
[ATC'20] PinK: High-speed In-storage Key-value Store with Bounded Tails
0x00 Everyday English
preferable 更可取的
consequently 因此
inevitably 必然的
conventional 常规的、传统的
exacerbates 加剧
deteriorates 恶化
deterministic 确定性
0x01 Intro
本文主要提出了Pink,基于LSM tree的KV-SSD,主要通过避免使用布隆过滤器,而是使用少量DRAM来进行优化
传统的KV-SSD主要通过在控制器的DRAM中维护一个hash table来寻址,受到DRAM的容量限制,超出容量的部分会暂时存放在闪存中,因此在寻址时带来了访问闪存的额外开销,同时当发生哈希碰撞时,可能会操作多个闪存,造成了大量不可预测的开销
单纯使用LSM做为替换的话,可以减少DRAM的存储,但是存在一些性能问题:
- 尾延迟:很多LSM-tree使用布隆过滤器来快速检索,可靠性差,存在尾延迟问题
- 写放大:由于LSM对KV索引的排序和合并操作,带来了很多对闪存额外的访问,还增大了FTL进行GC的负担
- 布隆过滤器的重建和KV排序:消耗了大量的CPU资源,带来I/O性能的大幅下降
本文提出了一种基于LSM-tree的KV存储引擎-PinK,解决了上述三个问题。PinK使用了四种技术。
-
PinK的核心是level pinning,将固定在LSM-tree最顶层的KV索引固定到DRAM中
-
由于部分level固定在DRAM中,因此可以直接进行compaction,无需占用闪存的I/O,被固定的索引通过电容进行保护,因此也不需要定期进行刷新,这里要注意作者使用DRAM容量很小,使用电容足以保证持久化
-
GC的主要I/O开销来自对LSM-tree索引的更新,Pink通过延迟LSM-tree中索引更新到compaction阶段来减少GC的I/O开销
-
在SSD控制器和NAND芯片之间添加比较器,PinK在读取KV对象时执行KV排序,完全消除了compaction的CPU成本
0x02 Bg
了解一些有关NAND闪存SSD、KV-SSD、Hash-based KV-SSD、LSM-Tree-based KV-SSD的现状,并对Hash和LSM-tree进行比较
作者对LSM-tree的设计,L0位于DRAM中,并作为write buffer,其余各层存储在闪存中
0x03 Design
Pink有四个主要的数据结构
位于DRAM中的level lists和Skiplist
位于闪存中的meta segments和data segments
在LSM-tree KV 文件系统方面,作者主要参考了WiscKey FAST'16,取代FTL进行GC、索引和磨损均衡
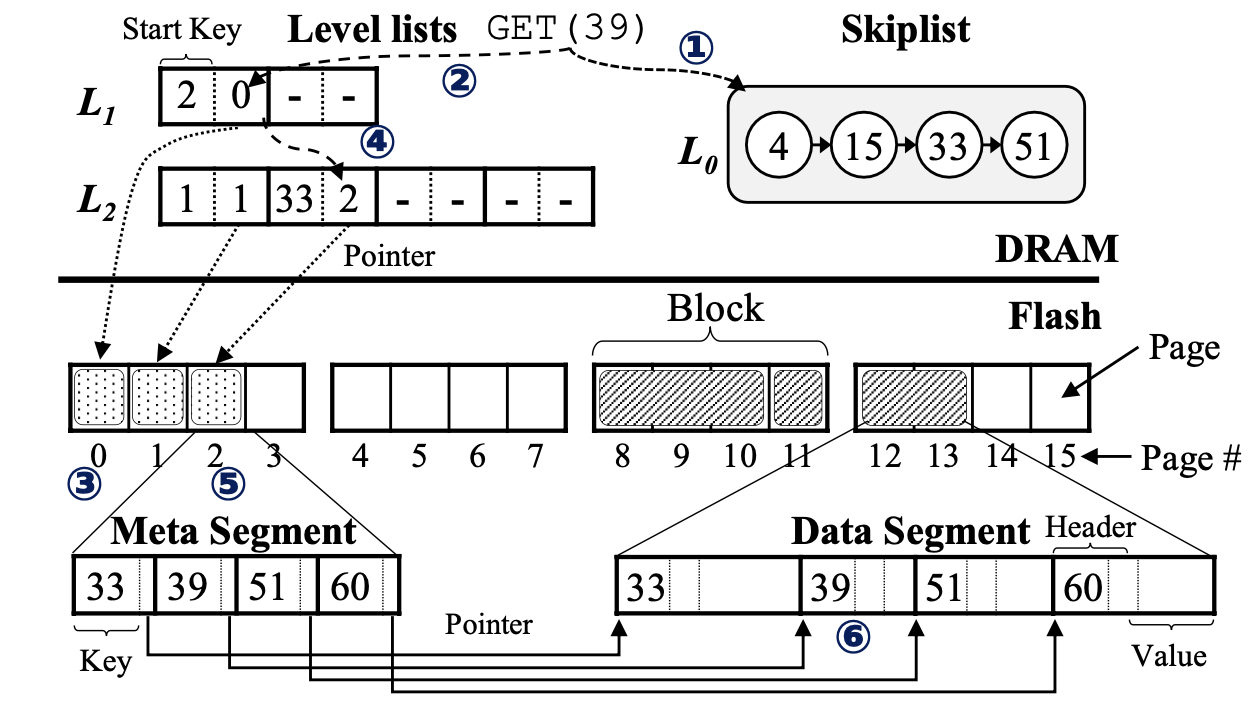
Skiplist
Skiplist作为LSM-tree中的L0,起到类似write buffer的作用,暂时保存KV对象,Skiplist中的对象为:<key size, key, value size, value>
当Skiplist满时,会将缓存的对象以meta segment和data segment的形式刷新到L1中,在L1和更低的level中,Key和Value将被分离存储到meta/data segment中,data segment中存储value、key和key size用于GC
Level list
用于跟踪闪存中每个level的meta segment
每个level list是一个保存固定大小的指针对的数组,每个指针4B,第一个指针指向meta segment在闪存中的物理地址,第二个指针指向meta segment的start key
meta segment的start key单独存储在DRAM中,可以支持动态大小的key,同时可以实现在level list查找meta segment时进行二分查找
如果LSM-tree有5个Level,即h=5,除了L0之外,每个level都会有一个level list
L0和Level list通过电容来保护,Pink不需要使用日志来维护原子性和数据的持久性
Level Pinning
消除尾延迟,将$top-k\ \ level(k<=h-1)$ 的meta segment保存在DRAM中,减少了read过程的尾部延迟
当处理GET指令时,首先在DRAM中对Key进行查找,当DRAM中没有命中时,将对剩余的几个level在闪存中进行查找,在使用布隆过滤器时,最坏的查询时间复杂度为$O(h-1)$,该策略下可以优化为$O(h-k-1)$
因此LSM-tree各level按照参数T进行增长,因此topk策略下空间占用不会过大
同时可以直接在DRAM中进行compaction操作,无需占用闪存I/O,因为有电容的存在,无需定期刷新脏segment到闪存中
Optimizing Search Path
在对Key进行查询时,LSM-tree将对各个Level进行二分查找
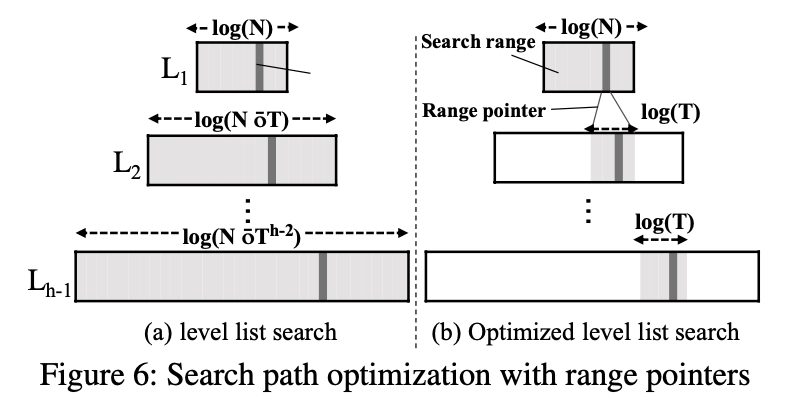
朴素的LSM-tree最坏的查询时间复杂度为$O(h^2\cdot log(T))$,使用布隆过滤器的情况下可以更低
-
PinK通过prefix来减少字符串比较的开销,并且先比较key的前4个字节,如果匹配成功才会比较后面的部分
-
在level list上每个记录引入一个4字节的范围指针,实现多级cascading范围查找
指针指向下一级有最大的start key同时key 小于等于上一级中的记录,在一级一级的传递中不断减少搜索的范围,如上图b所示,平均时间复杂度为$O(h\cdot log(T))$
Speeding up Compaction
在compaction阶段,引入一个硬件加速器,位于闪存和数据主总线之间,可以方便的合并两个闪存中的level
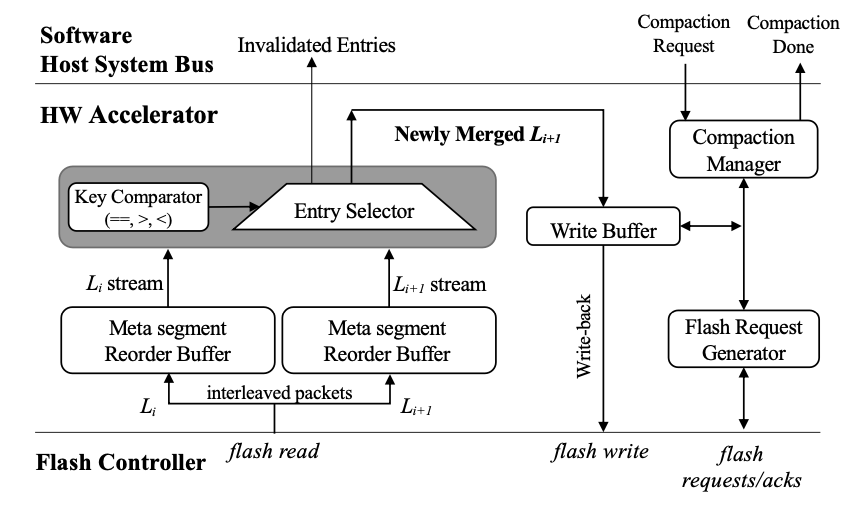
工作流程:
-
PinK向加速器发起compaction请求,请求参数为:
- 两个level的meta segment的闪存地址$(L_i,L_{i+1})$
- 回写的闪存地址$L_{i+1}$
-
向多个闪存发起读取请求,同时还要对不同channel返回的数据进行重新排序,序列化meta segment
-
上图中灰色的比较器,会不断的获取两个level中的数据,输出key较小的那一个
-
对于无效的key,将通知PinK进行GC
-
输出的排序后结果将保存在write buffer中进行回写
-
操作结束后,加速器通知PinK当前$L_{i+1}$使用的闪存页的数量,便于和此前提供的进行比较,用于GC
PinK在DRAM的pinned level中也使用了类似的加速器,基于DMA
Optimizing GC
需要针对meta/data segment分别制定GC策略
Durability && Scalability
使用电容来保护整个DRAM,对于比较低端的SSD,没有足够的电容来维持,只能继续使用定期写回到闪存的机制(要保护level lists,pinned level,L0),同时还要记录日志,由于LSM-tree的特性,该操作比基于hash的KV-SSD开销略小
Conclusion && Thinking
- 与之前阅读的KV-SSD相比,PinK将部分Level固定到DRAM中,一定程度上降低了延迟
- PinK弃用了布隆过滤器,使用一种层级缩小查找范围的方式,优化查询效率
- 引入了一个加速器来减少LSM-tree compaction操作的开销
- 论文都提高了布隆过滤器使用时重建的开销略高,是否可以考虑使用布谷鸟过滤器,这部分主要着眼于LSM-tree的优化,可能并不是真正的性能瓶颈