
【存储系统】多硬盘存储系统
0x00 多硬盘系统
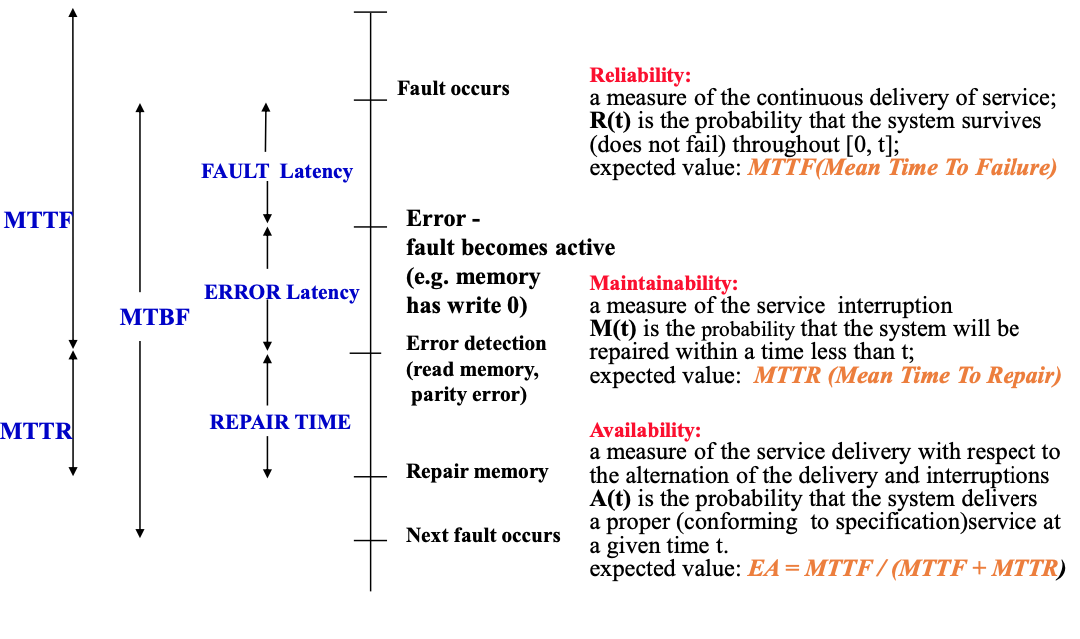
对多硬盘系统可靠性的度量,上图从故障产生,故障产生程序错误,错误检测,修复故障四个时间节点为一个周期。
三个可靠性的指标:
可靠性:通过错误产生到发现错误的时间间隔MTTF来衡量
可维护性:通过发现错误到错误修复的时间间隔来衡量,定义系统修复的能力
可用性:通过系统中非修复时间所占的比例,可以对外提供服务的时间占比,$EA=\frac{MTTF}{MTTF+MTTR}$
MTBF=MTTR+MTTF,两故障之间的时间间隔
恢复一块硬盘的代价很高,为了提高系统可用性,需要构建多盘系统,在某块磁盘故障时仍然能正常工作。
每秒的I/O请求峰值为1200,R/W比例为2:1,分别使用RAID 1/5,计算峰值的硬盘负载
总的R/W分别为800/400
RAID 1:写操作需要翻倍,总负载为800+400*2=1600
RAID 5:写操作翻四倍,总负载为800+400*4=2400
使用多盘系统的目的:
- 提高存储容量
- 提高性能
- 负载均衡
- Disk Striping
- 带宽
- 吞吐量
- 负载均衡
- 提高可靠性
- 容错
- 基于奇偶校验的保护
- 创建副本
- 容错
JBOD(Just a Bunch Of Disks)单纯对硬盘进行组合,只提高存储容量
负载均衡
静态:某一地址固定映射到某块硬盘
动态:热点数据分配到不同的硬盘中
按照数据块:将一个数据划分后存储到所有硬盘中(Disk Striping 条带化)
Disk Striping
按一定大小对数据分块(stripe unit/block),然后依次存储到各个硬盘中
分配规则使用轮询枚举,通过取模判断存储的磁盘编号,根据余数确定偏移量
Stripe Unit大小设置一般为2M、4M、16M,太大丧失负载均衡能力,太小会在寻址上花费太多时间
磁盘失效
对于JBOD、Striping某块盘失效,整个文件系统都将失效
可以通过备份来解决,要花费较长的时间
多盘系统的MTTF为第一块磁盘失效的时间,比单盘系统时间短很多
解决方案:Redundancy冗余存储
Redundancy
存储副本
存储两份或更多的副本,采用三副本的服务有HDFS/GFS/Cloud Storage
Disk Mirroring
磁盘镜像,分主从磁盘,从盘基于主盘进行同步,可以从任意盘进行读取
-
有较高的可用性
-
花费较高
-
写性能降低,磁盘之间需要同步,受限于最慢同步的磁盘
-
读性能提高,请求被分散到各个磁盘
磁盘镜像可以与结合条带化
先做Mirroring再做Striping (RAID 10)
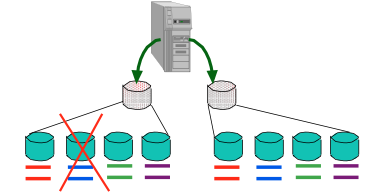
若有磁盘故障,会损失1/2的数据
先做Striping再做Mirroring (RAID 01)
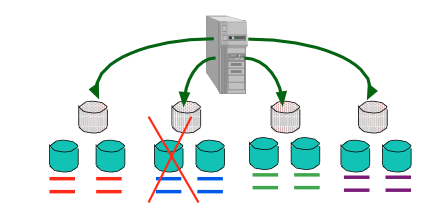
若有磁盘故障,不会影响整体的读写,可以保证可靠性
Shadowing
不对外服务,只充当备份
Duplexing
可进行交换
ECC(Error-Correcting Codes)
纠错码常用方案有RAID,纠删码,奇偶校验
Parity Disk
增加一块检验盘,保存其他盘上数据的异或值
奇偶校验:统计数据中1的个数,奇数为1,偶数为0
43:25
0x01 RAID
通过廉价磁盘构建可靠大型高端存储,类似MapReduce通过廉价服务器来构建高性能计算集群
RAID 0 条带化,无冗余存储
RAID 1 Mirroring
RAID 2 条带化+海明码冗余存储
RAID 3 条带化+奇偶校验 细粒度
RAID 4 块条带化+奇偶校验 粒度大
RAID 5 块条带化+条带化的奇偶校验
RAID 6 块条带化+两个条带化的奇偶校验
RAID 0无容错,RAID 1-5支持一个单位的容错,RAID 6支持两个单位容错