
[OSDI'22] XRP: In-Kernel Storage Functions with eBPF
0x00 Intro
随着超低延迟SSD的发展,I/O过程中来自内核的延迟比重不断升高。
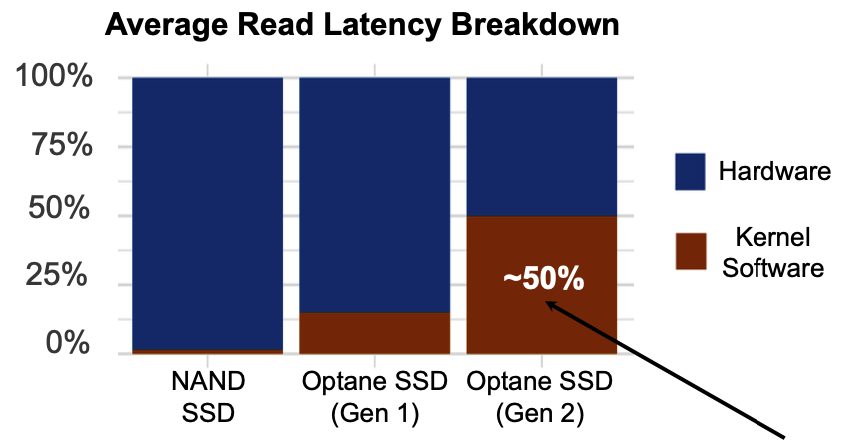
观察一个请求的从发起到完成的整个过程,内核部分占据了48.6%的延迟。
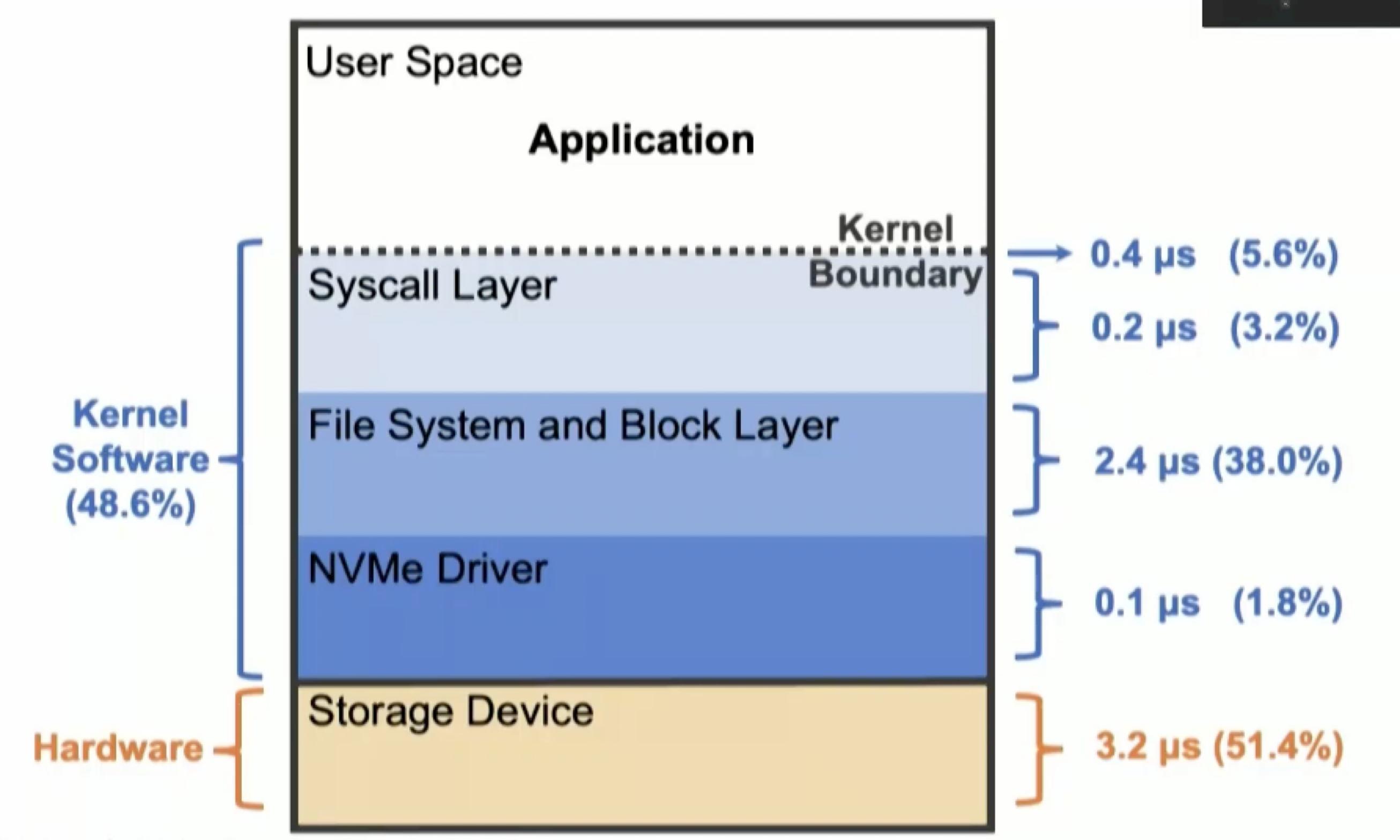
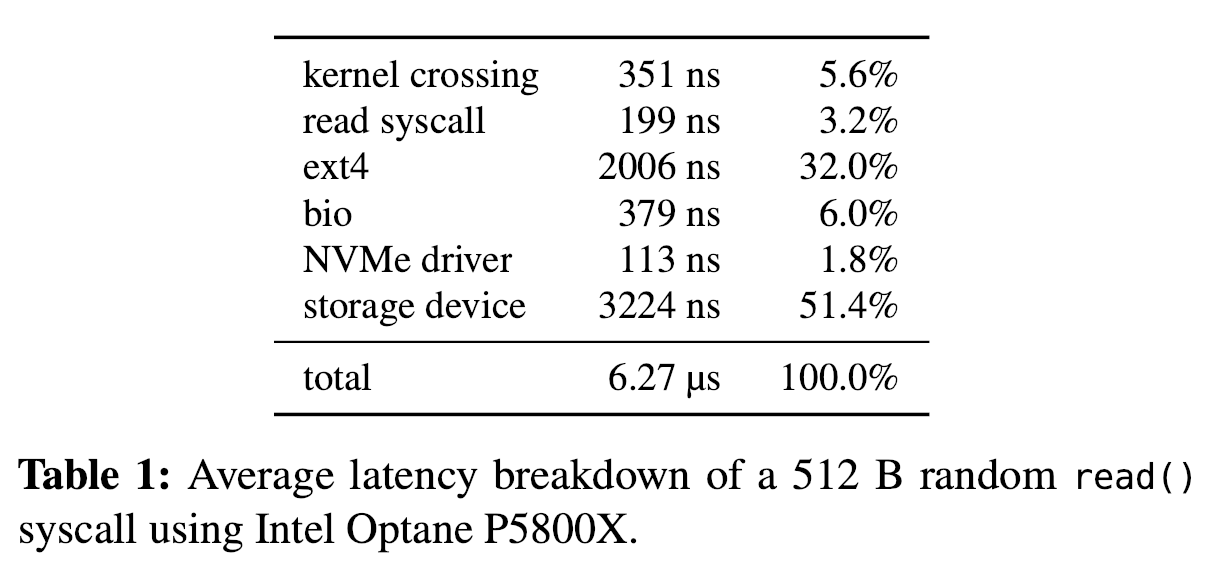
因此可以考虑跳过内核中一系列的数据传递,即Kernel Bypass。目前现有的研究大都对内核进行了激进的修改策略,或引入了新的硬件,Kernel Bypass主要使用SPDK,直接对硬件设备进行访问,而SPDK会强制开发者实现自己的文件系统,需要自行维护隔离性和安全性。
在等待I/O完成时,往往会进行轮询,给CPU带来了一些性能损失。有研究表明当可调度的线程数量超过了CPU核心数量时,使用SPDK会提高平均延迟和尾延迟,严重降低了吞吐量。
因此作者的核心思想为既可以完成Kernel Bypass,也不需要引入额外硬件并不对内核和文件系统进行很大的修改,作者借助BPF(Berkeley Packet Filter)来实现,BPF允许应用程序下放部分工作到内核中,同时还能保证隔离性,允许多线程共享一个CPU核心,提高利用率。
许多I/O负载需要多次调用函数访问硬盘上的大型数据结构(B+ tree),作者称之为resubmission。
作者提出了eXpress Resubmission Path,XRP在NVMe驱动中的中断处理器上添加了一个hook,使得XRP可以在I/O完成时直接从NVMe驱动层来发起BPF函数调用,快速启动I/O的重新提交。
XRP的主要贡献为:
- 首次使用BPF来卸载I/O任务到内核
- 将B-tree的查找吞吐量提高了2.5倍
- XRP提供了接近Kernel Bypass的延迟,而且允许线程和进程高效地共享CPU核心
- XRP适用于多种不同用例,支持不同类型数据结构以及存储操作
0x01 Bg && Motivation
I/O是目前的瓶颈
时间都去哪了
作者通过实验发现延迟的部分来源是软件层面,即系统内核部分中block I/O的传递
为什么不单纯的kernel bypass
大部分bypass的方法都是直接对NVMe driver发起请求,此类方案不能实现细粒度的隔离或者再不同应用之间共享数据,同时不能有效的去接收I/O完成产生的中断,需要应用不断轮询,因此CPU就被某个应用独占,不能得到共享。而且当多个轮询线程共享一个CPU处理器时,他们之间对CPU的竞争同时缺少同步会导致尾延迟升高和吞吐量的降低。
BPF
Berkeley Packet Filter允许用户将一些简单函数下放到内核层来执行,起初是用于TCP的数据包过滤、负载均衡、数据包转发,目前推出了eBPF扩展。
BPF可以验证函数的安全性,主要检查是否超出内存地址空间、是否有死循环、指令是否太多。
BPF可以直接发起一系列I/O请求,来获取那些不被程序直接利用的中间数据,例如指针寻址过程,B-tree索引便利。
一些在硬盘维护并且使用指针来查找的数据结构,例如LSM tree,可以用于加速查找的过程。
有研究对比了分别从User Space、Syscall、NVMe Driver层发起I/O之间吞吐量和延迟的差异。

在NVMe Driver中发起I/O有效提高了吞吐量降低了延迟,原因是越靠近存储设备的一层,总体的延迟和性能越高。因此XRP选择在NVMe Driver层来实现。
io_uring
io_uring是Linux的一个系统调用,可以批量提交异步I/O,并且相较于aio减少了系统调用的次数,作者通过实验验证了在NVMe Driver层提交I/O也可以提高io_uring的性能。
0x02 Challenges && Principles
Challenges
- 地址转换和安全问题:NVMe Driver不能访问文件系统的元数据,因此不能完成逻辑地址到物理地址的转换;BPF可以访问其他文件和用户的任何block。
- 并发和缓存问题:对于从文件系统发起的并发读写很难维护。从文件系统发出的写请求将写入到page cache中,对于XRP不可见;同时对于硬盘上数据结构布局的修改,例如改变某一个指针,将会导致XRP获取到错误的数据,虽然可以进行加锁,但是从NVMe中断访问锁的开销太大。
Observation
作者研究发现,大部分的存储引擎的硬盘数据结构都是稳定的,或不会进行就地更新。
例如在LSM-tree中,进行索引的写入操作,写入到文件SSTables中,这些文件为不可变,直至其被删除,不可变文件还降低了文件并发访问的成本。B-tree的索引虽然可以就地更新,但是在实际测试中(24小时YCSB读写改实验)发现,索引的修改次数很少,因此也不需要在NVMe Driver中频繁的更新文件系统的元数据。
同时,索引一般存储在少量的大文件中,并且每个索引不会跨越多个文件。
Design Principles
- 一次只访问一个文件:可以简化地址转换和访问控制,还最小化了需要传递给NVMe driver的元数据
- 面向于稳定的数据结构:XRP以不会频繁更新的数据结构为目标RocksDB、LevelDB、TokuDB、WiredTiger,不支持需要锁来访问的数据结构
- 用户管理缓存:XRP无法直接访问Page Cache,因此如果block位于Page Cache中,XRP函数不能安全的并发执行,而大多数存储引擎都是在用户空间自行管理Cache。
- 错误处理:如果访问失败(映射信息过期),需要程序在用户空间重试或回滚。
0x03 Design && Implementation
XRP的架构图:
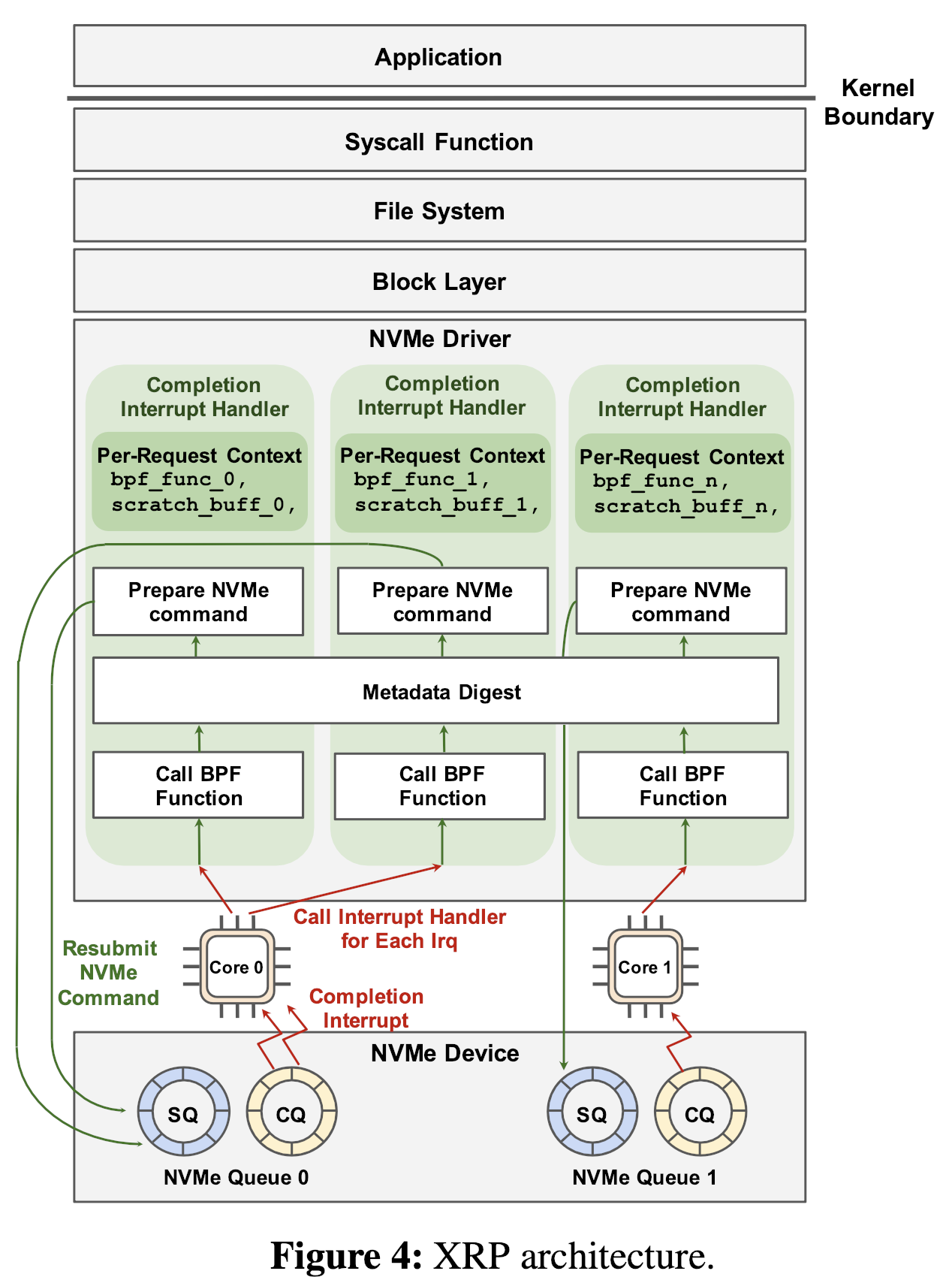
Resubmission Logic
XRP的Resubmission主要包含3个部分:
- BPF hook
- 文件系统地址翻译
- NVMe请求的构建和提交
当NVMe指令请求完成后,设备发起中断使内核发生上下文切换执行中断处理,对于在中断上下文(即ISR中断处理程序保存的请求发起程序的上下文)每个NVMe请求,XRP调用相关的BPF函数,即上图的bpf_func_0,该函数指针存储在内核I/O请求的结构体中(bio)。
在调用BPF函数后,XRP调用元数据信息摘要,此文件系统摘要用于做地址转换。
最终,XRP发起下一次NVMe请求,将请求append到相应CPU核心NVMe的SQ中完成resubmission(如上图所示)。
BPF Hook
XRP引入BPF_PROG_TYPE_XRP作为BPF函数的签名(函数签名一般包括函数的参数类型、个数等),符合该签名的程序可以被BPF Hook调用。

参数解释:
data:存储从硬盘中读取的信息(例如B-tree Page),可以被BPF函数解析done:在resubmission阶段通过此字段判断是否将数据上报给用户程序,或是进行后续I/Onext_addr:表示下一次resubmission要请求的逻辑地址,最大输入量fanout默认限制在16size:表示next_addr逻辑地址的大小,某些情况下可以将其设置为0表示不发起I/Oscratch:对于用户和BPF函数私有,用于向BPF函数传递用户的参数,BPF函数也可以在此存储两次I/O之间的中间变量,亦或是保存传递给用户的数据。相当于BPF可以利用的一个4KB的buffer。如果BPF函数需要更大的空间,还可以使用BPF maps
BPF上下文对于一个NVMe请求是私有的,不需要考虑加锁。为用户提供scratch buffer避免了调用bpf_map_lookup_elem来访问buffer产生的开销。
BPF Verifier
BPF校验器通过追踪寄存器中value的语义来保证内存安全。
一个有效的value既可以是一个标量也可以是一个指针。
SCALAR_TYPE表示一个不能被指针取值(cannot be dereference)的value。
verifier定义了多种指针类型。
每个BPF函数都定义了一个回调函数is_valid_access()来检查上下文访问是否正确并返回上下文中value type字段。
PTR_TO_MEM表示一个指向固定内存大小的指针,支持直接通过offset取值(不超过边界的情况下),BPF_PROG_TYPE_XRP的data和scratch字段通过PTR_TO_MEM访问,其余部分则为SCALAR_TYPE。
is_valid_access()还可以用来传递data/scratch buffer的大小,用于做边界检查。
Metadata Digest
为了完成在NVMe Driver中的地址转换,XRP在文件系统和中断处理程序之间添加了一个接口。文件系统共享逻辑地址到物理地址的映射。
元数据摘要共有两个函数,如下图所示。
当地址映射被更新时,文件系统将调用update函数。
中断处理程序则负责调用lookup函数,通过接收到的inode地址,给出offset和长度获取地址映射;lookup中也会有越界检查来保证安全性。

当检测到不合法的逻辑地址,XRP将立即返回错误代码到用户空间。
作者在ext4文件系统的实现中,元数据摘要来自缓存中的extent status tree,使用RCU机制进行并发控制。
-
太长不看:
RCU是一种类似于COW写时复制的机制,因为读取操作不需要加锁,在保证数据一致性的同时可以保证高性能,RCU主要用于Linux内核中对高并发访问数据结构的优化,而写时复制主要用于内存管理、文件系统等领域。
-
Linux RCU:
Linux RCU(Read-Copy-Update)是一种用于管理并发访问共享数据结构的技术。它是一种无锁并发机制,允许多个线程同时读取共享数据,而不需要互斥锁或读写锁等传统的同步机制,从而提高了并发性能和可伸缩性。
RCU的基本思想是,当一个线程需要更新共享数据时,它将数据复制一份,并在副本上进行修改,而不是在原始数据上进行修改。其他线程仍然可以访问原始数据,直到更新完成。在更新完成后,新的数据副本将替换原始数据,并且RCU机制将确保在该更新之前任何已经读取的数据都不会丢失。
RCU适用于高并发访问数据结构的场景,例如哈希表、链表和树等数据结构。它已经被广泛应用于Linux内核中,使得Linux内核在多处理器系统上的性能得到显著提升。
ext4中,extents扩展块是文件系统中一段连续的块,一般用于存储大文件的数据信息。
为了保证缓存数据与ext4中的extents一致,update函数会在extents发生修改或者删除时调用。同时为了防止竞态,为每个扩展块维护了一个版本号。
在数据读取后,但还没有传递给BPF函数之前,会先调用元数据摘要的查找。如何相应的extents已经被删除或者当前版本号已经落后,XRP将中断此次操作。
一般而言,为保障安全和正确性,在程序之间进行同步时就会对文件中一个部分的加锁,因此版本号的改变大多来自于恶意修改或程序出错。
一种更简单的实现利用ext4文件系统现有的extent tree更新和访问函数来获取元数据摘要,这会保证ext4中的extent tree时刻是最新状态,但是在查找ext4中extent查找函数会获取自旋锁,对于中断处理程序带来了极大的开销,因此不太合适。
目前XRP仅支持了ext4文件系统。对于F2FS可以直接利用存储了逻辑物理地址块映射的Node Address Table(NAT),通过保存一个NAT的副本来得到元数据摘要。每次更新NAT都调用update_mapping。
Resubmitting NVMe Request
在查询到数据块的物理地址后,XRP将准备提交NVMe请求。
XRP重复利用刚刚完成的NVMe请求结构,修改NVMe请求中的物理扇区和块地址为通过lookup函数查询到的偏移量,然后继续进行请求。
由于bpf_xrp支持的最大地址个数为16,目前的resubmit只能获取到和初始NVMe请求一样多的物理段。也就是第一个NVMe请求只申请了一个物理段,那么后续的NVMe请求也只能去获取一个物理段。
XRP会中断包含无效地址的BPF调用,可以在第一次I/O中next_addr中设置16个伪NVMe指令,以保证后续的请求可以有足够的访问空间。
Synchronization Limitations
BPF目前只支持自旋锁进行同步。
Verifier只允许BPF程序一次只获取一个锁,并且在函数退出前要将其释放。
用户程序不需要直接去访问BPF的自旋锁,可以直接进行BPF的系统调用,该系统调用可以在持有锁时对保护的数据结构进行读写。
需要在多个读写操作之间进行同步的复杂操作在用户空间无法完成。
用户可以通过BPF的原子操作实现自定义的自旋锁,这允许BPF函数和用户程序直接获取任何自旋锁。然而BPF函数的行为会被限制,防止无限地等待某一个自旋锁。
另一种同步方法就是RCU。XRP BPF都运行在NVMe中断处理程序上,而中断处理程序不能被抢占,可以认为他们已经进入了RCU读端临界区(a RCU read-side critical section)的状态,因为在中断处理程序执行时,其他任务无法访问共享数据结构,从而避免了并发冲突。因此,在这种情况下,BPF程序不需要获得锁来读取共享数据结构,从而避免了锁的开销,并提高了程序的执行效率。
Linux Schedulers
进程调度
作者研究发现根据Linux的CFS完全公平调度算法,当计算密集型的进程和I/O密集型的进程运行在一个核心时,由于超低延迟SSD的中断过于频繁,使得I/O密集型应用产生的I/O中断占用大量时间片,导致计算密集型进程的饥饿。而在普通SSD上,由于中断产生的频率较低,不会发生此现象。
连续产生中断较多的XRP、网络中断较多的程序会加剧(exarcerbates)此问题,作者计划在之后考虑此问题。
I/O调度
NVMe默认使用noop调度器,如果需要公平调度,可以开启硬件队列总裁。
0x04 Case Studies
Use XRP
用户调用下图两个接口来加载BPF函数。
bpf_prog_load:加载BPF_PROG_TYPE_XRP类型的BPF函数read_xrp:将调用BPF函数应用到一个具体的请求上

具体的使用实例,作者给出了两个示例。
BPF-KV
作者使用B+树在磁盘组织数据,同时自行维护DRAM Cache来对块和对象进行索引。
最大请求数量限制为31,保证可以遍历一个节点的所有31个孩子。
BPF函数用于查找KV对,首先获取在scratch buffer中的查询目标key,并线性地在node中查找。
使用read_xrp来实现read系统调用,BPF-KV首先为scratch buffer分配一块空间,并计算出offset来启动read。

BPF-KV支持范围查询,查询过程中的数据保存在scratch buffer中。
BPF-KV支持SUM、MAX、MIN此类操作
WiredTiger
WiredTiger是MongoDB的默认存储引擎,可以使用LSM-tree作为数据结构,数据保存于LSM的不同level之间,每个level保存在一个文件中,没个文件使用B-tree索引。所有的文件为只读,更新和插入操作先写入如buffer中,buffer空间不足时保存到一个新的文件中。
XRP只针对read操作做优化,update和insert在buffer中维护。
WT的BPF函数和BPF-KV差不多,WT需要对B-tree的Page做解析操作。
0x05 Thinking
XRP是OSDI'22的best paper,文章整体的工作量非常大,修改了ext4文件系统、BPF模块,并设计了优化后的KV存储引擎。文章从很新颖的角度优化了数据库引擎等I/O密集型应用,不需要频繁传递数据于用户空间和NVMe Driver时间,也减少了I/O过程中在轮询时的开销,提高了CPU利用率,通过BPF这一内核特性可以实现自定义I/O函数,同时保证一定的安全性和隔离。