
[FAST'22] MT^2: Memory Bandwidth Regulation on Hybrid NVM/DRAM Platforms
0x00 Intro
NVM和DRAM共享内存总线,二者之间的负载相互干扰,给混合NVM/DRAM平台的带宽分配带来了挑战
本文提出了MT2,可以在混合NVM/DRAM平台中管理并发程序间的内存带宽。
MT2首先检查内存流量间的干扰并通过硬件监视器和软件汇报从混合流量监控不同类型的内存带宽
然后MT2利用一个动态的带宽流量调节算法基于多种方式来管理内存带宽
为了能够更好的管理不同程序,MT2被集成到了cgroup中,添加了一个用于带宽分配的cgroup subsystem
新兴的NVM存储器逐渐被用来做为可持久化内存来使用,基于NVM,提出了NVM文件系统,NVM编程库,NVM数据结构、NVM数据库,NVM作为大容量内存或者快速的字节寻址存储设备用于数据中心。
然而NVM/DRAM混合平台加剧了吵闹邻居问题。在云存储环境中,多个用户常常共享一个服务器,不同用户的不同应用程序共享主机的一条总线,某些应用可能会过度使用内存带宽。在NVM/DRAM中,NVM和DRAM共享同一个总线,因此不同的应用程序将竞争有限的内存带宽,影响整体的性能
在NVM/DRAM中调节带宽有如下几个问题:
- 内存带宽不对称,在NVM/DRAM,不同的内存访问(如DRAM read,DRAM write,NVM read和NVM write)会产生不同的最大内存带宽。内存的实际可用带宽主要取决于负载中不同类型访问的占比。同时设置静态的内存带宽而不考虑实际的I/O访问占比是不正确的做法。同时NVM最大带宽通常小于DRAM。而且不同类型的内存访问的干扰程度不同,因此不能单纯将所有内存==访问延迟==视为相等
- NVM和DRAM共享内存总线,NVM流量和DRAM流量不可避免地会混合并且很难区分。对于混合的流量,监控不同种类的内存带宽。由于内存流量混合,几乎不可能在每个进程的基础上监控不同类型的内存带宽,这使为DRAM设计的现有硬件和软件调节方法无效。
- 内存调节的硬件和软件机制不足。由于NVM和DRAM都可以通过CPU负载/存储指令直接访问,因此为了性能,对每个内存访问进行计算和限流是不切实际的。CPU供应商,如英特尔,支持硬件机制来调节内存带宽。然而,带宽限制是粗粒度和定性迭代的,这不足以精确的内存带宽调节。其他一些方法,如频率缩放和CPU调度,可能会提供相对细粒度的带宽调整。然而,它们也是定性的,并减慢了计算和内存访问的速度,因此对整个平台性能缺乏影响。
MT2作为Linux Cgroup中的一个Subsystem,用于减轻吵闹邻居问题。在内存带宽分配和云SLO保证方面提高效率。本文的主要贡献:
- 发现了导致NVM/DRAM混合平台上内存密集型应用程序显著性能流失的内存带宽干扰问题
- 首次对在NVM/DRAM平台现存的硬件和软件带宽分配机制进行研究
- 高效有效地调节具有线程级粒度的NVM/DRAM混合平台上的内存带宽
- 在英特尔Optane SSD上进行了测试和分析
以下简称NVM/DRAM
0x01 BG
MT^2 持久内存(PM)/ 非易失性内存(NVM)的出现正改变着存储系统的金字塔层次结构。本文发现,由于 NVM 和 DRAM 共享同一条内存总线,带宽干扰问题变得更为严重和复杂,甚至会显著降低系统的总带宽。本工作介绍了对内存带宽干扰的分析,对现有软硬件技术进行了深入调研,并提出了一种在 NVM/DRAM 混合平台上监控调节并发应用的内存带宽的设计(MT^2)。MT^2 以线程为粒度准确监测来自混合流量的不同类型的内存带宽,使用软硬件结合技术控制内存带宽。在多个不同的用例中,MT^2 能够有效限制“吵闹邻居”(noisy neighbors),消除带宽干扰,保证高优先级应用的性能。
Noisy Neighbors
在多租户的云环境中,内存带宽对应用程序的性能有很大影响。
两种可以减轻吵闹邻居问题的方法是:
- Prevention:主动为应用程序设置带宽限制(固定的)
- Remedy:系统检测吵闹邻居情况的出现并识别出吵闹的“邻居”对其进行限制
这些方法需要去监控应用的带宽使用情况
NVM
NVM得益于其存储容量大,访问速度快的特性,正在逐步作为内存使用于商业服务器中。得益于PMDK(Persistent Memory Development Kit)同时还涌现出了大量基于NVM Memory的应用程序,如PmemKV,Pmem-RocksDB。
NVM可以直接通过CPU的load/store指令进行访问
Memory Bandwidth Interference
由于NVM和DRAM共享内存总线,因此存在干扰问题。
用两个Flexible I/O Tester来竞争总带宽进行测试,包括NVM/DRAM的读写,分别比较在不同的访问方式下的带宽干扰情况
如下图所示,颜色越深表明干扰越明显,图中数据表示为在Task B运行的情况下Task A的吞吐量占Task Alone情况下的百分比(GB/s)
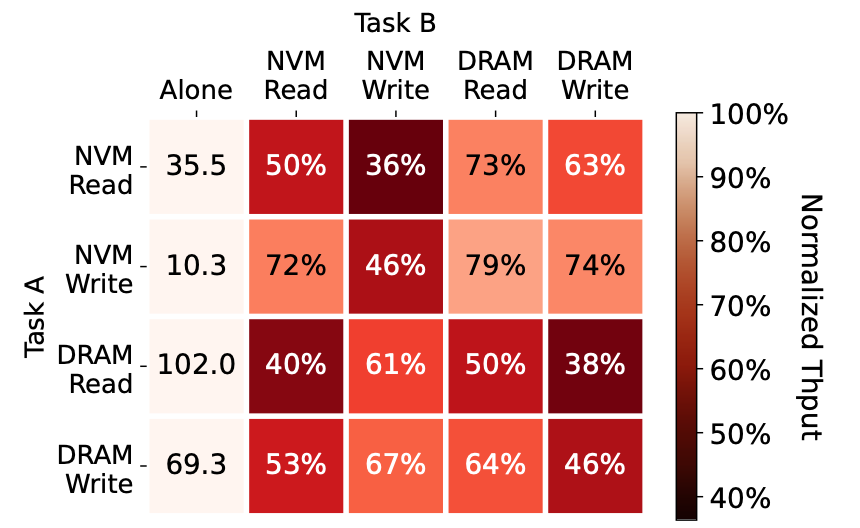
从图中得出的两个结论为:
- 内存的干扰和内存的访问情况有关,占据更小带宽的内存访问可能会对其他访问造成更大的影响
- NVM的访问比DRAM访问对其他任务的影响更大,例如图中NVM Read列和DRAM Read列的对比,说明执行NVM write较多的应用更可能成为影响其他任务
作者还做了Task B进行NVM Write,Task A的延迟和吞吐量的变化,发现了随着带宽的逐渐降低,Task A的延迟逐渐增加。
Memory Bandwidth Monitoring
Intel的MBM技术可以用来监控从L3 Cache到下一级内存系统的带宽使用情况,即NVM或者DRAM,为每个逻辑核心都提供了硬件级别的内存带宽测量。
每个逻辑核心分配了一个Resource Monitoring ID(RMID),一组逻辑核心可以分配相同的RMID,底层的硬件通过追踪具有相同RMID的内存带宽并将它们进行汇总。
Memory Bandwidth Allocation
Intel MBA技术提供间接和粗略内存带宽控制,基本无性能损失。
MBA在每个物理核心和共享L3 Cache之间引入了一个可编程的请求速率控制器,控制器通过在内存请求之间插入延迟来对内存带宽的使用进行限流。
Intel要求使用Classes of Service(CLOS)为线程进行分组,然后为每个CLOS设置一个限流值。
0x02 Design
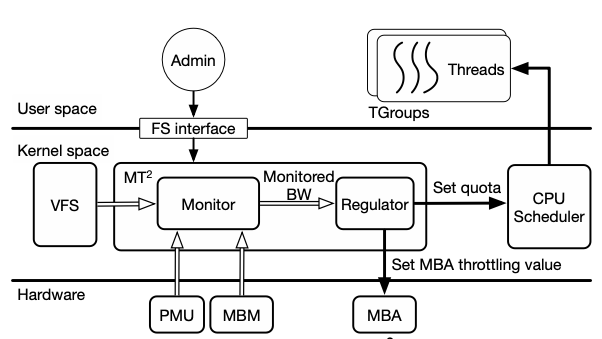
如上图所示,MT2工作在Kernel space,可以更方便高效地访问硬件信息。还能与内核其他组件高效的通信。
MT2对user space暴露了相关管理接口,系统管理员可以将线程分配到不同的group并且制定各个group所使用的带宽,称为TGroup,Throttling Group
MT2由两个部分组成:
- Monitor,负责从VFS,Performance Monitoring Unit(PMU),MBM收集性能数据,并将其分为四种类型DRAM/NVM R/W,将信息转发到Regulator
- Regulator,根据监控的数据和策略,执行两种机制:
- 调整MBA限流值
- 调整CPU配额
MT2使用动态带宽限流算法,根据实时带宽和干扰级别不断监控和调整限制。
MT2提供两种缓解吵闹邻居的方案,来适应不同场景,如上文所示:
- Prevention:系统管理员为每个TGroup设置带宽上限,MT2监控实时带宽并令所有group不会使用超过设定值的带宽。
- Remedy:对于没有超过带宽限制,但是仍然有很大影响的TGroup,可以由系统自动进行限制
划分TGroup之后,管理员限制每个TGroup的最大带宽,监控器会保证每个TGroup的带宽不会超过阈值
还要保证在大部分线程没有超过阈值时,产生的I/O干扰问题(空闲状态)
Monitor
带宽估计
monitor需要获得不同种类I/O准确的带宽,例如DRAM的read/write带宽,NVM的read/write带宽。Regulator使用这些信息来决定是否要限制每个TGroup的内存带宽。
对于NVM/DRAM的read带宽,可以直接通过PMU进行获取
- NVM Read Bandwidth:
ocr.all_data_rd.pmm_hit_local_pmm.any_snoop需要通过PMU事件计数器来检索本地NVM read的数量并乘上cache line size 即64B来得出总带宽 - DRAM Read Bandwidth:
ocr.all_data_rd.l3_miss_local_dram.any_snoopDRAM PMU counter进行统计
对于Write的统计无法通过PMU,需要利用MBM来监控每个TGroup的总内存访问带宽,为DRAM read/write Bandwidth 和 NVM read/write Bandwidth的总和。二者的Read带宽可以很容易计算出来。
只需通过周期性地收集NVM write的数量,就可以计算出一个TGroup总NVM write Bandwidth
User-Space对于NVM的write只能通过文件系统API和通过MMap后的CPU store指令操作内存来实现,对于文件系统API可以hook内核VFS并监控每个TGroup NVM write 的数量。
对于MMap的访问,作者基于app是否受信提出了两种方法:
- 对于受信任的app(来自受信用户或者公司企业),使用他们来辅助收集使用mmap方式对NVM进行的write数量。作者提出了修改后的PMDK,调用PMDK的API刷新Cache lines 到NVM或执行永久地内存写入(movnt),通过计算并统计每个线程NVM write的数量到计数器中。为了要将计数器报告给MT2,每个进程都设置一个与内核共享的页面,进程中的每个线程将其每个线程计数器的值写入页面中的不同位置。内核中的MT2定期检查计数器,并计算每个TGroup的带宽。基于PMDK的应用无序进行修改,其他应用需要对源码进行少量修改。最终根据收集的NVM write信息,继续计算出DRAM的write 带宽
$$ BW_{DW}=BW_{Total}-BW_{DR}-BW_{NR}-BW_{NW} $$
- 对于不受信的app(可能不会按照规定上传NVM write带宽信息),只能进行粗略估计。利用PEBS(Processor Event Based Sampling 处理器事件采样),用于对每个TGroup带有目的地址的内存write操作进行采样,通过比较NVM的地址范围,可以计算出NVM和DRAM中采样的write操作比例,对NVM和DRAM write进行粗略估计。
干扰检测
MT2通过测量不同类型内存访问的延迟来检测干扰级别,因为内存访问延迟与带宽负相关
MT2通过四个性能参数得到read延迟, unc_m_pmm_rpq_occupancy.all ($RPQ_O$), unc_m_pmm_rpq_inserts ($RPQ_1$), unc_m_rpq_occupancy, and unc_m_rpq_inserts,通过$\frac{RPQ_O}{RPQ_1}$来计算NVM read延迟,同理得到DRAM read延迟
MT2周期性地发起NVM和DRAM write请求,以此来测量完成时间,进而获得延迟
通过设置阈值来判断带宽是否发生干扰
干扰检测伪代码
|
|
作者使用吞吐量降低10%的延迟作为阈值
Regulator
内存调节机制
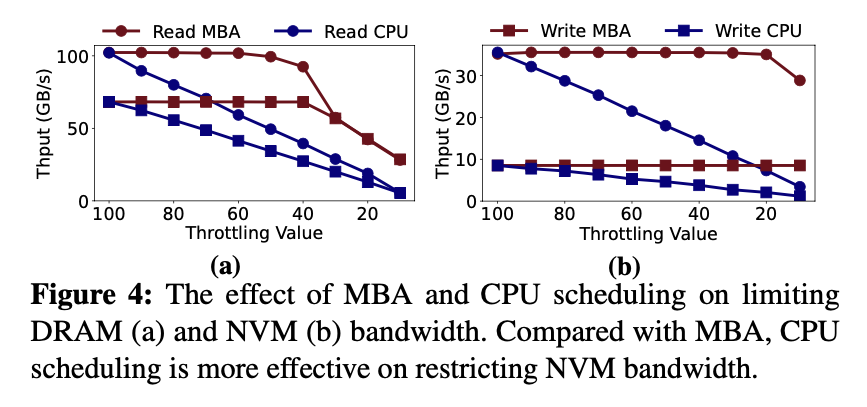
MBA,通过设置限流值来对程序进行限制。MBA只支持throttling values,不能进行太精细的控制,MBA对DRAM敏感的负载的限制效果更好,对NVM-write的限制几乎没有效果,如上图b。
CPU调度,可以进行更细粒度的内存带宽调整,利用Linux Cgroup CPU子系统来对应用使用的CPU核心进行限额。
有效性和比较,作者通过对比测试后发现,CPU限流会影响应用程序的其他任务,限制其整体的效率,而MBA进对内存的访问进行限制,对程序整体的运行影响较小。

动态带宽限流
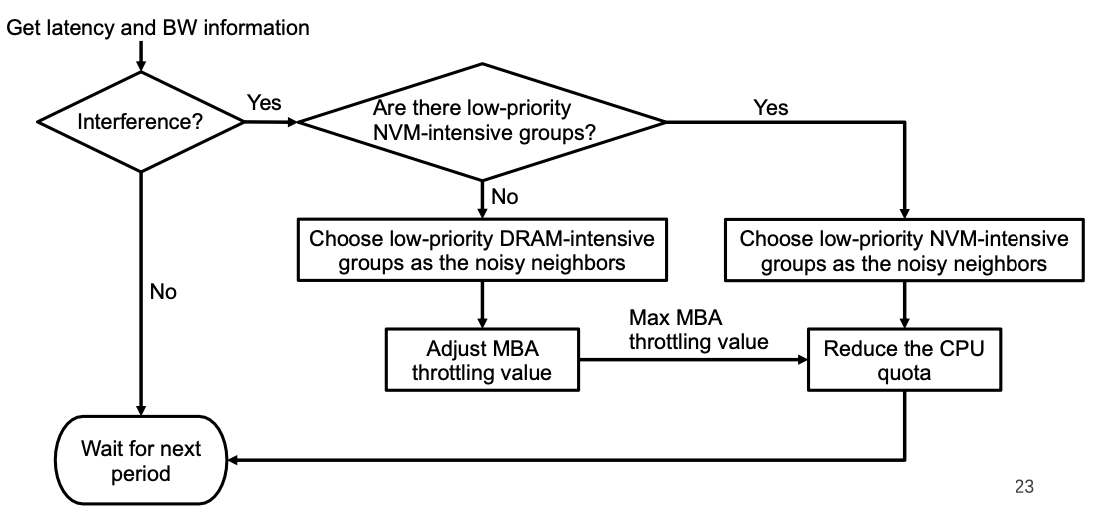
识别吵闹邻居
Prevention策略,所有超过带宽上限的TGroup都被视为吵闹邻居
Remedy策略,Regulator首先根据Monitor提供的信息检查是否存在严重的内存干扰,当内存干扰情况严重时,算法会根据每个TGroup的带宽使用情况识别吵闹邻居,根据上文的分析,包含NVM write操作最多的TGroup最有可能是吵闹邻居,因此算法要选取这类TGroup并进行限流。
调节内存带宽
算法会根据内存访问的类型来选取调节方法。
对于NVM访问带宽的限制,算法采用CPU限制
对于DRAM访问带宽的限制,算法首先削减其TGroup的MBA,如果MBA已经设定为最小值,算法将使用CPU限流来进一步调节。
释放内存限制
一旦内存干扰消失,算法就会尝试放宽带宽限制,操作过程和施加内存限制的方式相反。
当Regulator结束了一次调节/释放操作时,就会继续等待下一步操作,取决于Monitor提供的信息。
整体的工作流程在作者的Slides上有一张图:
0x03 Implementation
Cgroup接口
Cgroup是Linux内核中用于资源限制的工具,常用于容器化技术,目前正在整理有关内容计划分享一下。
Cgroup通过暴露伪文件系统的文件实现其接口,Cgroupfs,用户通过修改文件的内容完成配置工作,MT2遵循Cgroup规范添加了TGroup,用于限流和管理的主要有以下几个文件:
priority:用于设置TGroup的优先级,包括high和low,high优先级的TGroup不会被Regulator限制,low优先级则会在内存干扰情况发生时被限制。bandwidth:该文件只读,返回TGroup当前的带宽使用情况limit用于获取和设置TGroup的绝对带宽,四个逗号分隔的数字来代表四种内存访问带宽上限,一旦带宽超过该值TGroup就会被限流。Zero Value表示无限制,该配置立即生效。
线程创建问题
所有子进程都与父进程放在同一个TGroup中,除非管理员手动将其放入另一个TGroup。为此作者在进程/线程创建程序中添加了一个hook,即Linux内核中的fork。
MBA
MBA支持10个限流值,由于70、80、90的效果较差,作者只使用其中的8个值,并将每个值分配到一个CLOS中,将TGroup分配到相应的CLOS来实现不同等级的限流。在没有干扰的情况下,具有相同CLOS的TGroups有相同的请求速率。
上下文切换
为了给每个线程设置MT2上下文,包括设置PMU相关的上下文、写入与MBA相关的MSR寄存器以及设置CPU配额,作者给调度器添加了一个hook。每次发生上下文切换时,我们就为将要在这个CPU核上运行的新线程设置相应的MT2上下文。
PMU
用于计算没有命中Cache而进行NVM和DRAM访问的所有read指令。对于DRAM和NVM的read操作延迟也通过PMU获取。
PEBS
采样频率为10007,PEBS将每10007个事件记录一个线性地址,不会对系统产生太大的性能影响。
专有内核线程
在MT2内核模块的初始化阶段创建一个内核线程,定期检测内存干扰,监控带宽并执行动态带宽限流。
内核线程的伪代码如下
|
|
0x04 Thinking
作者在内核中实现了线程粒度的内存带宽监控,同时利用了多种方法来实现内存带宽的限流。
同时利用了分析DRAM/NVM读写带宽之间的相互影响,从而确定了优化的方向和方法。
本文章来自SJTU的IPADS实验室,文章中的论述非常有条理,采取的每一项措施都有实验验证,有例可循,例如选取NVM write操作较多的TGroup作为干扰项,以及MBA和CPU限额综合调整带宽,都有相应的实验分析。