
【存储技术基础】主存
0x00 主存
当前面临的问题:
-
容量问题、带宽问题、QoS保证
多核处理器、数据密集应用、云计算、GPU
HDFS(GFS)基于外存储器
Spark 内存中数据处理
-
能耗功率问题
40%功耗在DRAM,Refresh操作耗能
-
DRAM发展遇到瓶颈
制成方式限制
改进:
- 3D-Stack DRAM 提供更高的带宽
- 低延迟DRAM
- 低功耗DRAM
- NVM(e.g. PCM)容量更大,延迟较高
0x01 DRAM的组成
- Channel
- DIMM 内存条
- Rank 二维阵列最小单元
- Chip 芯片
- Bank
- Row/Column
行为字线 word line
列为位线,交点是cell 内存单元
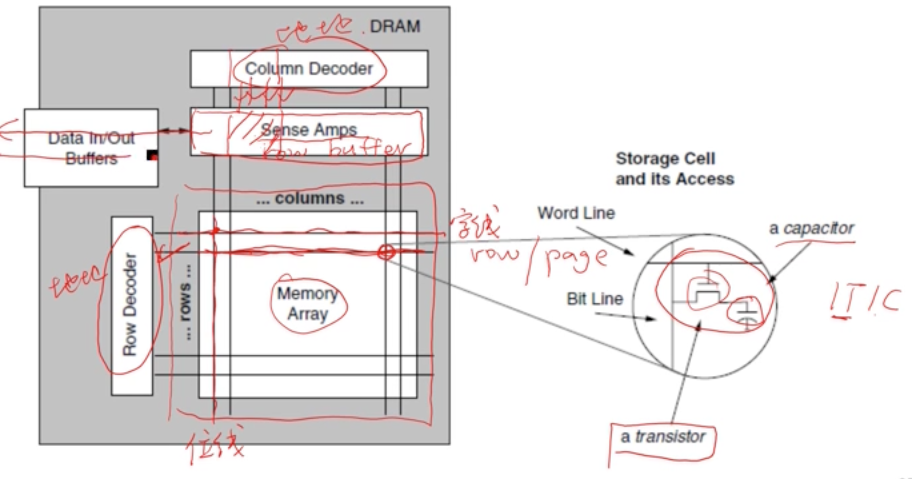
DRAM row是一个DRAM page
Sense Amplifiers 也被叫做Row buffer
每个地址通过<row,colum>编址
访问一个closed row的过程:
- Activate:将row放到row buffer中
- Read/Write:读写row buffer中的column
- Precharge:从row buffer中的数据写回到选中的row中
Bank Operation
给定Row Address通过Row decoder选中一行
将行加载到Row Buffer
若读取的Row在Row Buffer中,则为命中Hit状态,通过Column Mutex直接获取数据
若读取的Row不在Row Buffer中,则为冲突Conflict状态,将Row Buffer回写,然后再选中新的Row,读取数据
Chip
由多个(2-16个)Bank组成,Bank共享总线(指令/地址/数据总线)
每次只能读4或16 Bit
Rank and Module
Module为DIMM内存条,连接在主板上,由一个或多个rank组成
Rank由多个Chip构成,提高接口带宽,多个Chip共享地址和指令总线,有单独的数据总线
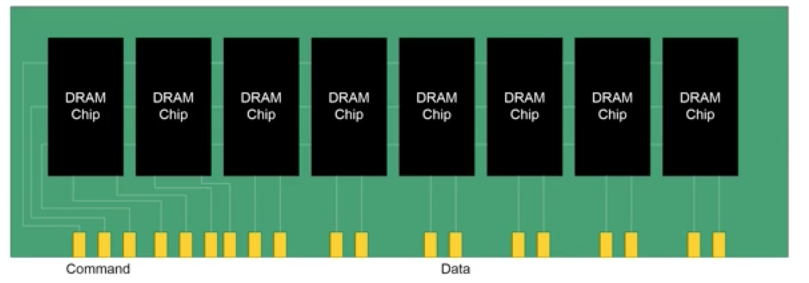
多个Chip可以并行操作
对于64 bit的读取,分配到多个Chip中同时读取
对于多DIMM情况,可以先确定在哪根DIMM条中,再进行读取操作
Chanel
Bank之间为分时共享
Channel为独立总线,数据可同时读写,每个Channel有一个Memory Controller
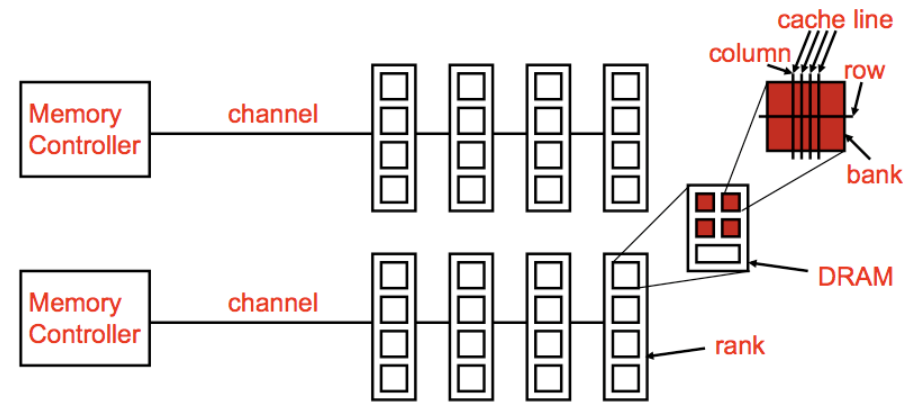
在同一个Channel中的DIMM数据分时共享
一张比较清晰的结构关系图
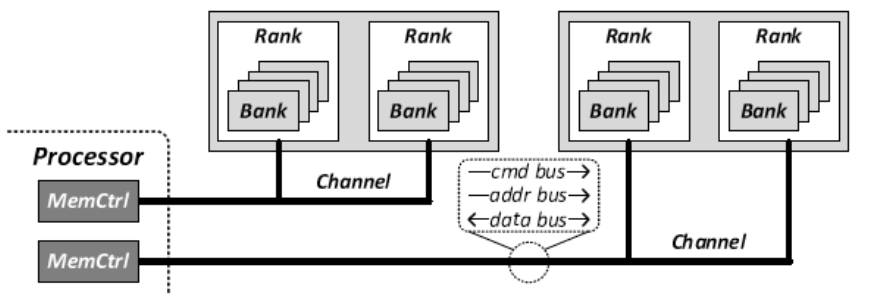
同一个Channel可以连接多个DIMM条
从CPU访问角度观察
Memory Channel中,在DIMM中Chip Selection选择访问的Rank,通过地址确定访问的数据
Rank中的8个Chip每个都提供8 bit,共提供8 Byte访问
由每个Chip中的bank选择器从8个bank中选择一个获取8 bit
Bank中通过Row-Buffer来获取数据
延迟的产生:
- CPU到controller的传输时间
- Controller延迟,请求队列和调度
- Controller到DRAM的传输时间(总线)
- DRAM 中Bank的延迟
- 选择某一行 Activate
- 读取的时间
- Precharge
- DRAM到CPU的传输时间
主要关注Bank中的延迟
Multiple Banks
使DRAM访问并行
由于不同Bank分时共享,可以使得Bank提前将row加载到Row Buffer中,提高利用率
Multiple Channels
更容易实现
提高总线带宽
提高并发能力需要减少Bank和Channel的冲突问题,需要对编址策略进行优化
比较直观的观察Multiple Banks优化的效果,达到Overlap的效果
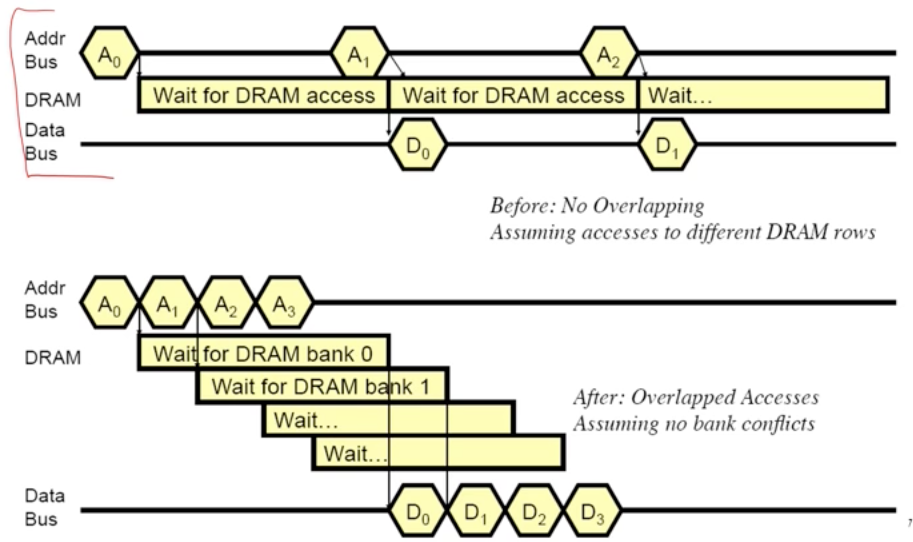
Address Mapping
地址映射对DRAM并发能力的影响
将访问DRAM中数据的地址进行排列,包含Channel、Row、Bank、Column
核心思想:调整容易产生冲突的地址,使其相对靠后,还要兼顾其他问题
将Column的高8位和低3位分离

提高Row Buffer的利用率,倒数第二种比较常用
对OS而言,由逻辑地址Virtual Address映射到物理地址
Virtual Page Number -> <Row,Bank>,可以通过调整映射算法来优化存储效率
0x02 DRAM Refresh
由于电容中的电子持续泄漏,每隔一段时间重新写入数据,读取到row buffer再写回,刷新间隔一般为64ms
负面影响:
- 能耗增加
- 性能减少,Refresh中内存不可用
- QoS影响,不能保证平稳
- 刷新率使得DRAM容量的扩展受限
性能影响
刷新时Bank变得不可用,Row Buffer的占用
在刷新结束前有长时间的暂定,有两种优化策略:
- Burst Refresh 所有的行依次全部刷新
- Distributed Refresh 每行以固定的时间间隔在不同的时间进行刷新
两种方式(集中式/分布式)的示意图:
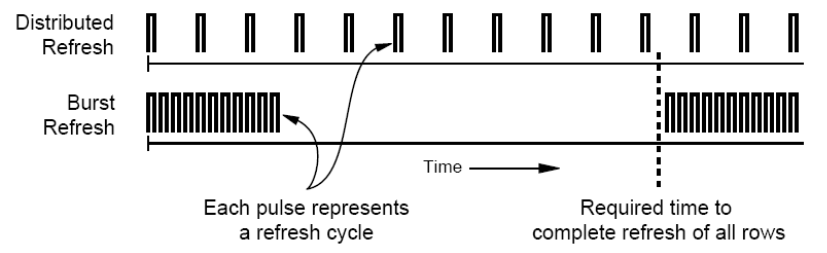
Distributed Refresh减少了等待时间
随着设备容量的增加,消耗在Refresh上的时间/能耗占比越来越大
目前应用的策略:Auto Refresh,每次只Refresh其中几行
一些探索:刷新间隔的调整,64ms保证在最坏情况下的可靠性,在容忍存储单元出故障的前提下,可以适当提高刷新间隔,对于出错的单元采用更低的刷新间隔(不同存储单元采用不同刷新频率)
0x03 Memory Controller
位于CPU中
基本功能:
- 保证DRAM的正确性,刷新和时序timing
- 遵循一定的时序约束(bank,总线,channel的冲突)来完成DRAM请求,转换请求为DRAM Command
- 对请求进行调度提高性能
- 管理电源能耗,开关Chip,管理电源模式
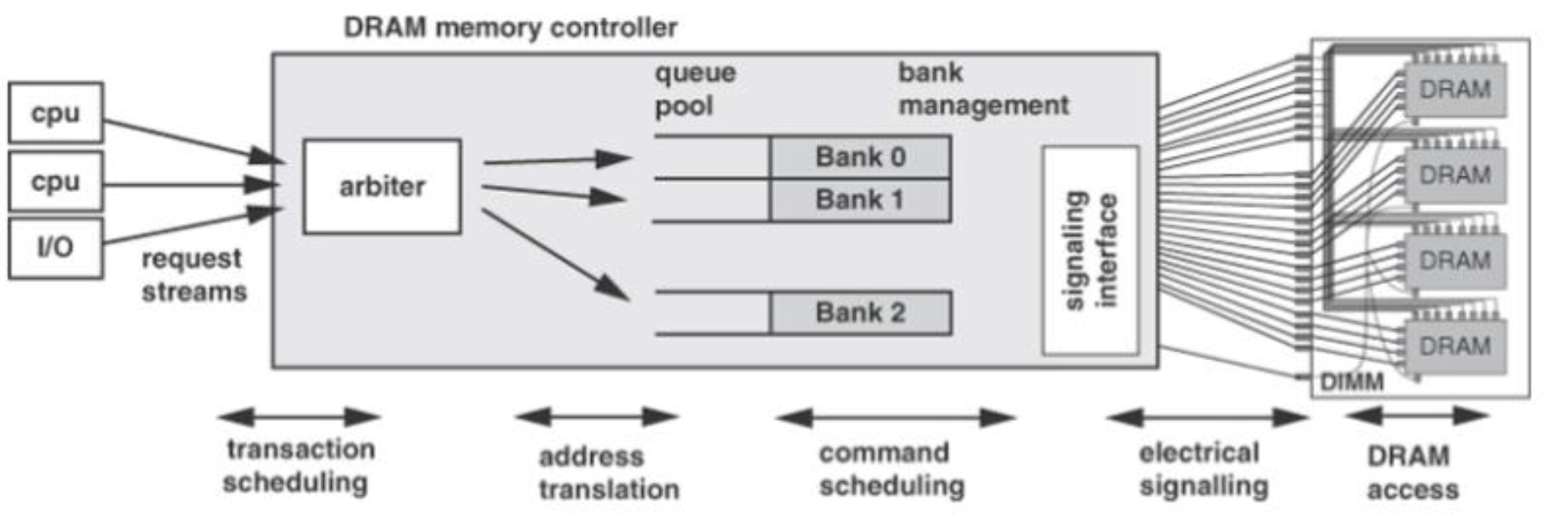
由L2 Cache发送请求到Memory Controller,由一个Buffer来对请求进行缓存
请求调度策略
-
FCFS
-
FR-FCFS,First Ready
- Row-Hit First,优先调度命中Row Buffer的请求,提高命中率
- FCFS 防止饥饿
Row Buffer管理策略
Open Row 不预先执行Precharge回写
Closed Row 预先回写
自适应结合两种方案
DRAM Controller的设计难点
时序约束
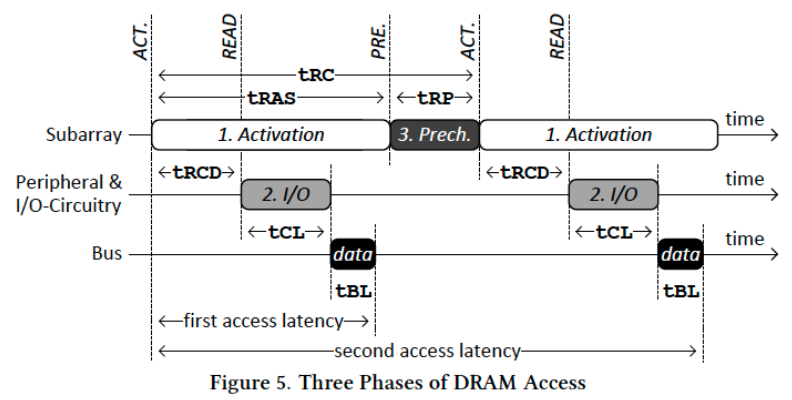
防止冲突的发生
Refresh操作
能耗管理
在不访问chip时切断供电
厂商提供多种不同功耗的工作状态
状态过渡时Chip无法被访问,因此会产生延迟
0x04 NVM
| 读 | 写 | 特点 | e.g. | |
|---|---|---|---|---|
| Charge Memory电荷存储器 | 通过检测电压V读取数据 | 通过捕获电荷Q写入数据 | 通过写放大器来读写,体积不能太小 | DRAM, Flash |
| Resistive Memory电阻式存储器 | 通过检测电阻R | 通过脉冲电流$\frac{dQ}{dt}$写入数据 | 写数据调整阻抗 | PCM, STT-MRAM,memristors |
PCM
通电加热会改变状态结晶态/非晶态,阻抗发生变化,表示0/1
写
两个状态:
- SET:保持低电压,将介质变为结晶态
- RESET:提高温度变为非晶态
读
检测结晶态($10^3-10^4\Omega$)/非晶态($10^6-10^7\Omega$)的阻抗,两者数量级差距较大
优势
比DRAM,Flash有更高的扩展能力,存储密度
每个单元的存储密度提高
Non-Volatile,不通电情况下可以保存10年以上(85摄氏度)
不需要Refresh操作,低功耗
MLC-PCM
根据电阻划分多个bit,控制距离间隔
延迟相较于DRAM高
动态能耗高于DRAM
写寿命较低
STT-MRAM
自旋距磁存储器
电流改变磁介质方向,改变阻抗
Reference Layer和Free Layer方向相同表示0,相反时表示1
优势
容量大,造价低
非易失
功耗低
缺点类似于PCM
Memristors/RRAM/ReRAM
改变原子结构