
[FAST'23] More Than Capacity: Performance-oriented Evolution of Pangu in Alibaba
[FAST'23] More Than Capacity: Performance-oriented Evolution of Pangu in Alibaba
FAST'23 会议论文翻译,《不仅仅是容量:盘古面向性能的演变》
本论文讲述了Pangu存储系统是如何随着硬件及商业需求,去演变提供更高的性能的,存储服务的I/O延迟达到了100-us。盘古的演变主要有两个部分:
- Phase 1: 盘古通过优化文件系统并设计了用户端的存储操作系统,积极引入高速SSD和Remote Direct Memory Access(RDMA)网络技术。因此,盘古在有效降低了I/O延迟的同时,还提高了吞吐量和IOPS。
- Phase 2: 盘古从面向卷的存储供应商转变为面向性能。为了适应这一商业模式的改变,盘古使用足够多的SSD和25Gbps-100Gbps的RDMA带宽更新了基础设施。这引入了一些列的关键设计,包括减少流量放大,远程直接缓存访问,和CPU计算卸载,来保证盘古完全获得基于硬件升级所带来的性能提升。
除了技术上的创新,作者还分享了盘古发展过程中的运营经验,并讨论了其中的重要教训。
0x00 Intro
盘古的开发始于2009年,目前已经是阿里巴巴集团和阿里云统一存储平台。盘古为阿里的核心业务提供了可伸缩性、高性能和可靠性。
Elastic Block Storage(EBS), Object Storage Service(OSS), Network-Attached Storage(NAS), PolarDB, MaxCompute这些云服务基于盘古建立。经过十几年的发展,盘古已经成为了一个拥有ExaBytes并管理万亿文件的全局存储系统。
盘古 1.0: 提供存储容量
Pangu 1.0设计于2009-2015年,通过高性能的CPU和HDD组成,可以提供ms毫秒级别的I/O延迟和Gbps级别的数据中心带宽。
Pangu 1.0基于Linux Ext4设计了一个分布式的内核文件系统和内核TCP,并给予不同种类的存储服务提供多种文件类型支持(Tempfile,LogFile,Random Access file)。
此时正处于云计算的初始阶段,性能受限于HDD性能和网络带宽,相较于更快的访问速度,用户更关注存储容量。
新的硬件,新的设计
自2015年起,为了引入新兴的SSD和RDMA技术,盘古2.0开始设计和开发。盘古2.0的目标是提供100us级别I/O延迟的高性能的存储服务。尽管SSD和RDMA在存储和网络中实现低延迟、高性能的I/O,团队发现:
- 盘古1.0中使用的多种文件类型,特别是允许随机访问的文件类型,在固态硬盘上的表现很差,而固态硬盘在顺序操作上可以实现高吞吐量和IOPS。
- 由于数据复制和频繁的中断,内核空间的软件栈无法跟上SSD和RDMA的高IOPS和低I/O延迟。
- 从以服务器为中心的数据中心架构向资源分散的数据中心架构的范式转变,对实现低I/O延迟提出了额外的挑战。
盘古2.0 Phase 1: 通过重构文件系统与用户空间的存储操作系统来拥抱SSD和RDMA
-
为了实现高性能和低I/O延迟,盘古2.0首先在其文件系统中的关键组件提出了新的设计。为了简化整个系统的开发和管理,盘古设计了一个统一、追加写入的持久化层。它还引入了一个独立的分块布局,以减少文件写入操作的I/O延迟。
-
盘古2.0设计了一个用户空间的存储操作系统(USSOS),USSOSS使用一个RTC(Run to completion)线程模型来实现用户空间存储栈和用户空间网络栈的高效协作。它还为高效的CPU和内存资源分配提出了一个用户空间的调度机制。
-
盘古2.0部署了在动态环境下提供SLA保证的机制。通过这些创新,盘古2.0实现了毫秒级别的P999 I/O延迟。
盘古2.0 Phase 2: 通过基础设施更新和突破网络/内存/CPU瓶颈,适应以性能为导向的业务模式
2018年起,盘古逐渐从容量导向的商业模式转变为性能导向。这是因为越来越多的企业用户将他们的业务转移到了阿里云并且他们对存储性能的延迟和性能有很严格的要求。这在COVID-19疫情爆发之后变得越来越快,为了适应这一商业模式转变和日益增长的用户,盘古2.0需要继续升级基础设施。
用原有的服务器和交换机沿着基于CLOS架构的拓扑结构来对基础设施进行扩容是不经济的,包括高昂的总成本(机架空间、电力、散热、人力成本)和更高的碳排放/环境问题。因此,盘古开发来室内高容量存储服务器(每个服务器96TB SSD)并且升级到了25Gbps-100Gbps的网络带宽。
为了完全获得这些升级带来的性能提升,盘古2.0提出了一系列的技术来处理在{网络/内存/CPU}的性能瓶颈并充分利用其强大的硬件资源。具体来说,盘古2.0通过减少网络流量放大率和动态调整不同流量的优先级来优化网络带宽;通过提出Remote Direct Cache Access(RDCA)来处理内存瓶颈;通过消除数据序列化/反序列化的开销并引入CPU等待指令来同步超线程,以此来解决CPU瓶颈问题。
生产中的高性能
盘古2.0成功支持了elastic SSD block存储服务,并可达到100us级别的I/O延迟和1M的IOPS。在2018年双十一活动,盘古2.0加持下的阿里数据库实现了280us的延迟。
对于OTS存储服务,同样的硬件条件下。盘古2.0的I/O延迟比盘古1.0降低了一个数量级。
对于写敏感的服务(EBS云盘),P999 I/O延迟低于1ms。
对于读敏感的服务(在线搜索),P999 I/O延迟低于11ms。
在第二阶段,通过将2x25Gbps带宽升级到2x100Gbps,并解决了网络、内存、CPU瓶颈,每台泰山存储服务器的有效吞吐量增加了6.1倍。
Elastic SSD Block/EBS云盘:是为阿里云为云服务器ECS提供的低时延、持久性、高可靠的块级随机存储。块存储支持在可用区内自动复制用户的数据,防止意外硬件故障导致的数据不可用,保护业务免于硬件故障的威胁。
OTS:Open Table Service,已更名Table Store,是构建在阿里云飞天分布式系统之上的NoSQL数据库服务,提供海量结构化数据的存储和实时访问。Table Store以实例和表的形式组织数据,通过数据分片和负载均衡技术,实现规模上的无缝扩展。
0x01 Bg
Overview
盘古是大规模分布式存储系统,由:盘古核心,盘古服务层,盘古监控系统组成(Figure 1)。
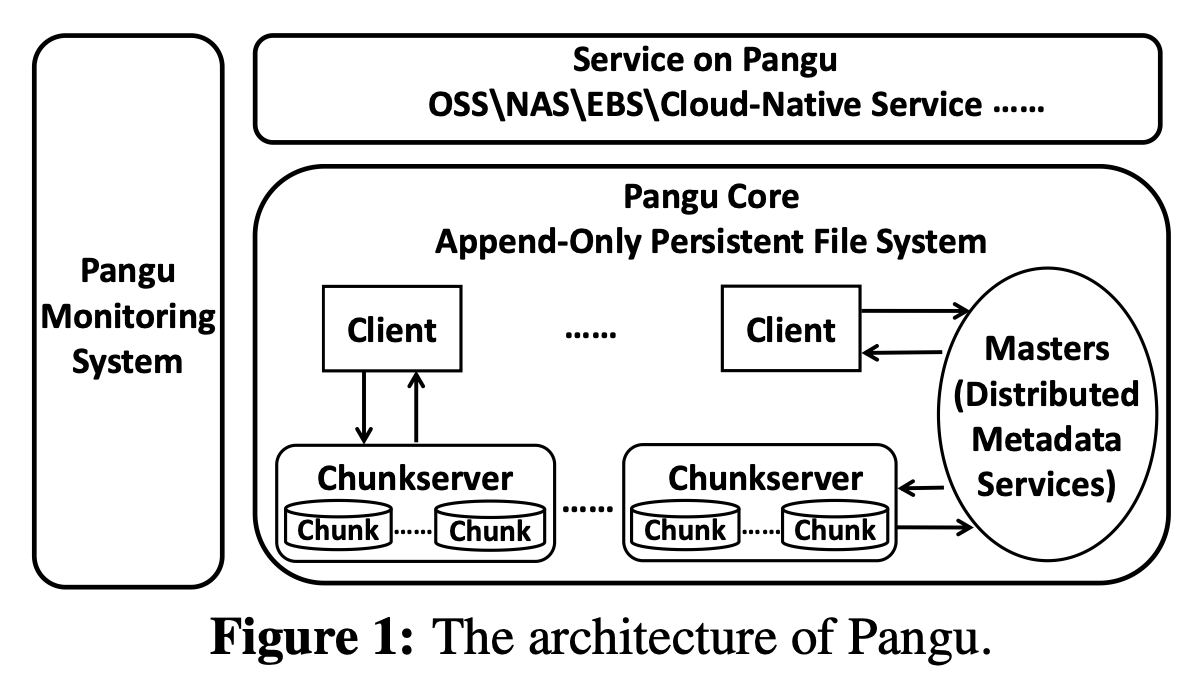
盘古Core
盘古核心由:clients,masters,chunk severs组成,提供追加写入的存储语义。
Client提供访问盘古云存储服务(EBS,OSS)的SDK,并负责接收从服务端发送的文件请求,与masters和chunk servers通信来实现这些请求。类似于其他分布式文件系统(Tectonic,Colossus),盘古中的Clients负责较重的工作并在盘古的复制管理、SLA保障、数据一致性管理中扮演关键角色。
Master管理盘古中的所有元数据并使用基于Raft的协议来维护元数据的分布式一致性。为了更好的水平扩展性和延伸性(大量的文件数),盘古master分解元数据服务为两个部分:namespace服务和stream meta服务,stream是一组chunk的抽象。这两个服务首先根据目录树分隔元数据来实现局部原数据,然后通过哈希将这些stream进一步分隔以达到负载均衡。namespace服务提供文件的信息(目录树和命名空间),stream元数据服务提供从文件到chunk的映射(chunk的位置)。
ChunkServers以chunk存储数据并配备有自定义的用户空间存储文件系统(USSFS),USSFS为不同硬件(SMRSTORE for HM-SMR drives)提供高性能,追加写入的存储引擎。在盘古2.0的第一阶段,每个存储在chunkservers的文件都有三个冗余,由GCWorker进行垃圾回收,并使用EC(Erasure Coding)编码来存储文件。在盘古2.0的第二阶段,在商业模式中,使用EC替换3个冗余的存储方式来减少流量放大。
盘古Service
盘古服务层提供传统的云存储服务(EBS、OSS、NAS),通过面相云原生的文件系统(Fisc)提供云原生存储服务。
盘古Monitoring System
Perseus为盘古核心和盘古服务提供实时监控和人工智能辅助的根本原因分析服务。盘古Core、盘古Service、盘古Monitoring System通过高速网络相连。
盘古2.0的设计目标
- 低延迟:盘古2.0要利用SSD和RDMA低延迟的特性,在计算-存储分离架构中实现平均100us级别I/O延迟的性能目标,即使在网络流量抖动和服务器故障等动态环境下,也能提供毫秒级别 P999 SLA。
- 高吞吐量:使存储服务器的有效吞吐量接近其容量。
- 为所有服务提供统一的高性能支持:为运行在其上的所有业务提供统一的高性能支持,例如在线搜索、数据流分析、EBS、OSS和数据库。
Related Work
目前有很多分布式存储系统被提出和使用
开源:
私有:
- GFS(Google)[SOSP'03] The Google File System
- Tectonic (FaceBook)[FAST'21] Facebook’s Tectonic Filesystem: Efficiency from Exascale
- AWS
阿里巴巴的盘古团队分享过很多盘古的设计理念,包括:
- RDMA大型部署,[NSDI'21] When Cloud Storage Meets RDMA
- 横向扩展云存储服务的Key-Value键值存储引擎[SIGMOD'21] A Key-Value Engine for Scalable Cloud Storage Services
- EBS存储服务的网络和存储软件栈协同设计[SIGCOMM'22] From Luna to Solar: the Evolu- tions of the Compute-to-Storage Networks in Alibaba Cloud
- namespace元数据服务的关键设计[FAST'22] InfiniFS: An Efficient Metadata Service for Large-Scale Distributed Filesystems
0x02 Phase One: Embracing SSD and RDMA
相较于HDD和TCP,SSD和RDMA技术显著降低了I/O延迟和网络问题。
盘古通过开发用户空间存储操作系统并提出一些文件系统的设计来实现高吞吐量、100us级别I/O延迟的高IOPS性能。同时提供了新的机制来保障SLA。
Append-Only File System
盘古提出了统一、追加写入的持久层,通过名为FlatLogFile的追加写入接口来简化架构。FlatLogFile具有高吞吐量和低延迟。基于FlatLogFile,盘古采用追加写入的chunk,并使用独立chunk布局来管理chunkserver中的chunk
Unified, Append-Only Persistence Layer
盘古的持久化层为存储服务提供接口。在早期开发阶段,不同的存储服务会使用不同的接口,例如LogFile接口服务于低延迟的NAS服务,TempFile接口服务于高吞吐量的大型计算数据分析服务。然而,这种设计使开发和管理非常复杂。每个接口都需要有人开发和维护,人力成本高切容易出错。
因此,需要简化开发管理过程,还要引入低延迟的SSD,受到计算机网络分层架构的启发,盘古提出了统一的文件类型:FlatLogFile(Figure 2)。
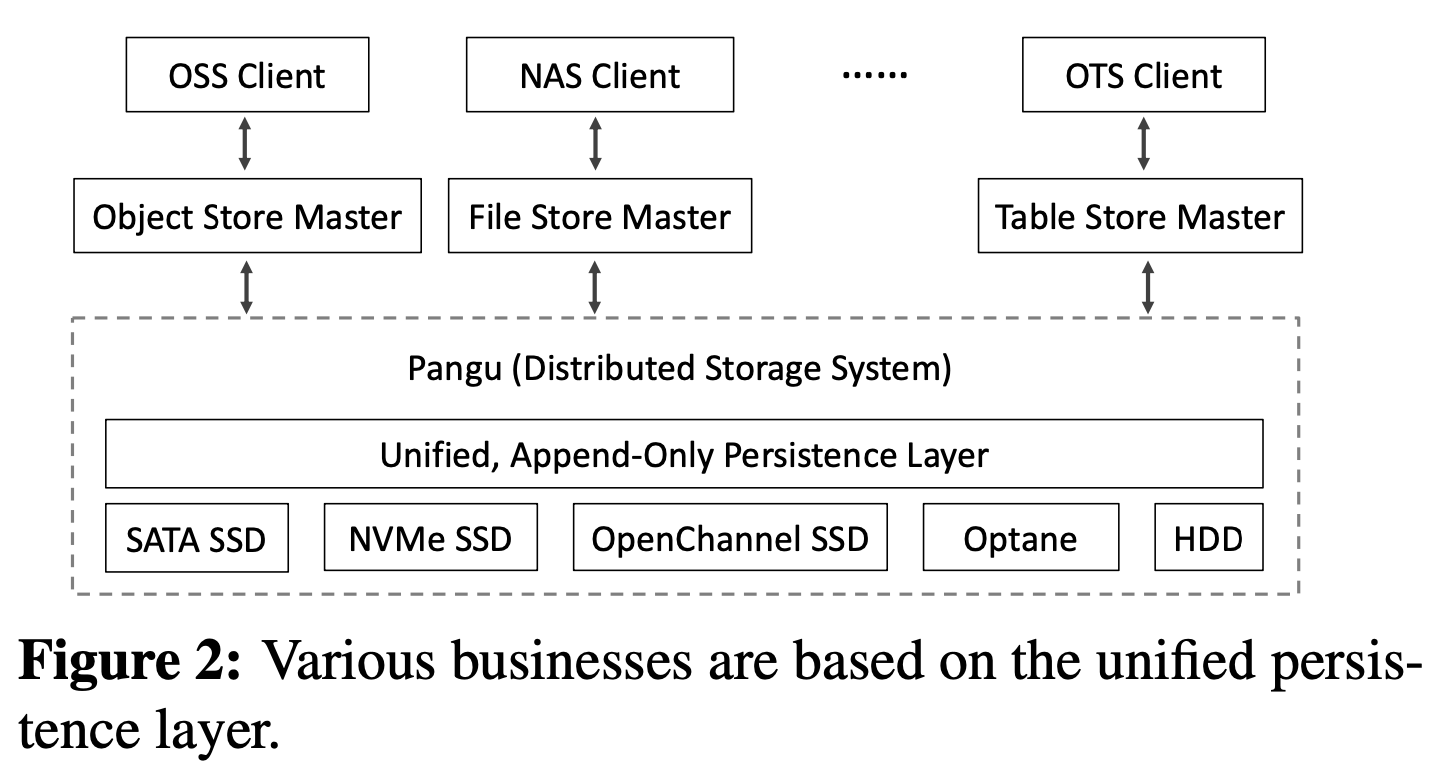
FlatLogFile仅支持追加写入,上层服务(OSS)可以可以使用类似键值的映射来更新数据,并使用垃圾收集机制来压缩历史数据。FlatLogFile为存储服务提供简单、统一的接口操作数据。盘古的开发者必须保证数据操作都是通过FlatLogFile,尤其是写入操作,可以高效并可靠的在存储介质上执行。因此,存储服务的任何升级和改变对于开发者而言都是透明的,简化了开发和管理。
在底层,团队观察到SSD由于其自身的存储单元和闪存事务层的特性,可以在顺序操作上获得较高的吞吐量和IOPS。为了保证通过FlatLogFile进行的数据操作能够在SSD上高效地执行,我们将FlatLogFile上的顺序操作对齐以实现高性能。
Heavy weight Client
脏活累活都是Client来干。Client负责与chunkservers一起进行数据操作,与master一起进行元数据信息的检索和更新。在从masters获取chunk信息后,一个盘古Client将负责相应的复制协议和EC协议。Client有重试机制(备份读取¥3.3)来处理意外的性能抖动(丢包)来保障I/O SLA。
Client还有探测机制,定期从masters获取最新的 chunkserver 状态,并评估 chunkserver 的服务质量。类似于Facebook Tectonic FS的client,盘古的Client可以选择合适的读写参数来处理具体的存储服务指令(EBS/OSS)。
Append-Only Chunk Management
传统的文件系统在写入文件时,同时分离写入文件的元数据,产生两次SSD的写操作。
为了降低延迟和延长SSD寿命,盘古基于FlatLogFile的append-only语义,选择以chunk为单位存储文件,而非block,chunk存储在chunksever中,并有独立的布局,每个chunk都保存了自己的数据和元数据信息。
chunk只需要一次操作就可以被写入到存储介质中,可以有效减少写入延迟和存储介质的寿命。
Figure 3是chunk的布局。
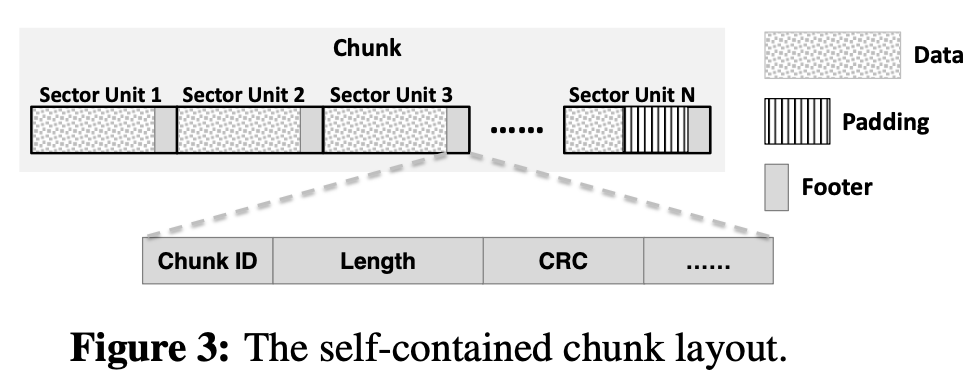
一个chunk包含多个部分,每个部分包含三个元素:data、padding、footer。
footer保存了chunk的元数据,例如chunk ID、chunk 长度、CRC校验和。
独立的chunk布局也使得chunkserver可以执行进行纠错恢复。例如,当一个client连续写入chunk到存储设备时,chunkserver在内存中存储这些chunk的元数据,并且周期性地将这些信息的检查点传递给存储设备。当发生错误导致一些不能完成的写入操作时,chunkserver会加载检查点中的元数据并且和chunk中的元数据进行比较,如果二者不同,chunkserver会检查Chunk的CRC来进行恢复。
Metadata Operation Optimization 元数据操作优化
盘古的Master提供两种元数据服务:
- namespace:负责目录树和文件管理
- Stream:负责chunk信息的维护
Stream内包含一组chunk,同一个Stream中的chunk保存在一个文件中。
这两个服务都是用了分布式架构来保证更好的伸缩性。
他们根据元数据局部性和负载均衡对元数据进行划分(先根据目录树划分,再进行哈希)。
同时还用多种机制来优化元数据操作的高效性。
并行的元数据处理
namespace和stream都使用并行处理(InfiniFS)来实现元数据的低延迟访问。
盘古使用哈希算法来映射关联性强的元数据到不同的元数据服务器中。使用一种新的数据结构,支持可预测的目录ID,并允许Client高效地平行执行路径解析。同时还引入了几种加速Client从Stream服务中检索chunk信息的技术。
可变长度的chunk
盘古2.0采用大chunk,有三个好处:
- 减少了元数据的数量
- 避免了Client频繁请求chunk产生的I/O延迟
- 提高了SSD的寿命
如果仅仅提高chunk size会有碎片的风险,因此采用了可变长度的chunk(从1MB到2GB)。
例如EBS服务的chunk size的95%分位数为64MB,99%分位数为286.4MB。
在Client中缓存chunk信息
每个client维护了一个本地的元数据缓存池,来减少元数据的请求次数。缓存池通过LRU进行维护。
当一个程序想访问数据时,client首先访问元数据缓存,当缓存没有命中时将发起对master的请求,当缓存命中时,响应请求时,对应的chunkserver会通知client其元数据已经过期(由于副本迁移)。
批处理chunk信息请求
每个client在短时间内汇总多个chunk请求,并将其批量发送给master,来提高查询效率。主站并行处理成批的请求,汇总结果并将其发回给client。client对结果进行分解,并将其分配给相应的应用程序。
推测chunk信息进行预取
设计了一个基于贪心和统计学的预取机制来减少chunk信息的请求。
当master节点收到了来自client的读请求时,master将返回有关的chunk元数据和其他chunk的元数据。
当master收到写入请求时,master将返回多个chunk,超出client的请求数量。
client因此可以在不请求块的情况下切换块。
数据捎带减少往返时延
受到了QUIC和HTTP3的启发,使用数据捎带来改善写入延迟,在client从master检索到chunk地址后,他将chunk创建请求和数据写入请求合并为一个请求,然后发送给chunkserver。
因此可以减少一个RTT。(但是当个RTT长了,数据包大小问题?)
ChunkServer USSOS
chunkserver负责执行所有的数据操作。因此,精心设计运行时操作系统以确保数据操作能以低延迟和高吞吐量完成是非常重要的。在新兴的高速网络技术和存储领域,坚持通过内核空间进行数据操作的传统设计是低效的。这不仅会导致频繁的系统中断,从而消耗CPU资源,而且还会导致用户空间和内核空间之间不必要的数据重复。 为了解决这些问题,盘古采用了kernel-bypass绕过内核的设计,为chunkserver开发了一个高性能的用户空间存储操作系统,它提供了一个统一的用户空间存储软件平台。除了在USSOS中实现设备管理和RTC运行到完成的线程模型,盘古还实现了用户级的内存管理,轻量级的用户空间调度策略,还为SSD定制了高性能append-only的用户空间存储文件系统(USSFS)。
用户级别内存管理
chunkserver的USSOS基于现有的用户空间技术,如网络栈中的RDMA,存储栈中的DPDK和SPDK。盘古对网络栈和存储栈进行了整合,以减少延迟并实现高性能的数据操作。
- 使用RTC线程模型,在传统的流水线pipeline线程模型中,一个请求被分解成多个阶段,每个阶段运行在一个线程中。相反,USSOS中一个请求自始至终都处于一个线程里,减少了上下文切换和线程间通信的开销。
- 线程请求一个大页内存空间用作网络栈和存储栈的共享内存。从网络中接受的数据可以通过RDMA存储在大页内存空间中。发送大页内存的元数据之后(地址和大小),数据可以直接通过SPDK从大页内存写入到存储设备。
用户空间的调度机制
通过阻塞后续请求阻止任务
每个chunkserver都有固定数量的线程。
一个新的请求通过哈希映射被下发给一个working线程。被发送到同一个线程的请求基于先到先执行FIFS的机制执行。
如果一个请求占用了太多的时间片(表查询搜索,内存申请),将会阻塞其他任务。
针对不同场景使用不同的调度策略:
- 对于负载较高的任务,使用心跳机制来监控任务的执行时间,并设置告警。如果任务超出了规定时间片,会将其下发到后台线程进行执行。
- 对于系统产生的负载,盘古使用TCMalloc(Thread Cached Malloc)缓存来允许在缓存中执行高频率的操作。
优先级调度保障高QoS
盘古对不同请求标注不同的QoS标签(用户请求高优先级,GC请求低优先级)。
USSOS创建了一个优先队列,队列中的任务根据QoS目标来进行调度。以此来防止低QoS任务过多导致高QoS不能被按时完成。
轮询和事件驱动的切换(NAPI)
为了防止频繁发起中断导致高CPU利用率,USSOS使用切换机制。
NIC(Network Interface Controller,网卡)提供了文件描述符fd的监控,基于监听数据达到后的fd事件。
程序默认使用事件驱动,当程序收到了NIC的通知,将切换为轮询模式。如果程序一段时间内没有收到任何I/O请求,将会切换会事件驱动模式并告知NIC。
Append Only USSOS
USSFS使用一系列基于chunk的指令(open,close,seal,format等),支持append-only write。
支持append-only的顺序写入,充分利用了SSD的顺序写和随机读特性。
通过多种机制最大化SSD性能:
- 充分利用独立chunk布局,极大的减少了数据操作的次数,而不需要使用page cache和日志等机制。
- 不需要建立分级的索引机制(例如ext4的inode和文件目录dentries)。所有的操作会通过日志进行记录,该日志可以用来在挂载文件系统时重建元数据信息。
- 使用轮询机制减少中断。
单个SSD的容量一般很大,并且一个chunk的大小通常是64MB,设定USSFS的最小空间分配粒度为1MB,主要考虑使用的内存大小和SSD的空间利用率。
高性能SLA保障
Chasing
减少系统抖动在写延迟上的影响。
当$MaxCopy$个副本中的$MinCopy$个在chunkserver中成功写入时,允许client向应用返回success。
规定 $2\times MinCopy\textgreater\ MaxCopy$。
下图Figure 4展示了Chasing在 $MaxCopy=3\and MinCopy=2$情况下的工作情况:
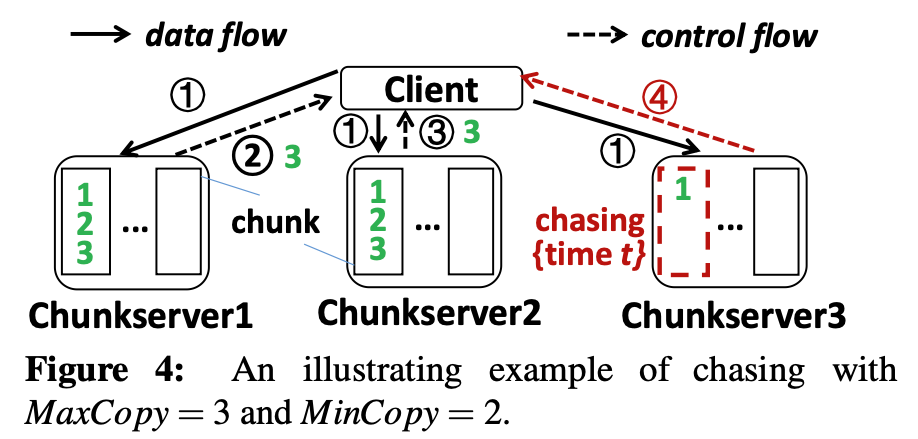
应用程序请求Client写入数据$[1,2,3]$到3个副本chunkserver中,在时间$T$时,chunkserver1和2已经向client返回了写操作success,但是chunkserver3还没有回复。此时Client将向应用程序回复success。
在Client中还需要在内存中保留写入的数据,并等待一个时间段$t$(ms级别),如果chunkserver 3在$T+t$时间以前回复了success,Client就会在内存中删除释放要写入的数据。
如果chunkserver 3没有完成写入操作,且没有完成的部分小于阈值$k$,Client将在chunkserver 3中发起重试操作;若没有完成的部分大于$k$,Client将会在chunkserver 3中封存这个chunk,保证不会收到后续追加写入的影响,Client通知master,master将从chunkserver 1或者2复制一个不同的chunk来保证总共存在3个副本,Client的内存中还有一个副本?。
那么chunkserver 3中封存过的chunk怎么处理?
这种Early- Write- Acknowledgment机制,减少了写入操作的尾延迟,在盘古上部署了十多年,没发生过数据丢失。
Non-stop write 不停写
减少当一个chunk写入失败导致的写入延迟。
当写入失败时,Client🐝封存chunk并且汇报master当前已经成功写入的数据长度,master使用一个新的chunk来继续写入数据。如果写入到封存的chunk中的数据损坏,会在后台使用其他已经成功写入的副本复制到一个新的chunk中。如果没有可用副本,Client将再次写入数据到一个新的chunk。
Backup read
减少动态环境下读延迟。在收到读请求的response前,Client向其他Chunkserver发送额外的读请求作为备份。
该机制涉及两个参数,发送请求的数量和等待时间。
为此,盘古计算了不同硬盘类型和I/O大小的延迟,并使用这些信息动态调整发送备份读取请求的时间。它还限制了备份读取请求的数量,以控制系统的负载。
Blacklisting
为了避免向服务质量差的chunkserver发送I/O请求,盘古使用两个黑名单,确定黑名单和非确定黑名单。
当盘古确定一个chunkserver已经无法提供服务(chunkserver的SSD损坏),这个服务器将被加入确定黑名单。
如果一个chunkserver可以提供服务,但是延迟超过上限,将会被加入非确定黑名单,并设置其服务延迟增加的可能性。
如果chunkserver的延迟超过了所有server延迟的中位数,会将它直接加入非确定性黑名单中,可能性为1.
Client阶段性的向chunkserver发送I/O探测,以便维护非确定性黑名单。
如果在确定性黑名单中的服务器成功返回了response,会将其在黑名单中移除。
对于在非确定性黑名单中的服务器,将会基于response的响应时间来判断。
盘古同时限制黑名单中的服务数量来保证系统的可用性。对于每个服务器而言,这引入了宽限期来维护黑名单保证系统的稳定性。
盘古为RDMA和TCP两种链接分别维护了黑名单。
评估
Figure 5为2018年双十一期间的峰值延迟,在需要进行大量事物处理的情况下,盘古2.0延迟低于280us。
Figure 6为OTS服务的延迟,在相同的请求负载下,盘古2.0的查询延迟接近降低了一个数量级。
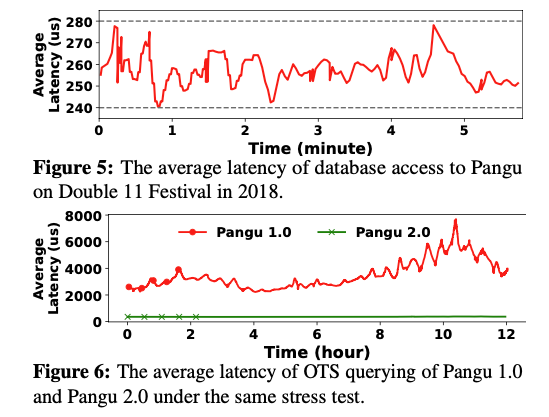
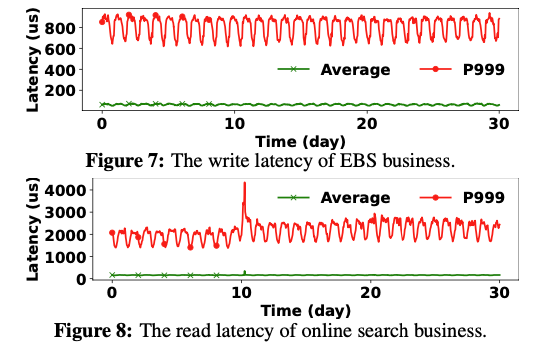
Figure 7、8分别为EBS、在线搜索服务的平均的尾延迟。
EBS服务写入较多,P999尾延迟低于1ms。
在线搜索服务读取较多,P999尾延迟低于5ms。
0x03 Phase Two: Adapting to Performance-Oriented Business Model 适配面相性能的商业模型
网络瓶颈
扩大带宽
为了匹配SSD的吞吐量,将网络带宽从25Gbps升级到100Gbps。
硬件优化:采用高性能的NIC/RNCI网卡、光模块(QSFP28 DAC,QSFP28 AOC,QSFP28)、单模/多模光纤、高性能交换机。
网络软件层:采用有损RDMA,不使用暂停帧。
如果使用无损RDMA,当RDMA网络中暂停帧过多时,要在一段时间内关闭NIC端口或临时切换RDMA为TCP,这种基于流量的控制不能解决由暂停帧引发的其他问题(死锁、头阻塞)。因此盘古使用有损RDMA。
流量优化
减少流量放大率。
流量放大率为系统中所有的流量传输量除以真实的文件大小,如Figure 9:
以EBS服务为例
- EBS Client发送文件(1x)到盘古Client
- 盘古Client将文件传输到3个存储节点,并写入三个副本(3x)
- GC Worker读取文件(1x)并进行GC
- 最终文件以EC(8,3)(1.375x)的形式写回存储节点,保证至少与3个副本同等级别的容错,并节省了空间。
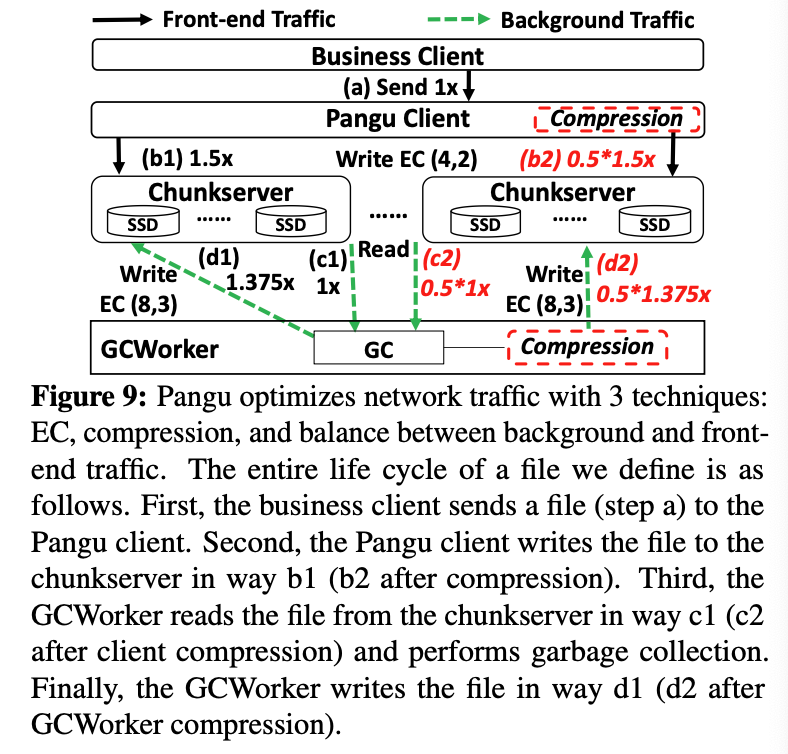
过程中的流量放大率为6.375x(1x+3x+1x+1.375x)。
因此提出了三个优化:
使用EC替换3个副本
在保证良好容错性的情况下,有效降低流量。使用b1中的EC(4,2),可以将流量降低为4.875x。该方法存在两个问题:
- 对于小文件的EC存储开销较大,需要填充大量的0达到规定长度。使用多种机制减少空间浪费。可以对小的写请求进行聚合,并动态切换存储策略(EC、3个副本)
- 计算EC引入了额外延迟,盘古采用Intel ISA-L,将EC计算的延迟相较于Jerasure降低了2.5-3倍
压缩FlatLogFile
FlatLogFile存在高度冗余。盘古Client和GC Worker在进行下一步写入时压缩FlatLogFile,来减少流量。
盘古使用LZ4算法来实现高效的压缩/解压缩。
前后台流量的动态带宽调节
动态调整后台流量(GC等)的网络带宽。
当存储集群中流量空闲时,减少后台流量的限额,使前台应用使用更多的带宽。
内存瓶颈
内存瓶颈来自内存带宽和网卡(NIC 执行DMA)的竞争,以及接受端的应用处理(数据拷贝,复制,gc)。
NIC无法获得足够的内存带宽,使得PCIe的带宽超出NIC的处理能力,NIC buffer中都是在途数据包,导致丢包。
因拥塞控制导致的性能损失会降低30%的网络吞吐量,10%的延迟。
加内存
增加了很多小容量的DRAM(16GB),最大化Memory Channel的利用率,提高每个服务器可用的内存带宽。
使用NUMA来避免跨Sockets内存访问。
TCP to RDMA
TCP使用更多的内存拷贝,使用RDMA后,后台流量的内存带宽减少了75%。
为了保证前端流量的QoS,盘古设计了类似Linux tc频率控制机制,来控制后台流量发送到网络中的速率。
RDCA
使得发送端绕过接收端的内存并直接访问接收端的cache。
该池使用共享接收器队列(SRQ)来接收小消息,
- 缓存驻留缓冲池:使用共享接受队列来接受小信息,并使用基于窗口(类似TCP滑动窗口?)的速率控制机制的READ缓冲区来接收大消息,因此RDMA操作所需的内存缓冲区可以放入缓存中
- 快速缓存回收:为了在少量LLC二级Cache下达到100Gbps NIC线性速率操作,设计两种机制减少数据通过NIC的时间跨度:
- 在一个流水线下平行处理数据
- 通过硬件卸载和轻量化的序列化/反序列化 优化数据处理
- 缓存压力感知的逃逸机制:解决性能抖动,逃逸机制监控LLC的使用并执行响应的策略
- 通过向缓存驻留缓冲池添加一个新的缓冲区来替换掉队数据的缓存缓冲区,这样RDCA中用于适应新到达的请求的可用缓存的大小保持不变
- 如果发生太多替换,则主动将运行缓慢的应用程序的数据复制到内存中,这样其他应用程序可以使用RDCA缓冲池,并且该池不会占用太多缓存
- 让NIC在拥塞通知包中标记显式拥塞通知(ECN),如果复制到内存失败或不足以释放缓存压力,则指示拥塞
CPU瓶颈
数据的序列化和反序列化、数据压缩、数据CRC校验产生了大量的CPU开销
混合RPC
盘古通过Protobuf(Google gRPC)发送RPC请求,该框架需要对数据进行序列化/反序列化,产生了30%的CPU开销。
盘古内部的数据通路只有少量为RPC,因此,为了不需要序列化即可发送数据,盘古使用一种类似FlatBuffer的原生结构取代数据通路操作。
得益于Protobuf灵活性,盘古继续使用Protobuf来进行控制操作。
每个CPU核心的网络吞吐量增加了59%。
使用CPU wait支持超线程
hyper-threading(HT)超线程技术有两个主要问题
- 两个HT在一个无力核心上执行需要上下文切换
- 一个HT影响其他HT的执行,会使整体的延迟升高
盘古提出了CPU wait指令,包括monitor和mwait
例如:网络空闲轮询线程将监控的内存地址,执行mwait,直到内存地址被其他线程修改时才被唤醒。
在mwait过程中,它运行的HT进入空闲睡眠状态(C-States中的除C0之外的一个状态),因此不会干扰其他HT。
执行CPU wait的时间开销小于5ms,唤醒一个HT的开销也是ms级别。
对比没有CPU wait,网络吞吐量提高了31.6%。
软硬件Co-Desgin
将一些任务卸载到可编程硬件。
- 数据压缩:卸载到基于FPGA的可计算存储,达到3GB/s的吞吐量,可以节省10个物理核心。
- CRC计算:卸载到RDMA-总线 NIC网卡,为每个数据块计算CRC,CPU会汇总这些CRC并执行轻量化的检查,保证了CPU的低负载和上层应用的数据集成。节省了30%的CPU开销。
评估
标准化的有效吞吐量:
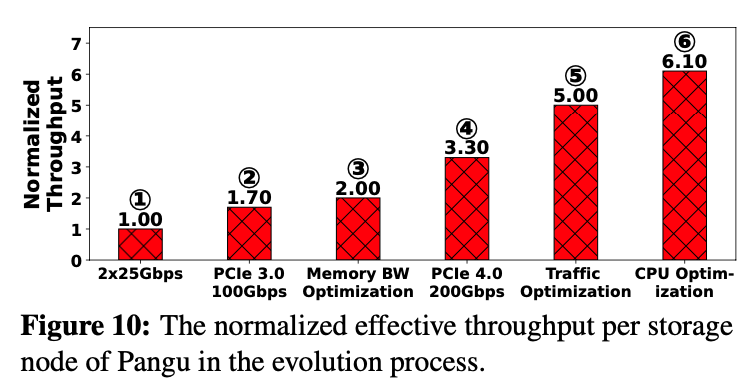
从左到右:
- 盘古使用2*25GBps网络带宽和4TB-SDD
- SSD增加到更高性能的8TB,使用100Gbps网络(PCIe gen3)
- 优化了内存带宽
- 使用PCIe gen4,网络带宽增加到2*100Gbps,存在流量放大问题。
- Client采取EC(4,2),数据压缩等优化缓解了流量放大问题
- 卸载数据压缩和CRC到外置硬件
0x04 Operation Experiences
介绍了在开发运营过程中遇到的一些案例研究
0x05 Lessons
- user-space system:
- 在user space开发节省人力并且容易监控和调整参数
- user space开发需要学习kernel space开发
- 独立chunk布局还优化了HDD的写入效率
- tradeoff:成本和性能的平衡,提高资源利用率
- PMem:Intel放弃了PMem的业务
- hardware offloading:付出了大量成本解决这一问题,收益明显
0x06 Conclusion
文章介绍了盘古从1.0版本到2.0版本的整体演进过程,有非常大的实战经验,给出了对于分布式文件系统、面向性能的服务模式、CPU瓶颈、内存带宽的实现方案。文章个别地方没有很详细的描述,阿里云团队也发表过多篇学术论文,本文还是总结为主。