
[OSDI'21] Modernizing File System through In-Storage Indexing
Questions
核心思想部分需要再思考和梳理下,
- 为什么采用 KV SSD 替代传统 block SSD 能够解决上述问题?
- 其中,利用了 KV SSD 的什么特性?
- 对文件系统哪些地方做了什么以优化?
论文试图解决的问题:
随着存储设备的不断发展,存储设备的性能越来越高,但当前操作系统内核的文件系统在一些操作上并不能够充分利用如今存储设备的性能。
文件系统在执行数据写入时,需要执行大量操作维护元数据、进行硬盘的空间管理、维护文件系统的一致性,工作量大。
核心思想:
使用Key-Value存储接口取代传统的快设备接口。
具体实现:
提出Kevin,分为Kevin=KevinFS + KevinSSD
KevinFS
- 维护文件和目录到KV对象的映射关系
- 将POSIX系统调用转译成KV操作指令
- 保证KV-SSD的一致性
KevinSSD
- 在存储设备中索引KV对象
- 对多个KV对象提供事务操作
0x00 Intro
Kevin避免了大量元数据的维护带来的I/O放大
不需要日志即可完成崩溃一致性的维护
可以抵御文件分段后造成的性能下降
存储的文件块通过LSM进行分部排序和索引
0x01 BG && Related Work
传统块设备
提供块粒度(512B or 4KB)的访问
HDD通过维护一个间接表来处理坏块
基于闪存的SSD通过FTL来维护逻辑块到物理地址的映射索引表,以便在异地更新的NAND上模拟可重写介质并且排除坏块。
现有研究缓解了I/O调度、文件碎片化、日志相关问题,没能消除元数据的修改带来的I/O流量
DevFS实现了在存储设备内部的文件系统,直接将接口暴露给应用,调用时不用发生Trap,对于元数据的维护都在存储设备端执行,移除了I/O 栈减少了通信接口的开销。缺点是需要大量的DRAM和多核心的CPU、能提供的功能有限,还限制了快照、重复数据删除等文件系统高级功能的实现。
KV存储可以高效处理元数据和小文件的写入
LSM-Tree
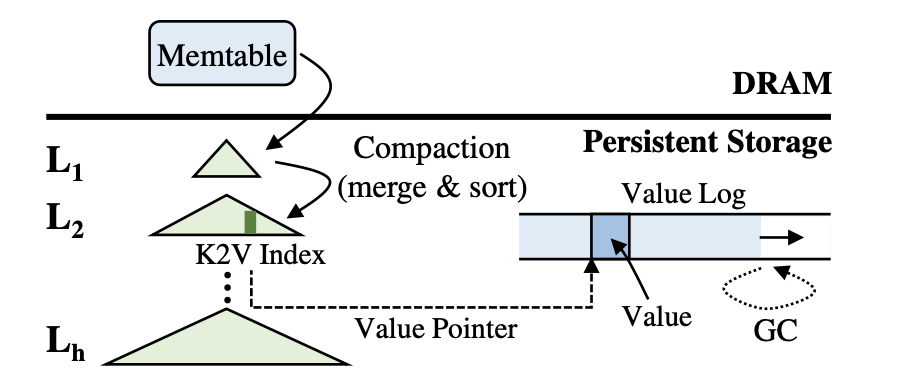
LSM Tree有多级,包括$L_1,L_2,…,L_{h-1},L_{h}$,h是树的高度,对于各级的大小有如下关系,$Size(L_{i+1})>=T*Size(L_i)$
每层都有按Key排序的唯一KV对象。各层之间的Key范围可能会出现重叠。
KV对象首先写入DRAM中的Memtable,当Memtable不为空时,缓存的KV对象将刷新到L1中进行持久化,当L1不为空时,KV对象刷新到L2中,依此类推。在刷新过程中会执行压缩操作来对两层之间的KV对象进行合并和排序,在排序后写回磁盘中。
为了改善压缩操作的I/O开销,可以将所有的value存储在value log中,在LSM tree中只保存value指针,存储<key, value pointer>形式。对于失效的value要考虑垃圾回收问题。
在对KV对象进行检索时,可能需要在多级进行查找,当在Li不匹配时,查找Li+1。为了减少多级查找的读取,可以使用布隆过滤器进行优化,当检索到目标KV对象时,LSM tree将会返回相应的value,KV分离存储的情况下,将会额外去读一次value log。
0x02 Architecture
KEVIN分为两个部分
KEVINFS:维护文件、目录到KV对象映射的文件系统
KEVINSSD:索引KV对象到闪存的LSM-tree
KV Command
支持多种KV指令,同时支持事务

作者将Key限制为256B,value大小没有限制
文件和目录的映射
KevinFS只使用三个类型的KV对象:
- $superblock$:保存文件系统的信息,大小128B
- $meta$:保存文件、目录的元数据,大小256B
- $data$:保存文件数据,unlimited,不超过文件大小
对于目录的遍历通过ITERATE
Key的命名遵循如下规则:
- meta对象的key组成:
- 前缀
m: - 父目录的inode number
- 分隔符
: - 文件/目录名
- 前缀
- data对象的key组成:
- 前缀
d: - 文件的inode number
- 前缀
Key命名规范参考了其他论文(Kai Ren and Garth Gibson. TABLEFS: Enhancing Metadata Efficiency in the Local File System. In Proceedings of the USENIX Annual Technical Conference, pages 145–156, 2013.),本篇文章将其扩展到了存储设备层面
KevinFS没有实现dentry,如果需要访问一个目录内的所有项目,可以通过ITERATE(m:50:, 2),来获取两个父目录inode为50(前缀匹配给定的pattern)的子目录/文件的元数据。
一个优化:为了防止ITERATE消耗太长时间,建议指定cnt
一个优化:为了高效处理小文件,KevinFS将总体小于4KB的小文件的元数据和数据内容打包,I/O直接操作meta对象GET/SET来进行读写
@TODO 一个优化:使用全路径索引来取代基于inode的索引,这提高了基于排序算法的KV存储的扫描性能,主要对seek time开销大的HDD优化比较明显
KV对象索引
KevinSSD基本实现了传统SSD 中FTL的所有功能,将KV对象映射到闪存、分配和释放闪存的空间。
FTL只做坏块管理和磨损均衡等简单工作。
每个Level维护一个内存表,来记录Flash中的KV对象。表的每个记录都有<start key, end key, pointer>,其中指针指向保存KV对象的闪存页面的位置,start key和end key是页面中key的范围。key的范围可以在多个Level上重叠。为了快速查找,所有记录都按开始键排序。
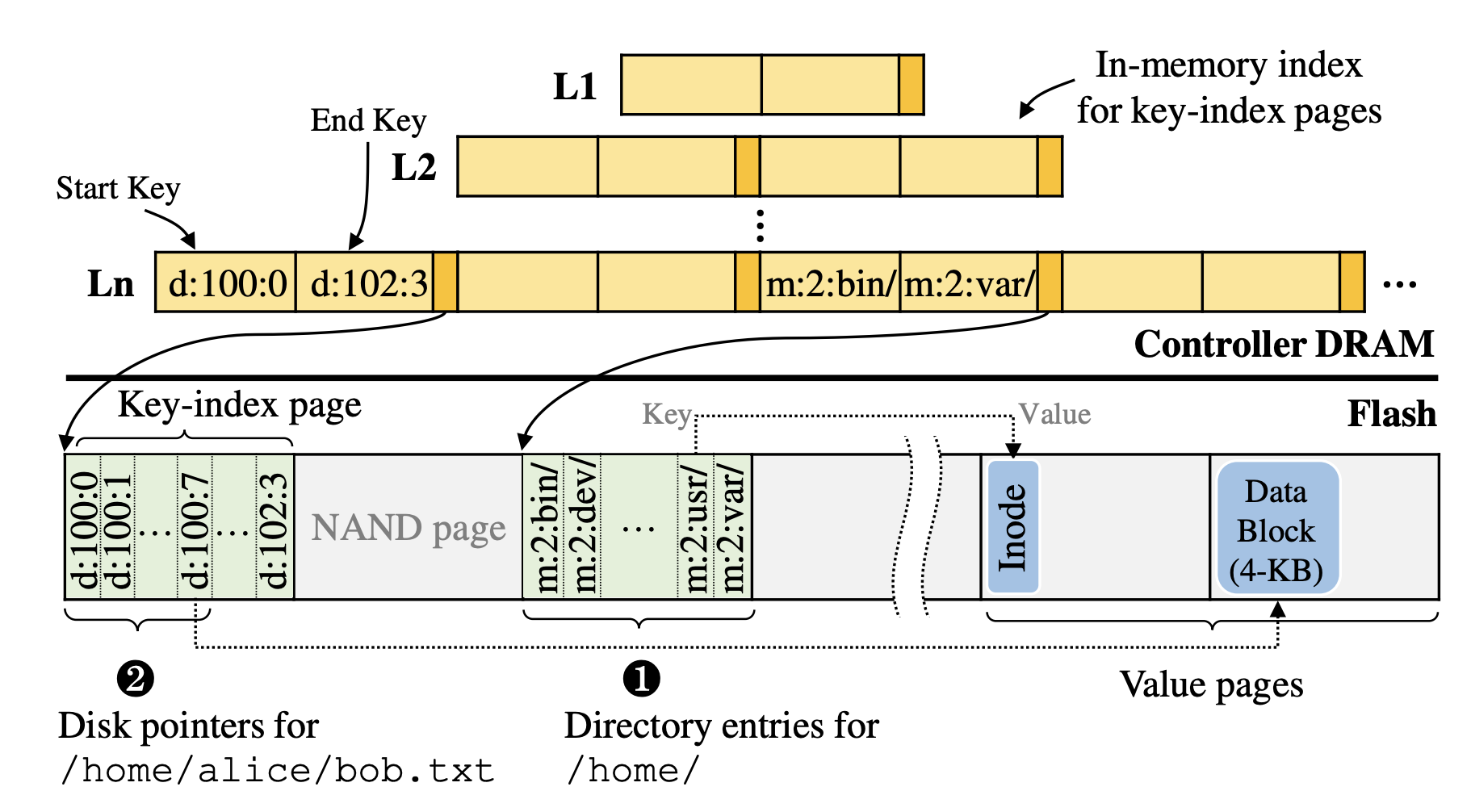
meta和data对象的Key和Value会被分离存储。通过<key, value pointer>的方式进行存储,会有专门的flash page来分别存储这些信息(meta和data对象使用不同的flash page),key-index pages
Meta object
在对KV对象进行检索时,可能需要在多级进行查找,当在Li不匹配时,查找Li+1。为了减少多级查找的读取,可以使用布隆过滤器进行优化,当检索到目标KV对象时,LSM tree将会返回相应的value,KV分离存储的情况下,将会额外去读一次value log。
对目录项的更新只需要修改其元数据即可完成,而不需要修改4KB的块
Data object
为了避免对大数据的小范围更新带来的I/O高负载,KevinSSD将data object分割为4KB大小的子对象,使用单独的后缀来对他们进行表示,后缀从0开始,拼接在原始的data object Key后,因此data object的key最终构成为 $$ d:{inode\ \ \ number}:{subobject \ \ number,start\ with \ 0} $$ 不需要中间表进行索引,只需要通过偏移量即可定位要修改的对象
Data object同样使用保存指针的方式将映射存储在key-index pages中,key-index pages会对键进行排序,因此属于同一个文件的subobject一般会在同一个flash page中。
==优化==:在查找指针时,会将一整个闪存页内的数据全部取出,存储在控制器的DRAM中,减轻后续查找可能带来的负载
缓解索引负载
使用LSM-tree由于多级查找带来额外的I/O,传统FTL的映射都保存在DRAM,因此没有额外开销。作者介绍了三种主要原因和解决方案。
压缩操作的开销
同上文介绍的方案,通过分离Value可以显著缓解I/O的数据传输负载,对data进行分片我个人感觉反而会加大压缩操作的合并过程,即使分片后键值都是有序的。
层级查找的开销
由于LSM-tree的特性,需要逐层进行查找,为了防止大量的顺序查找,作者使用布隆过滤器进行了优化。
同时还缓存了热点K2V索引数据(与目标索引处在同一个flash page中的)
为了利用大容量SSD中提供的超大DRAM,作者采用压缩存储K2V索引,并在其中插入没有压缩的K2V索引来作为二分查找的参照物。(快速在缓存中查找?不如继续用布隆过滤器)
分散的对象带来的开销
LSM-tree允许各层之间的key范围重叠,因此有同一个前缀的目录或者文件可能被分配到不同的Level中,对于获取一个目录中所有目录、文件的操作,需要对多个闪存页进行访问。这个问题作者没有给出一个明确的方案(在压缩合并时隐式解决),但是提供了一个用户工具来主动触发合并,效率较高。
作者对比了各种方法在随机读、局部读(?)、顺序读情况下对闪存页的读取次数,使用布隆过滤器的时候稳定会有一次读取
使用了KevinSSD后对于SSD而言,I/O延迟有轻微的增加,整体而言效率提高了
0x03 Implement VFS
write
所有的写相关系统调用可以通过SET和DELETE来实现。
例如unlink,只需要两次DELETE指令,移除meta和data object。
SET时现在Memtable中保存一个KV对象,然后持久化到flash中,若Key已存在则丢弃旧的对象
DELETE时在树上写入一个4B大小的墓碑
失效的对象(被SET覆盖)和删除的对象在压缩期间被永久删除
read
通过GET和ITERATE实现
如下图所示
执行open系统调用时,查询meta object获取文件的inode,通过GET命令实现
执行lookup系统调用时,给定一个完整的路径/home/alice/,从根目录开始获取多个meta object,最终获取目标文件的inode
执行read系统调用时,将GET一个data object
执行readdir系统调用时,使用ITERATE,批量获取一组meta objects来获取inode
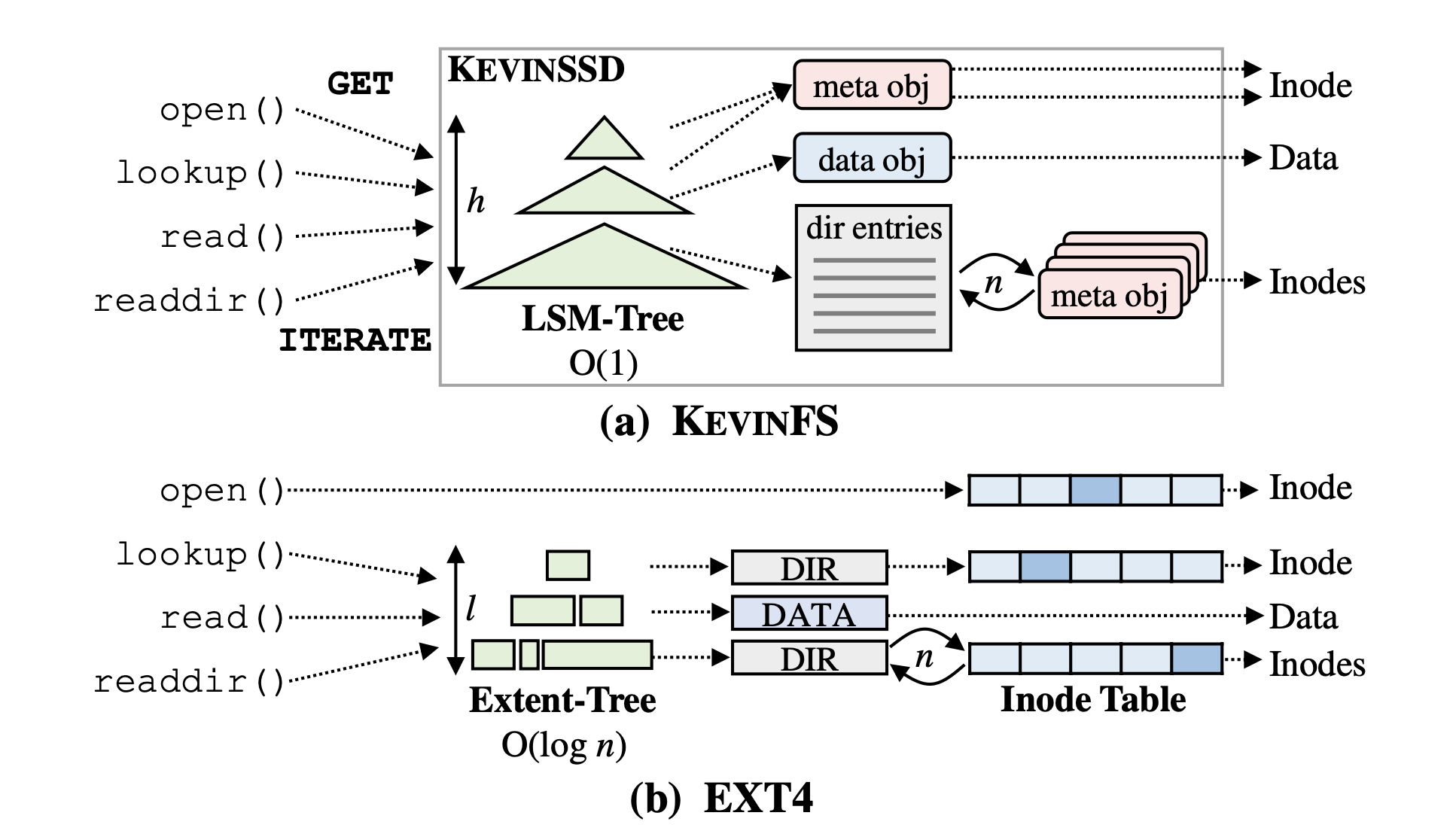
相较于Ext4,KevinFS可以更好的防止文件碎片化带来的影响。
0x04 Crash Consistency
一致性维护
通过事务即可实现原子化的操作
在传统的日志结构中,由于事务的大小受日志大小的限制,一个系统调用可能会被划分到多个事务中。KVFS通过强制限制对一个文件的操作驻留在同一个事务中来确保原子性。
事务的隔离?对==fsync==指令单独创建一个小型事务来提高效率。
KevinFS基于KV事务的特性来维护一致性,不使用日志系统。
KV事务的实现
使用了三个数据结构:
- 事务表$TxTable$:记录事务基本信息
- 事务日志$TxLogs$:维护事务对象的K2V索引,存储在DRAM或者闪存中
- 恢复日志$TxRecovery$:用于恢复和终止事务
但是收到BeginTx指令时,KevinSSD在TxTable中创建一个对象,包含TID,当前事务的状态,与事务相关K2V索引的位置,初始状态为RUNNING(如①)。当后续指令到达后,KevinSSD将KV索引记录在TxLogs,并缓存在Memtable中。
当收到EndTx指令后,完成事务的提交,标记事务状态为COMMITTED(如②)。将提交的KV索引同步到LSM-tree中
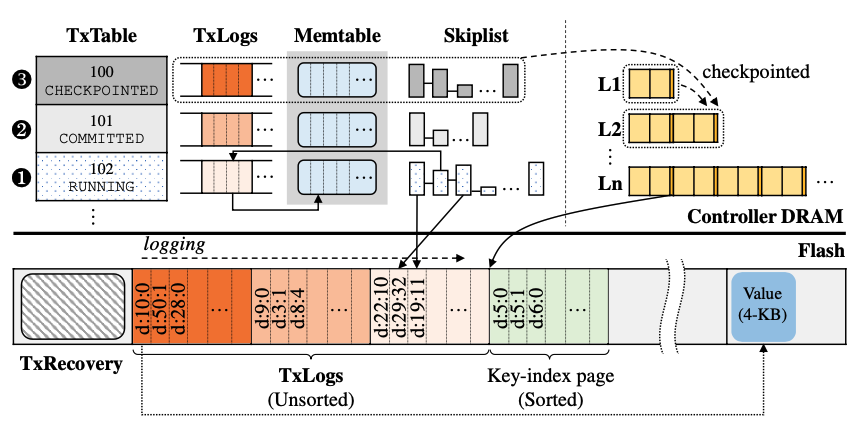
为了减少在COMMITTED阶段,将TxLogs中的KV索引同步到LSM tree L1中时的负载,对每个事务在DRAM中维护了一个Skiplist,便于快速查找KV对象在TxLogs中的索引,在L1和L2需要进行压缩时再将skiplist中的数据同步到checkpoint,当同步完成后,事务的状态将变为CHECKPOINTED(如③),最终即将对DRAM中的TxTable和TxLogs进行回收。
Recovery
若发生掉电,KVSSD会利用电容将KV索引持久化到闪存中的TxLogs,TxTable更新内部的指针,在TxRecovery中进行记录。在系统重启时,KVSSD会扫描Tx Recovery,加载最新的TxTable,对于处于COMMITTED状态的事务,将其TxLogs索引加载到Skiplist中,对于处于RUNNING状态的事务,直接进行Abort并回收其资源。
Conclusion && Thinking
本文提出了一种基于K/V存储架构的文件系统,通过对Key的设计保证了在I/O操作中的高效性。通过本文了解了一些KV存储的trick,对于KV存储的各种场景,无论是在Redis中还是在KV文件系统中,对于Key的设计都至关重要,好的设计往往能够带来极大的效率提升,例如布隆过滤器的应用,有很多经验值得学习。同时了解了对事务的一些控制机制。
此篇论文让我惊讶于文件系统还能通过KV存储来实现的通知,还让我回想起了TiDB,通过KV存储系统来实现了分布式关系型数据库,并完全兼容MySQL,说明在利用好KV存储的特性的情况下,可以有效的解决问题,要多去学习他们的设计思想。