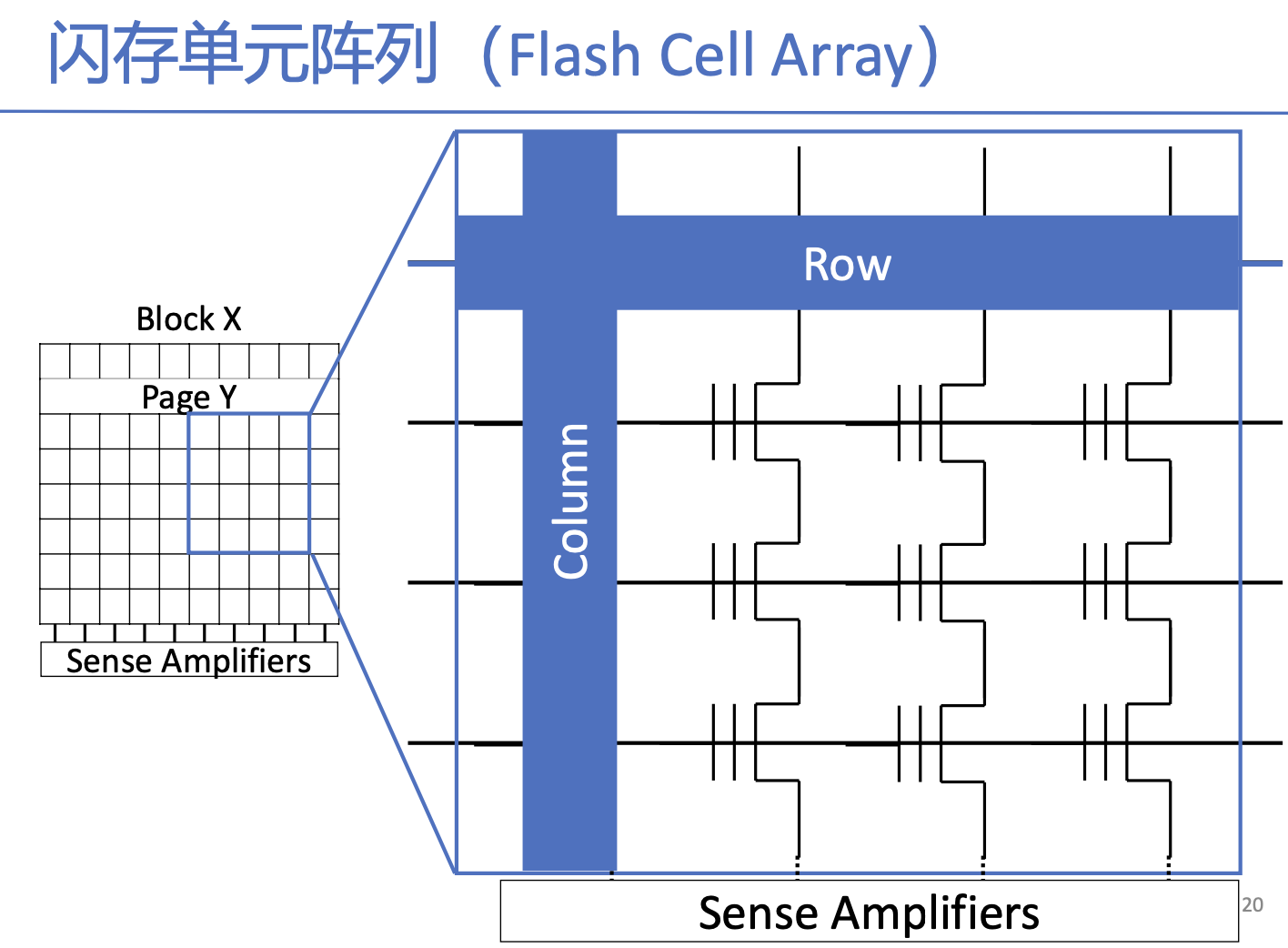
选中行和列,然后将数据加载到Sense Amplifiers
存储单元有两个阈值的电压,可以根据两个电压的中点作为读电压,2.5V读电压时左边通电,数据为1,右边则不通电,数据为0
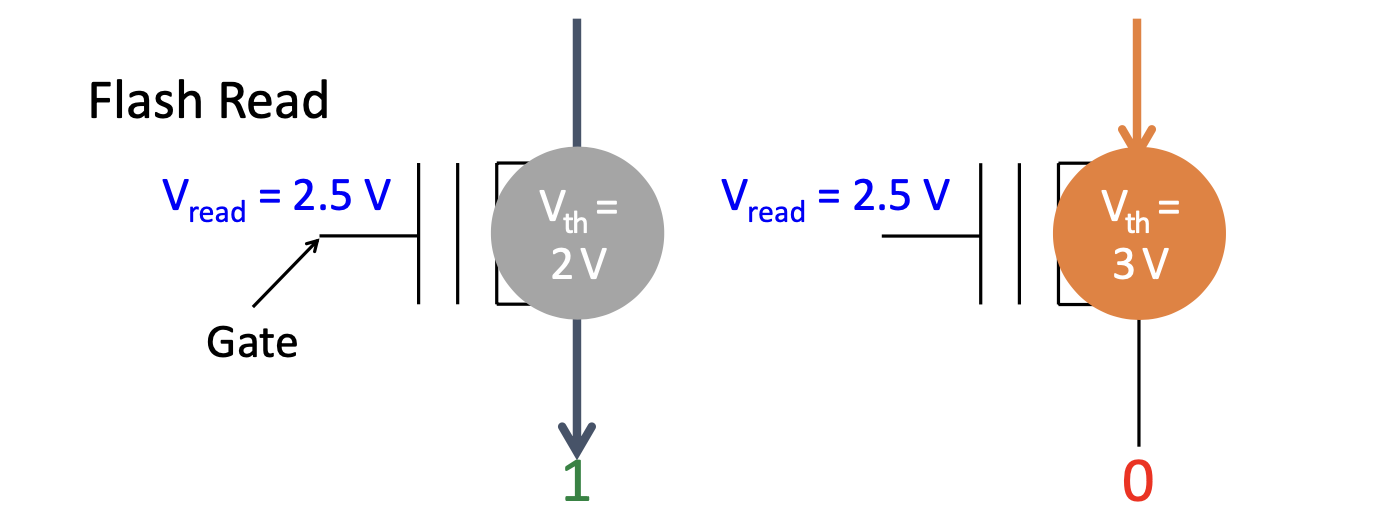
Pass Through
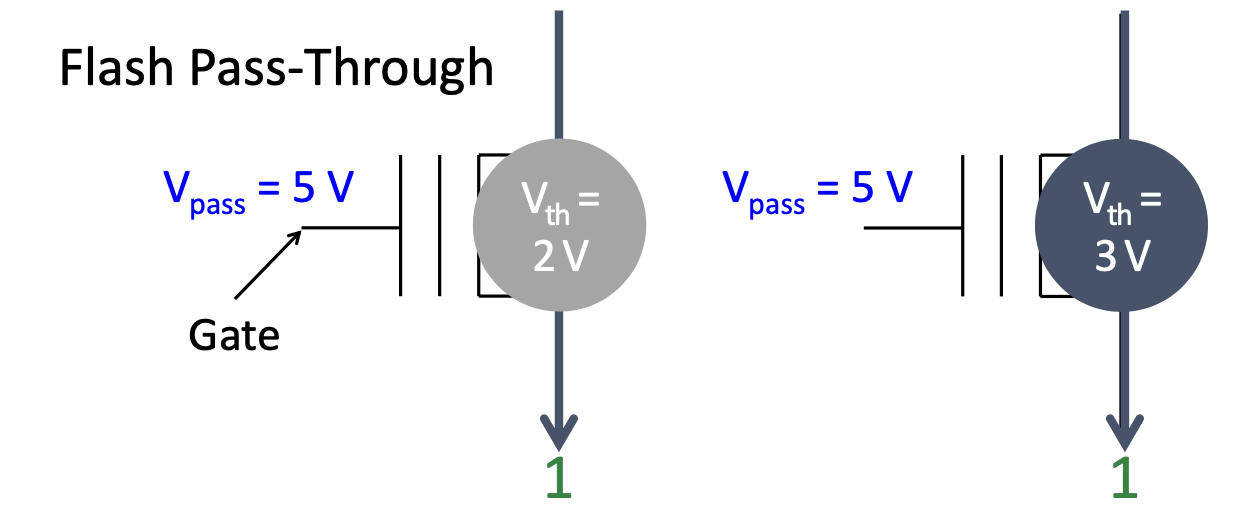
选取一个较大的电压,使得所有的单元都接通,数据为1,不影响其他行的状态
如图所示的存储结构,在第二行施加2.5V电压,其他行施加5V,最终读取数据为0011
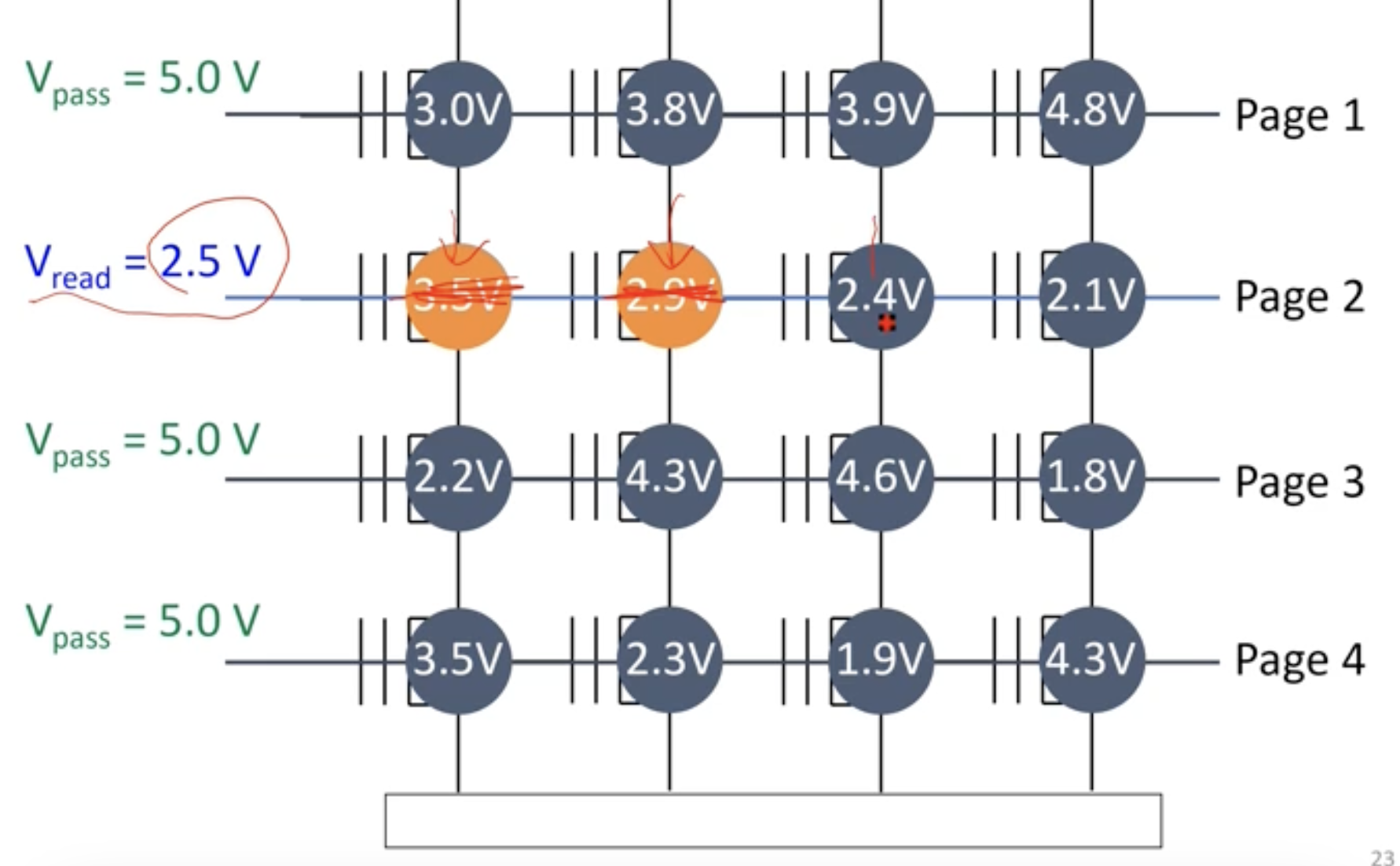
上述为SLC,Single Level Cell,单存储单元
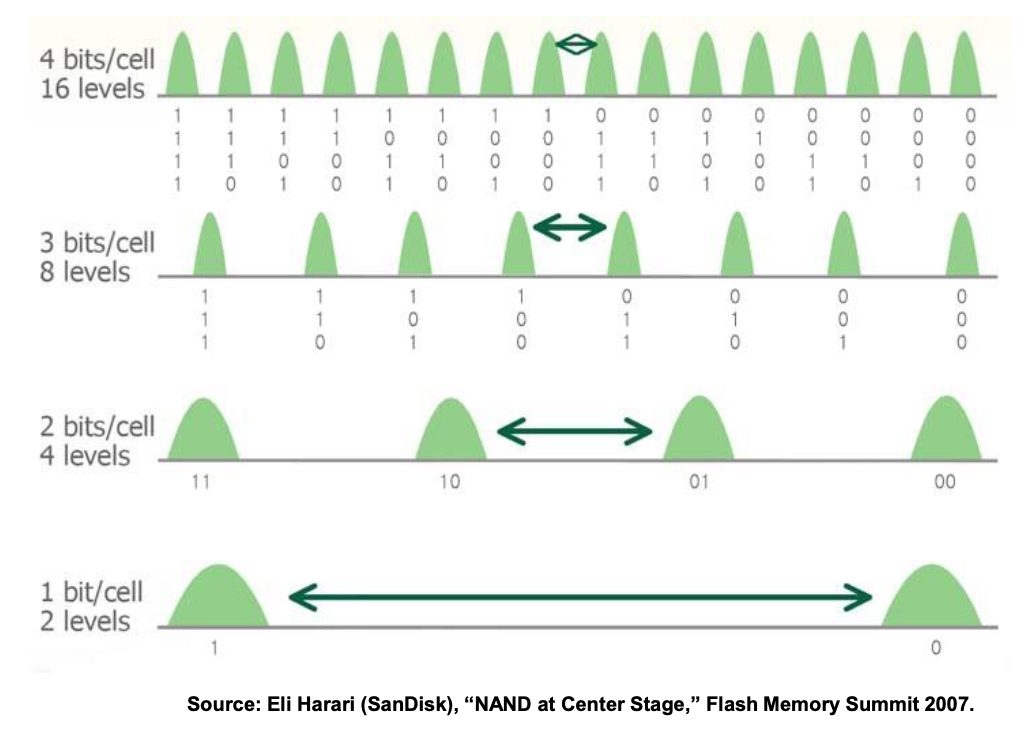
多比特闪存
多比特闪存单元MLC,包含2Bits 4个Level的数据
TLC 3 Bits 8个Level
QLC 4 Bits 16个Level
多比特使用格雷码来编码
使用格雷码使得相邻单元只有一位差异,方便纠错
多比特提高了存储密度,但是提高了错误率,因为施加的电压差距很小。可靠性会降低。
对于多比特的写,MLC分为高比特和低比特,对于低比特的状态加偏移电压确定高比特,在低比特时需要加的电压较大,操作难度低,运行速度快,在高比特时需要加的电压小,波形的间距小,操作难度高,运行的速度较慢。
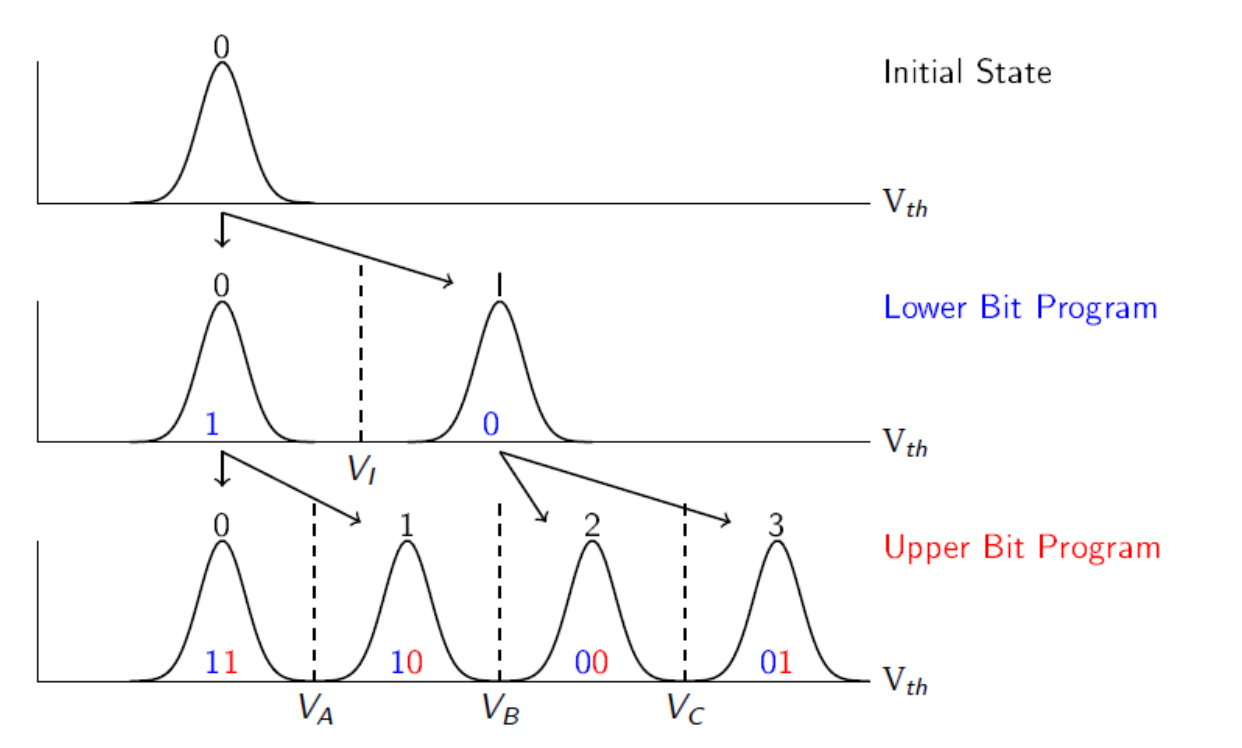
对于多比特的读,先看lower bit,加一次电压,即可筛选出低位的0,1,再加两次电压确定upper bit。因为upper bit为0的在中间部分,为1的在两侧,因此需要在两个分界线分别加一次电压来确定upper bit为多少。
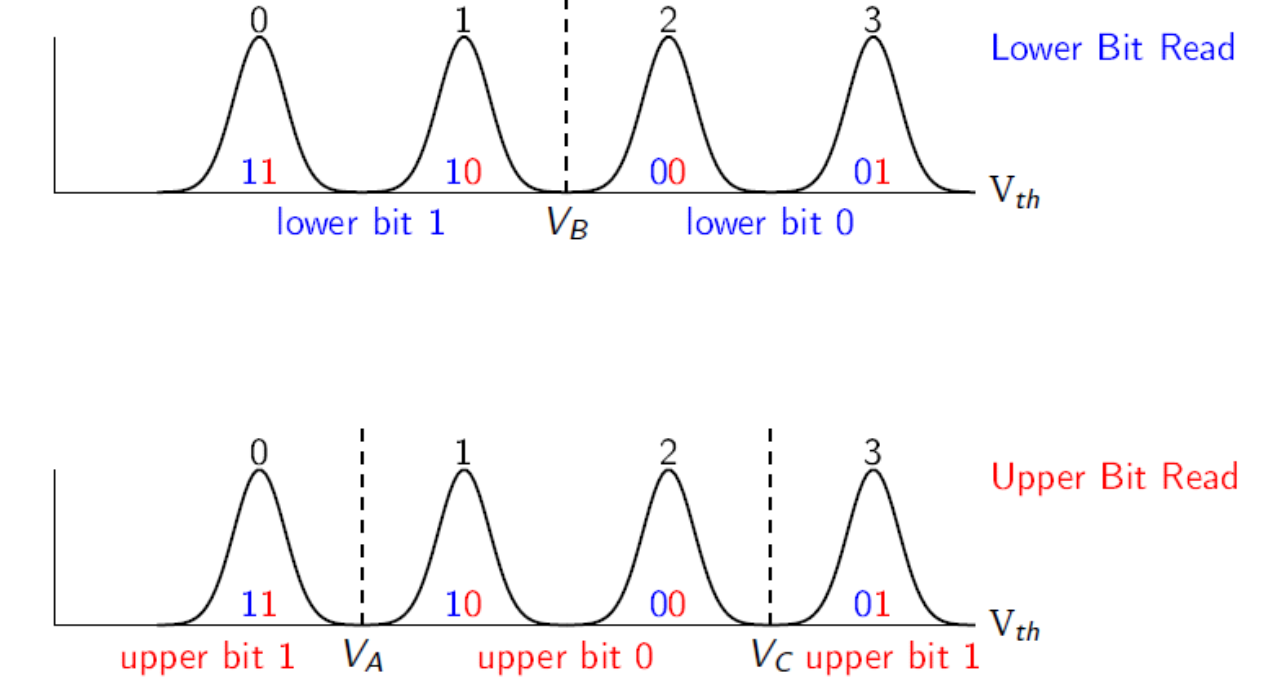
闪存
Block的大小的一种配置:
一行有两个Page,Upper Page和Lower Page,每个单元中,低位构成Lower Page,高位构成Upper Page,有128个单元,128K/8=16KB
有64列bitlines,一个block的大小即为16KB*64*2=2MB,一般按照此比例配置Block
写入时按照固定顺序,写入高低页面相互独立,不能同时写,在写入加压时容易使相邻单元发生数据偏移,要降低错误率
写入是需要先擦除再写入,擦除整个块
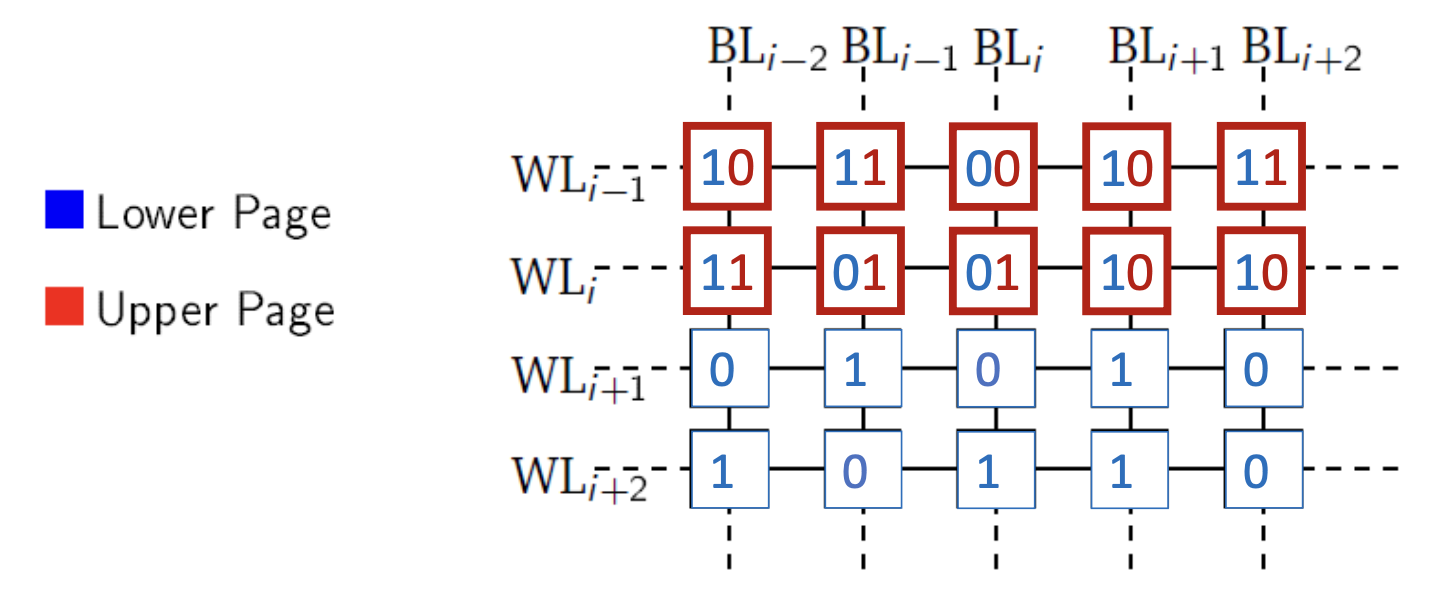
闪存特性
读写粒度
闪存页读写粒度:
- 4KB,8KB,16KB必须全部读取或者写入
- us延迟
闪存块擦除力度
- 2MB擦除
- ms延迟,可以通过FTL来优化
不可覆盖写
写前需要擦除,读写粒度与擦除粒度不同
存在64bytes的OOB(out of bound area),保存ECC,用于纠错,容忍写入时部分比特出错
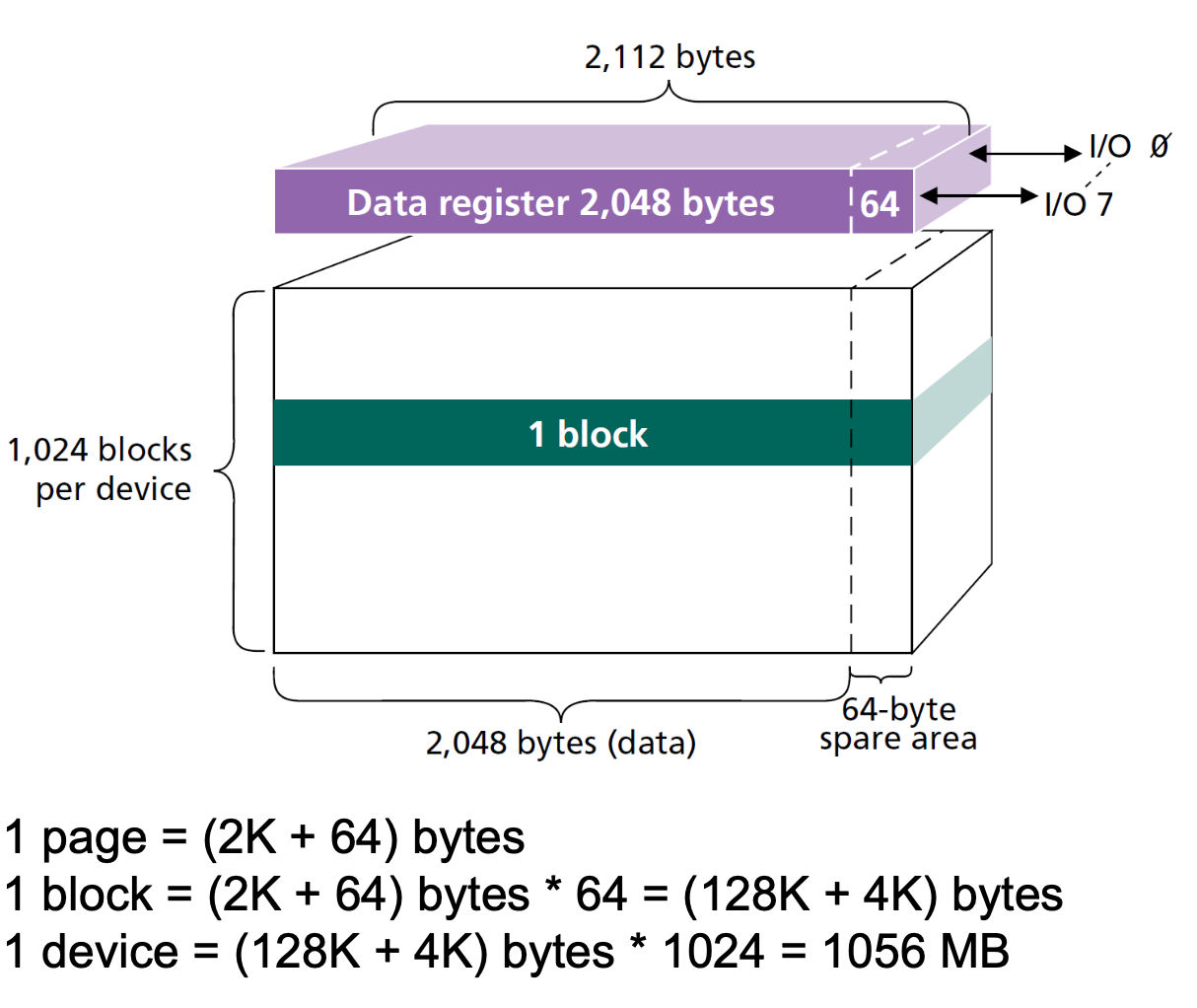
有限次擦除
随着擦除次数的增加,存储单元不能可靠的保持状态(存储数据)。
氧化层老化变薄,束缚电子能力变弱
- 耐久性 变薄地次数
- 保持力 不通电可以放置的时间
SLC:10w次
MLC:1w次
TLC:1k次
根据特性来设计FTL固件
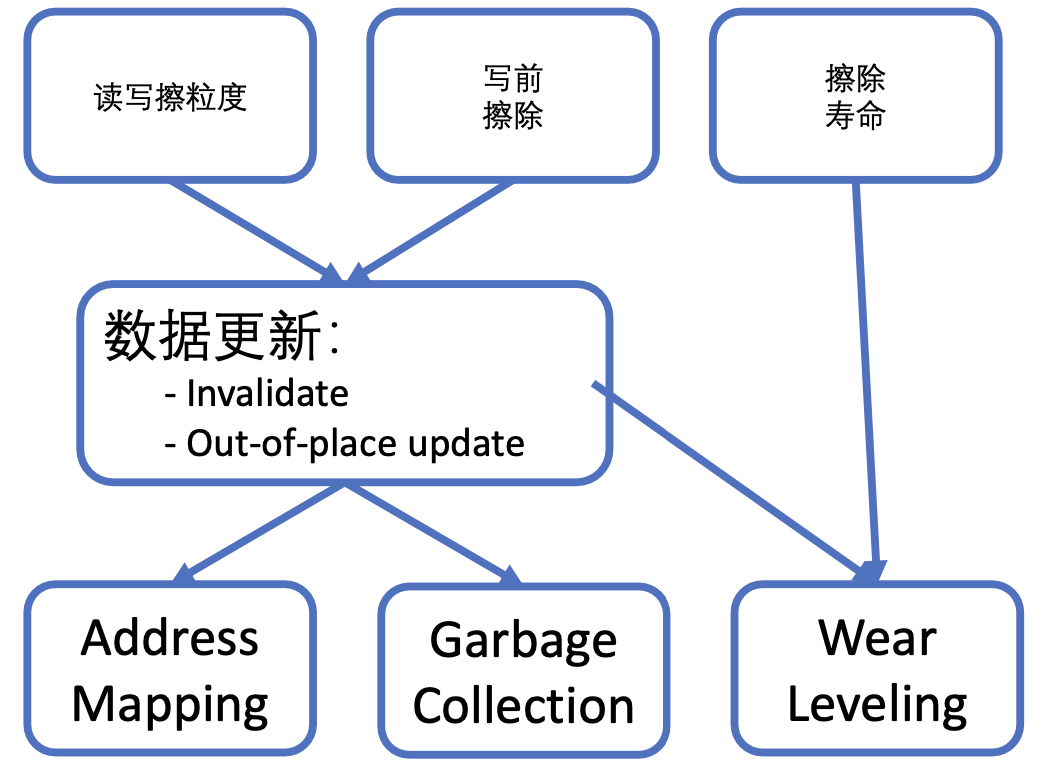
FTL
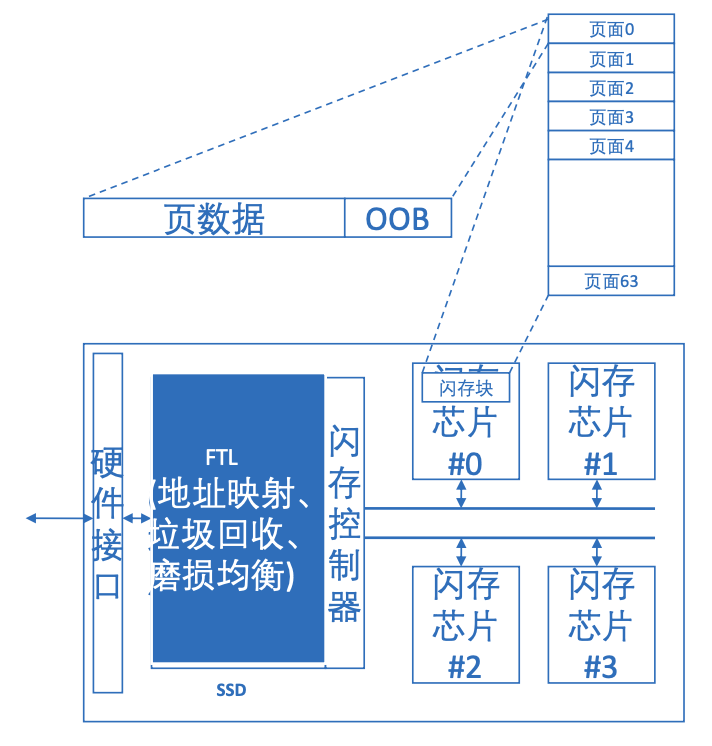
固态硬盘整体构成
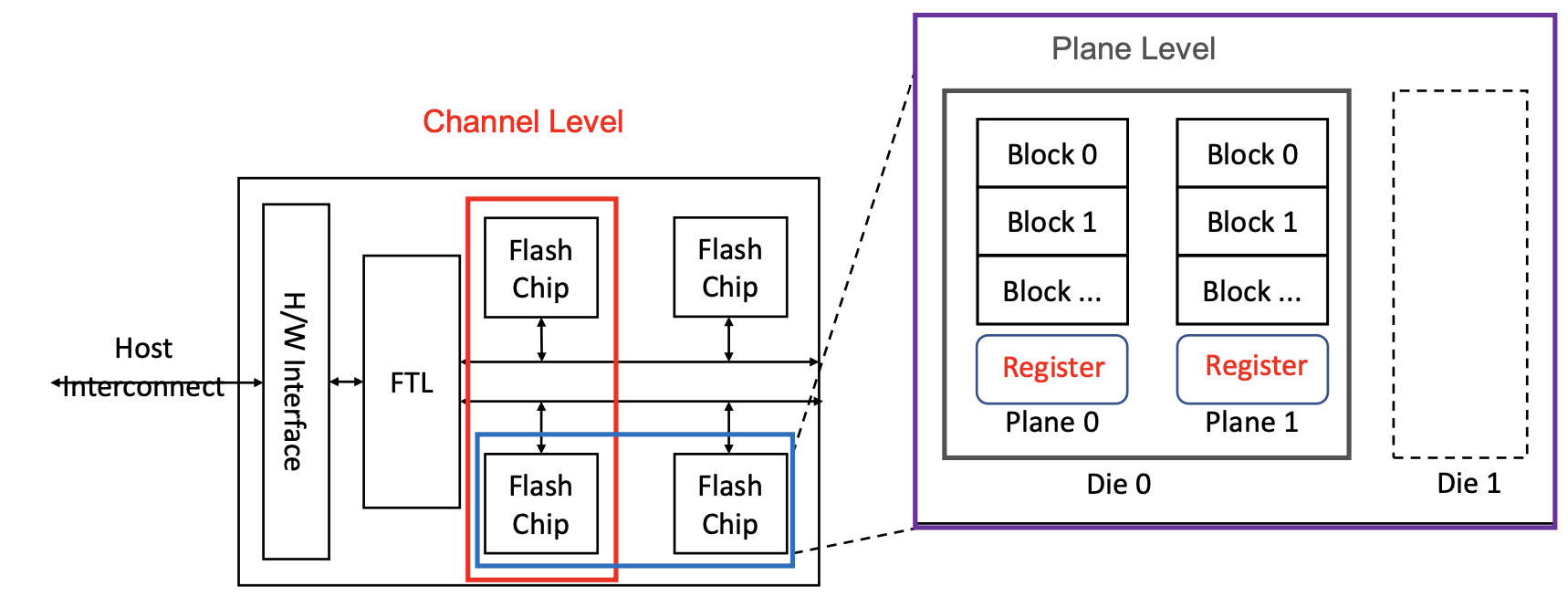
SSD中的通道可以并行,通道中也可以并行读取,每个Plane中有寄存器,暂时存储准备好的数据。不同单元并行,因此内部带宽大
垃圾回收
page对于OS而言,是写入时的block
Page三种状态
- 空闲 free page
- 有效页 live/valid page
- 无效页 dead/invalid page
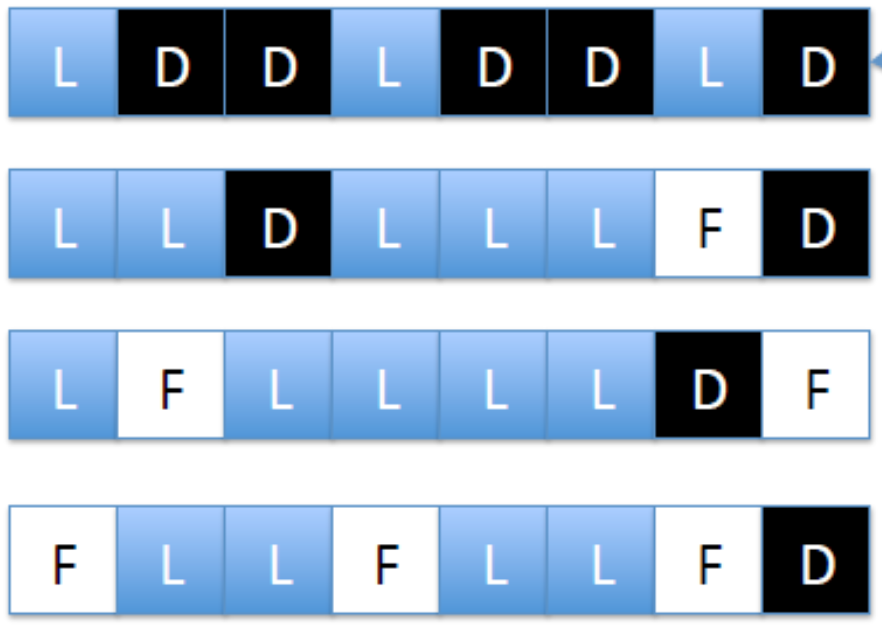
需要擦除无效页,先移走有效页,然后再对一整行进行擦除,转为空闲
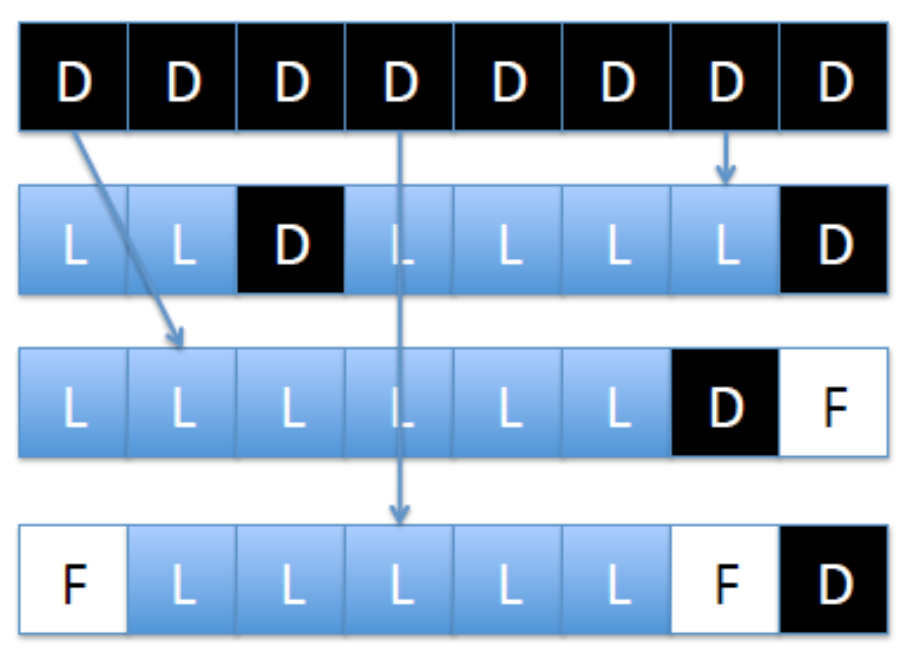
时间开销:
- 复制有效数据到$(R_{Latency}+W_{Latency})*N$,N是移动page的数量
- 擦除产生的开销 ms级延迟
GC策略
要解决的问题:
- 何时启动GC
- 选中那些/多少Block进行GC
- 有效的页如何被转写
- 新数据写到哪里
GC的时间开销:
- 块擦除的时间 ms
- 有效页的复制时间
贪心策略:
- 找到脏页最多的block来进行擦除
优化:
- Age
- Hot/Cold 数据隔离,分组问题
磨损均衡
优化寿命,有静态和动态策略
静态:周期性的调整冷热数据存储的位置
冷热数据的分区:将冷数据放在一起,热数据放在一起
FTL简介
-
维护映射,虚拟地址到物理地址
-
使用SRAM存储映射
-
向上层隐藏擦除操作:
-
避免原地更新->异地更新
-
更新一个新页面
-
高性能的垃圾回收和擦除
-
OOB有物理地址到虚拟地址的映射,用于掉电恢复,这里引用一段wisc的OSTEP中的一段解释(44 Flash- based SSD)。
OOB保存的在每个页中映射信息,当掉电或者重启时用它在内存中重建映射
为了防止在重建时扫码整个SSD,可以使用日志或者检查点的方式来加速这个过程
大致看了一下OSTEP,是有关操作系统的一本非常好的书,希望以后有时间读一下

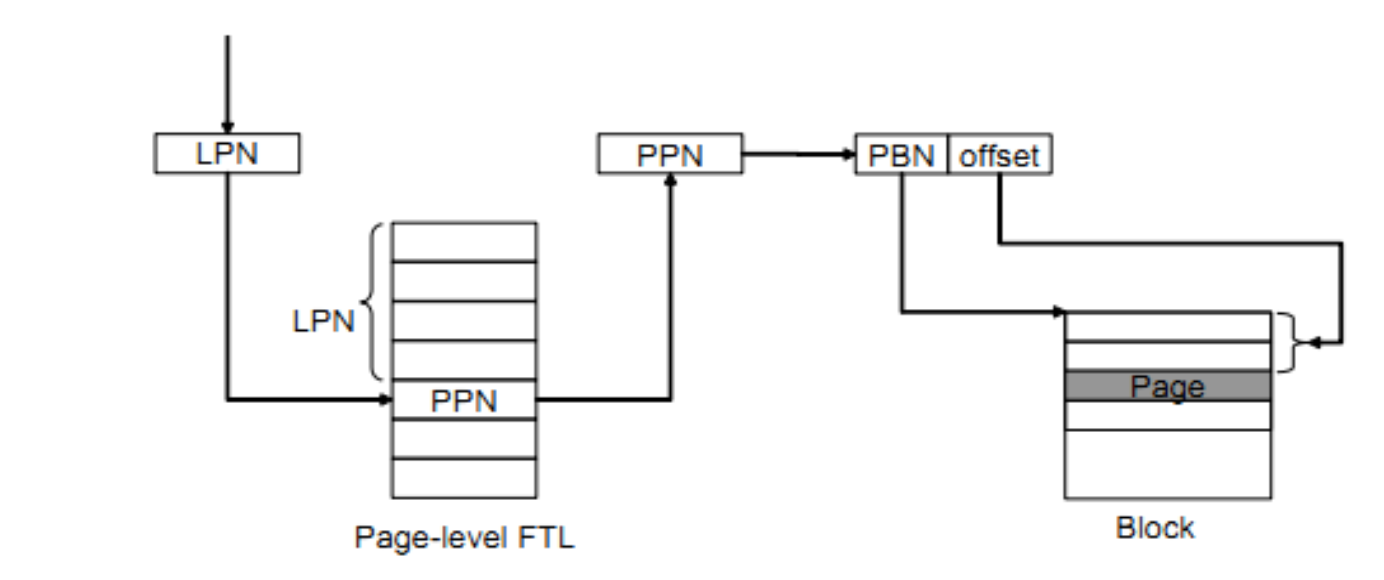
Page-Level FTL
原理类似OS中的页表,由Logical Page Number查询页表得到Physical Page Number
缺点是页表占用很大的空间
Block-Level FTL
保持Block 到Block的映射
先查找到对应的Block,在根据offset得到page,块内的页码偏移offset是固定的
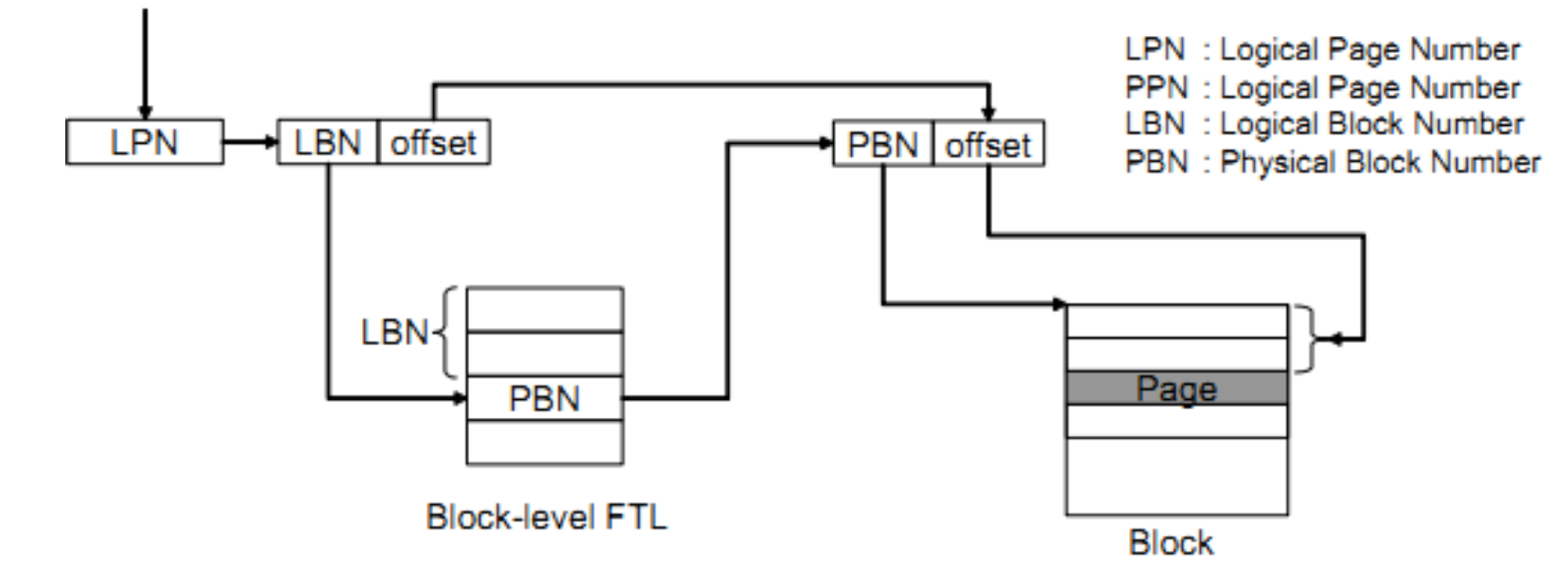
优点是占用空间很小,缺点是GC负载增加
原因:offset在不同Block中保持不变,在异地更新时,要选择其他block中相同的offset进行写入,如果选中的block已经存在数据,需要把数据迁移。【TODO 这里讲得不是非常的清楚】
Hybrid FTL
对写入分为新/旧数据,新写入的数据用Page-Level Mapping效率高,写入Log Blocks作为缓冲,之后再更新到Data Blocks
旧数据因为写入后更新相对不频繁,使用Block-Level Mapping,写入Data Blocks
Reference
- NNSS实验室暑期实习文档
- 《Linux内核设计与实现》
- 《深入理解Linux内核》
- 《Linux设备驱动程序》
- 《深入浅出SSD:固态存储核心技术、原理与实战》
- NAND, DRAM, SAS/SCSI and SATA/AHCI: Not Dead, Yet | Enterprise Storage Forum
- 【Quora】Robert Love对缓冲区缓存和页面缓存的主要区别是什么的回答?为什么它们在较旧的内核中是独立的实体?为什么后来他们被合并了?
- 【OSTEP】Operating Systems: Three Easy Pieces (wisc.edu)
- 【bilibili 清华大学】存储技术基础
- 【kernel.org Ext4文件系统介绍】Ext4 Howto - Ext4
- 【kernel.org Btrfs文件系统现状】Status - btrfs Wiki
- 【kernel.org Ext4文件系统设计】ext4 Data Structures and Algorithms
- 【USENIX FAST'21】F2FS: A New File System for Flash Storage
- 【archlinux.org ArchWiki】Ext4
- 【Red Hat Customer Portal | SSD discard】Chapter 21. Solid-State Disk Deployment Guidelines Red Hat Enterprise Linux 7
- 【mq-deadline】mq-deadline调度器原理及源码分析
- 【Kyber I/O】Kyber IO Scheduler of Linux · Columba M71’s Blog